Previsão de Lucro com Python e Scikit-learn

Neste post vamos mostrar um projeto simples de previsão de lucros de uma indústria de sorvetes conforme a temperatura, vamos utilizar regressão linear e analisar se conforme for mais quente as pessoas consomem mais sorvetes. O algoritmo foi desenvolvido na plataforma Google Colab.
Mas antes de tudo, vamos ver o que é regressão linear.
A regressão linear é definida como um algoritmo que fornece uma relação linear entre uma variável independente e uma variável dependente para prever o resultado de eventos futuros. É um método estatístico usado em ciência de dados e aprendizado de máquina para análise preditiva.
A variável independente também é a variável preditora ou explicativa que permanece inalterada devido à mudança em outras variáveis. No entanto, a variável dependente muda com as flutuações na variável independente. O modelo de regressão prevê o valor da variável dependente, que é a variável resposta ou resultado que está sendo analisada ou estudada.
Assim, a regressão linear é um algoritmo de aprendizagem supervisionada que simula uma relação matemática entre variáveis e faz previsões para variáveis contínuas ou numéricas como vendas, salário, idade, preço do produto, etc.
Este método de análise é vantajoso quando pelo menos duas variáveis estão disponíveis nos dados, como observado na previsão do mercado de ações, gestão de carteiras, análise científica, etc.
Principais Benefícios da Regressão Linear
1 – Fácil Implementação
O modelo de regressão linear é computacionalmente simples de implementar, pois não exige muitos gastos de engenharia, nem antes do lançamento do modelo nem durante sua manutenção.
2 – Interpretabilidade
Ao contrário dos modelos de deep learning, a regressão linear é relativamente simples. Como resultado, este algoritmo está à frente dos modelos de caixa preta que não conseguem justificar qual variável de entrada faz com que a variável de saída mude.
3 – Escalabilidade
A regressão linear não é computacionalmente pesada e, portanto, ajusta-se bem em casos onde o escalonamento é essencial. Por exemplo, o modelo pode ser bem dimensionado em relação ao aumento do volume de dados (big data).
4 – Ideal Para Configurações Online
A facilidade de cálculo desses algoritmos permite que eles sejam utilizados em ambientes online. O modelo pode ser treinado e retreinado a cada novo exemplo para gerar previsões em tempo real, ao contrário das redes neurais ou das máquinas de vetores de suporte que são computacionalmente pesadas e exigem muitos recursos de computação e tempo de espera substancial para retreinar em um novo conjunto de dados. Todos esses fatores tornam esses modelos de computação intensiva caros e inadequados para aplicações em tempo real.
Os recursos acima destacam porque a regressão linear é um modelo popular para resolver problemas de aprendizado de máquina da vida real.
Depois de explicado, vamos implementar:


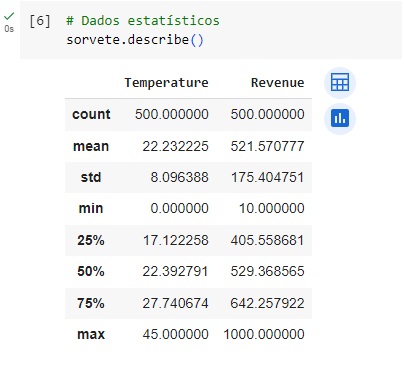
Observando graficamente a base de dados, percebemos que é uma base de dados linear, ou seja, quanto maior a temperatura, maior será o consumo de sorvetes.



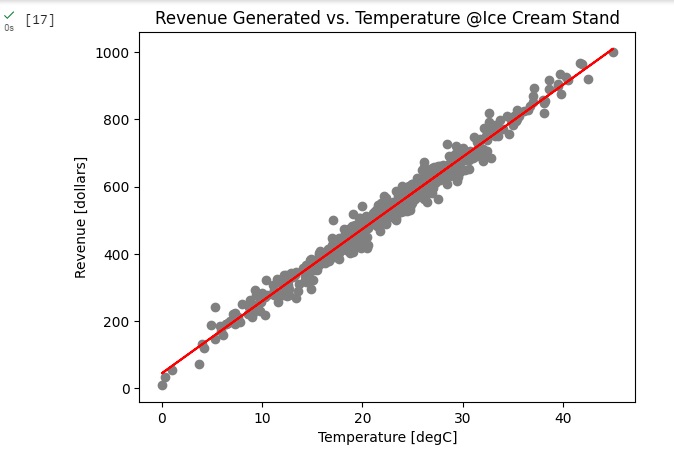
No gráfico gerado abaixo, percebemos através da linha vermelha que a algoritmo entregou resultados satisfatórios.

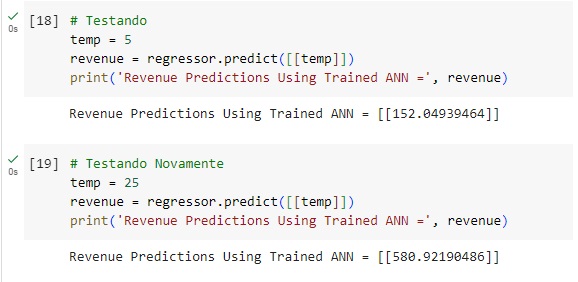
Vamos comprovar os resultados mostrados no gráfico testando com valores, testamos com 5 graus e com 25 graus e confirmamos a linearidade, ou seja, quanto maior a temperatura, maior será o consumo e consequentemente maior será o lucro.