Modelo Preditivo Censo Usando Random Forest

Neste projeto usaremos uma base de dados do censo dos EUA, onde iremos verificar as pessoas que ganham mais ou menos de 50.000 dólares. O código foi desenvolvido na plataforma Google Colab e foi utilizado o algoritmo Random Forest. Antes de mostrar a implementação passo a passo, vamos entender um pouco sobre este algoritmo de machine learning.
O Que é o Random Forest?
É um algoritmo de aprendizado de máquina supervisionado poderoso e versátil que cresce e combina várias árvores de decisão para criar uma “floresta”. Ele pode ser usado para problemas de classificação e regressão em R e Python.
A lógica por trás do modelo Random Forest é que vários modelos não correlacionados (as árvores de decisão individuais) têm um desempenho muito melhor como grupo do que sozinhos, pois ao usar o Random Forest para classificação, cada árvore dá uma classificação ou um “voto”. A floresta escolhe a classificação com a maioria dos “votos”. Ao usar usá-lo para regressão, a floresta escolhe a média dos resultados de todas as árvores.
A chave aqui reside no fato de que há baixa (ou nenhuma) correlação entre os modelos individuais, isto é, entre as árvores de decisão que compõem o modelo maior do Random Forest. Embora as árvores de decisão individuais possam produzir erros, a maioria do grupo estará correta, movendo assim o resultado geral na direção certa.
O benefício mais conveniente do Random Forest é sua capacidade padrão de corrigir o hábito das árvores de decisão de se ajustarem demais ao seu conjunto de treinamento. Usar o método de ensacamento e a seleção aleatória de recursos ao executar esse algoritmo resolve quase completamente o problema de sobreajuste, o que é ótimo porque o sobreajuste leva a resultados imprecisos. Além disso, mesmo que faltem alguns dados, o Random Forest geralmente mantém sua precisão. Dito isto, vamos para a implementação:
Vamos começar importando as bibliotecas:
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Time – para funcionalidades referente ao tempo.


Observando o shape notamos que a base de dados possui 32561 linhas e 15 colunas.

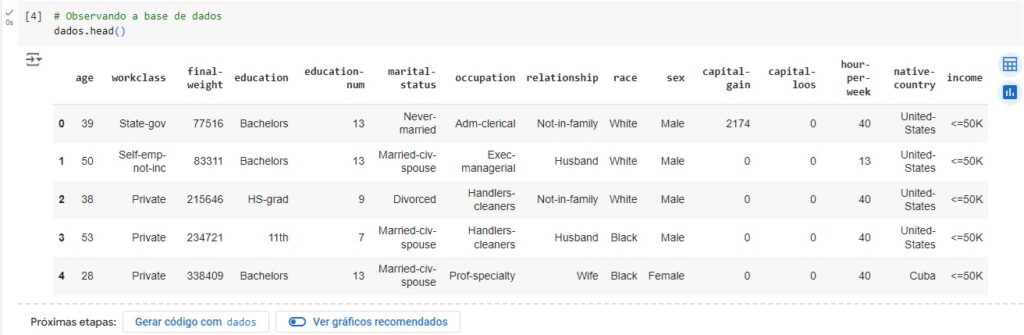
Observando a base de dados.
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão, vemos que a média de idade é 38 anos, a média de anos que as pessoas estudam é 10 anos, vemos que a pessoa mais nova tem 17 anos e mais de velha tem 90 anos. Também podemos notar que os dados estão em diversas escalas, logo mais iremos padronizar estes dados.

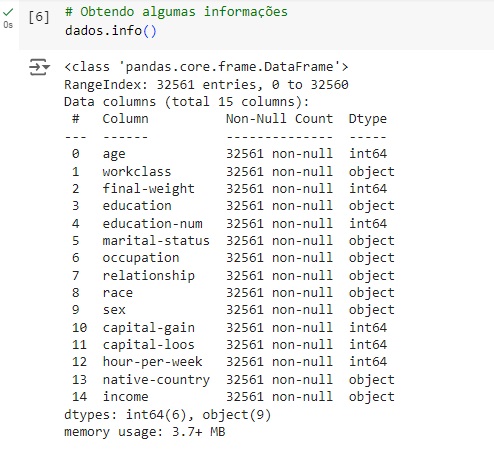
Com a ajuda do comando info(), obtemos algumas informações informações e percebemos que existem variáveis do tipo object, que mais adiante serão tratadas.
Verificando os valores nulos e contando os mesmos utilizando o comando isnull().sum(). Podemos observar que não existem valores nulos no banco de dados.
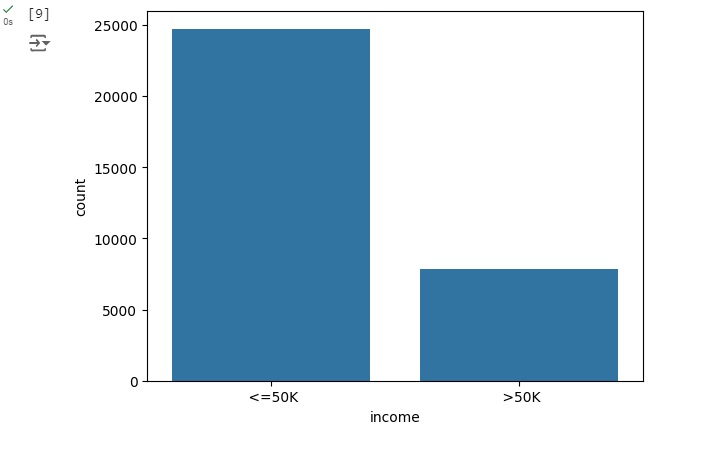
Vamos contar os registros da nossa variável target (alvo), percebemos que temos 24720 pessoas que ganham um salário < = 50k e 7841 que ganham um salário > 50k.

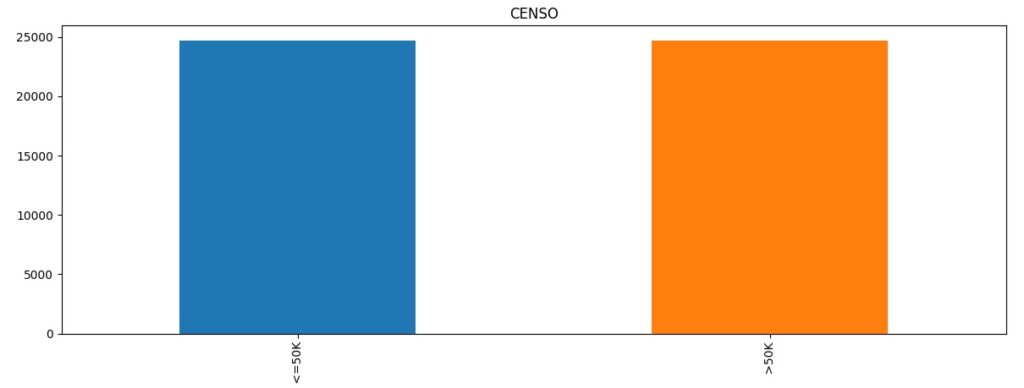
Observando graficamente percebemos o desbalanceamento da base de dados, pois temos uma quantidade muito maior de pessoas que ganham salário < = 50k.

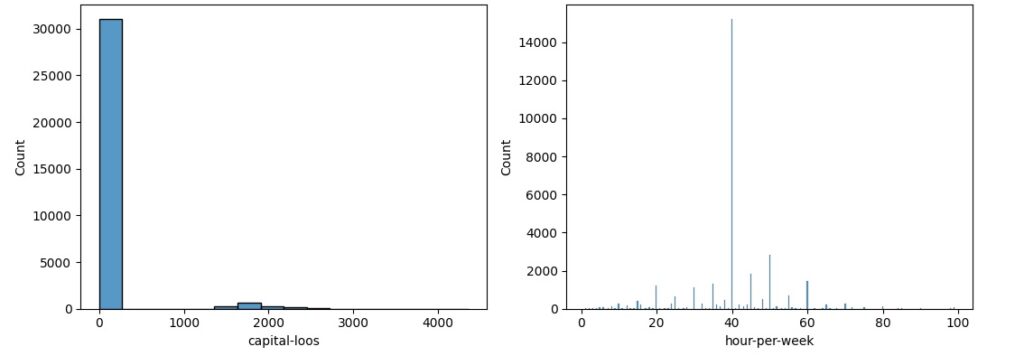
No histograma podemos observar que em torno de 6000 pessoas têm entre 40 e 50 anos e que grande parte possui entre 17 e 50 anos e a minoria têm entre 70 e 90 anos.

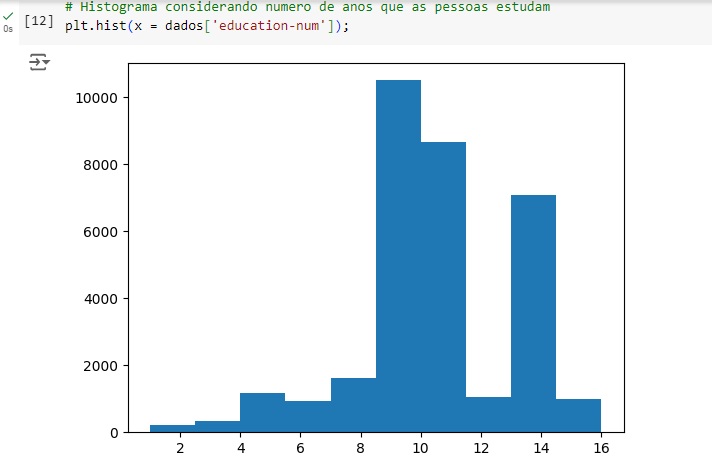
Com este histograma notamos que mais de 10000 pessoas estudam entre 8 e 10 anos, cerca de 9000 pessoas estudam 11 anos e 7000 estudam entre 13 e 15 anos.
Observando as horas trabalhadas, vemos que a grande maioria, no caso mais de 17500 pessoas trabalham entre 30 e 40 horas semanais.

Gerando um gráfico dinâmico, onde percebemos pessoas com 23, 30 e 34 anos que trabalhan no setor privado, como mostra a parte azul do gráfico, na parte verde escuro vemos pessoas de 41, 42, 4 anos que trabalham para o governo e assim por diante.




No gráfico de categorias paralelas percebemos que que trabalha com vendas (sales), normalmente é casado.


Aqui percebemos que o setor privado liga com várias ocupações, confirmando a maioria das pessoas são funcionários privados. E as ocupações ligam com a variável target ‘income’ que mostra mais ou menos do que 50k dólares.


Aqui percebemos que as pessoas que ganham mais de 50k estudaram mais.


Vamos observar o nome das coluna e converter as variáveis object para category para reduzir o valor de memória utilizado, para isso, vamos utilizar o comando astype().
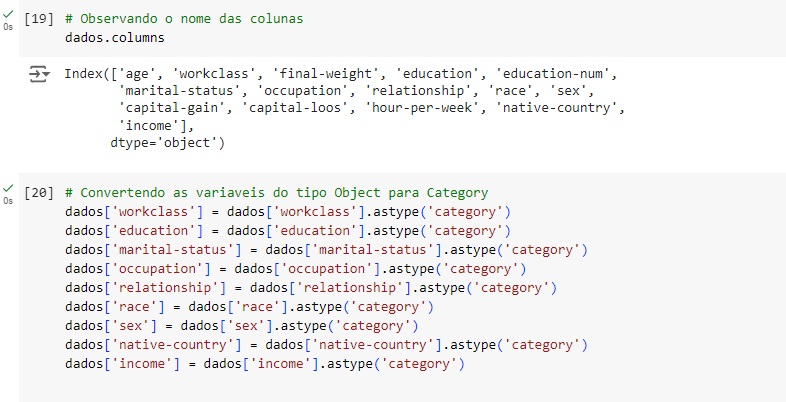
Percebemos que as variáveis que eram object, agora são category, a conversão ocorreu perfeitamente.
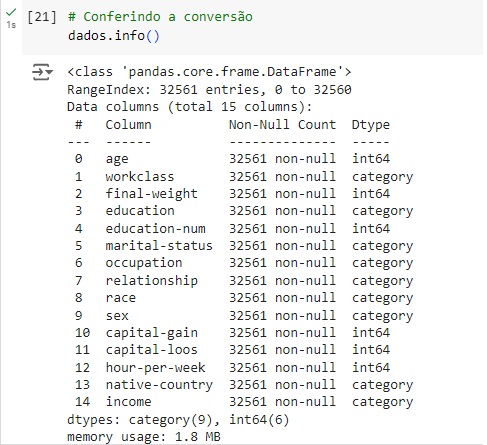
Analisando as variáveis numéricas, com a ajuda do comando len() notamos que existem 6.
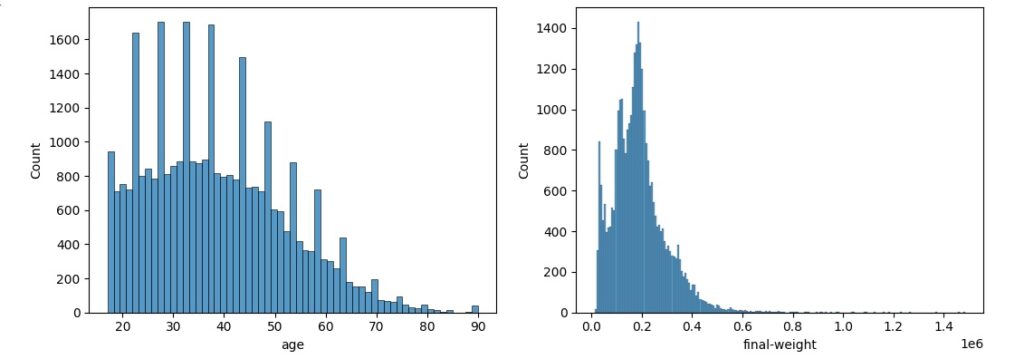
Vamos observar a distribuição normal, para que seja considerada uma distribuição normal dos dados eles precisam ter uma forma simétrica de sino, média igual a zero e desvio padrão igual a 1. Percebemos pelos histogramas gerados que algumas variáveis estão longe de ter uma distribuição normal.


Agora vamos transformar as variáveis categóricas em numéricas utilizando o OneHotEncoder através da biblioteca do scikit-learn LabelEncoder(). Vamos passar o comando lb.fit_transform() nas variáveis que queremos converter, menos na variável target. Em seguida verificamos se surgiu algum valor nulo e percebemos que não.
Agora notamos que as variáveis foram todas convertidas para numérico, menos a target.
Vamos visualizar o balanceamento da variável target e em seguida com o comando iloc[] vamos criar as variáveis preditoras e target.
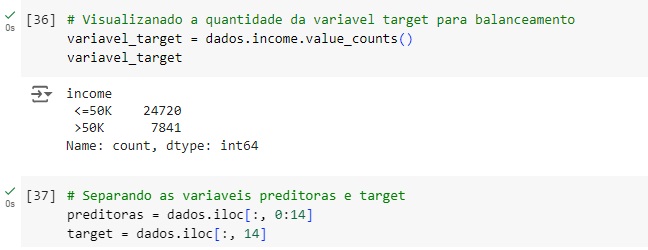
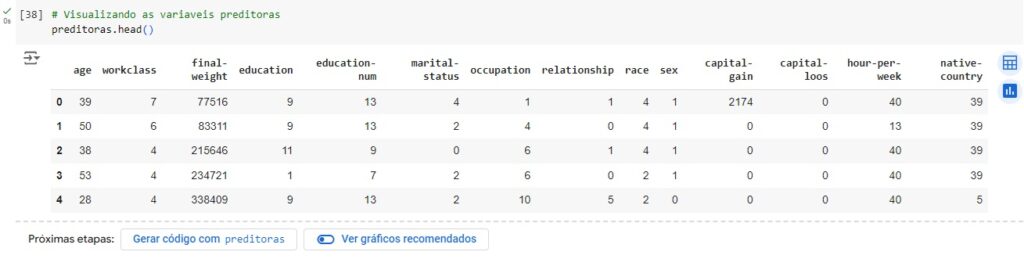
Agora vamos visualizar a variável target, e em seguida balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento em seguida usaremos o fit_resmple() que é o método balanceardor do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target.

Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.

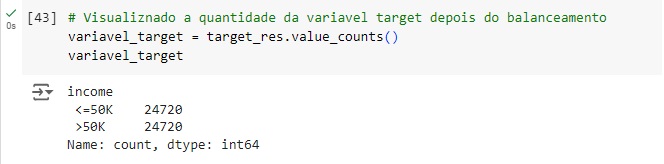
Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 70% dos dados para treinamento e 30% para teste.

Agora vamos padronizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o StandardScaler() e o fit_transform() para isso.

Criando o classificador com o algoritmo de machine learning RandomForestClassifier() com alguns hiperparâmetros para melhorar a acurácia do modelo, n_estimators = 50 é o número de árvores de decisão que terá o modelo. Em seguida criamos o modelo, passamos o classificador com o comando fit() e passamos como parâmetro as variáveis de treino normalizadas.

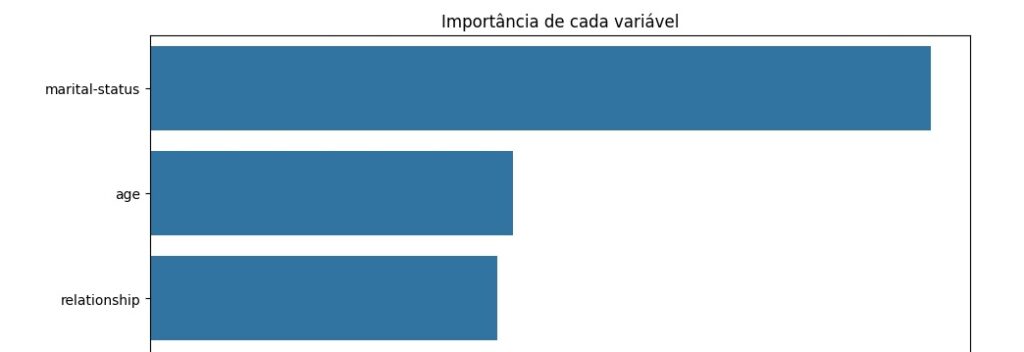
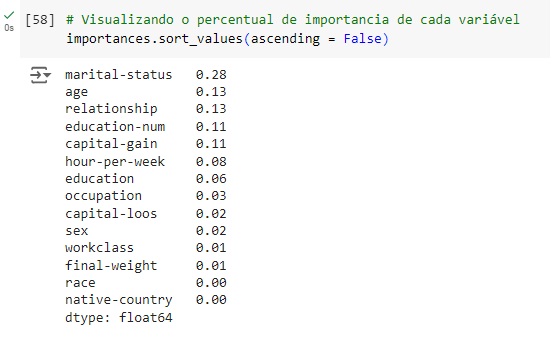
Avaliando graficamente o peso de cada variável no modelo. Vamos cria a variável importances onde vamos passar os dados, o classificador o feature_importances_ que é um comando do próprio Random Forest, pois ele pega as variáveis com um peso maior ao longo do treinamento, no caso seriam as variáveis que tiveram um impacto maior para o resultado do modelo.




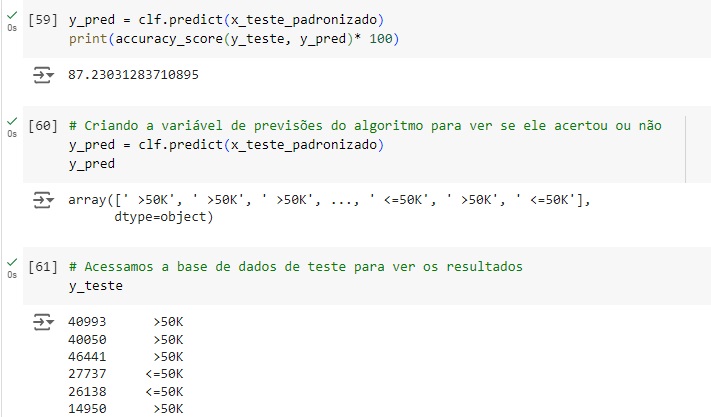
Olhando a acurácia do modelo, percebemos que tivemos 87,23% de acurácia.
Em seguida vamos comparar as previsões com os dados reais percebemos que o algoritmo acertou as primeiras…
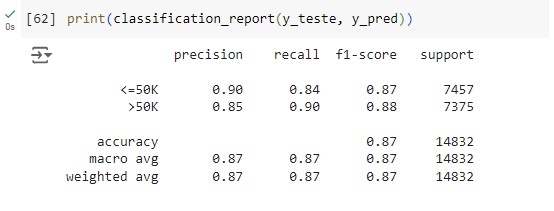
Através do classification report percebemos que o algoritmo consegue identificar corretamente 84% das pessoas que ganham menos de 50k (recall 0.84) e quando identifica uma pessoa desta classe a precisão é de 90% (precision 0.90). Para as pessoas que ganham mais de 50k o algoritmo teve resultado parecido com 90% das identificações corretas (recall 0.90) com 85% de certeza (precision 0.85).
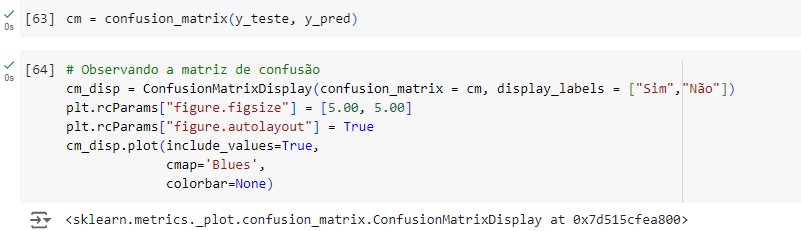
Plotando a matriz de confusão podemos perceber na linha de cima que 6279 pessoas têm salário <= 50k no banco de dados real e foi também o valor que o modelo previu, ou seja, é um verdadeiro positivo. Mas o modelo errou 1178 dizendo que ganham um salário <= 50k, quando na verdade ganham um salário > 50k.
Na linha de baixo percebemos que o modelo acertou que 6659 pessoas têm um salário > 50k e errou prevendo que 716 pessoas tem um salário > 50k quando na verdade é menor ou igual.