Modelo Preditivo Para Recursos Humanos

Neste post vamos desenvolver um modelo preditivo para identificar funcionários de uma empresa com tendência ou não de pedir demissão. Vamos analisar fatores como salário, idade, escolaridade, distância de casa e desgaste. O projeto foi desenvolvido na plataforma Google Colab utilizando linguagem Python. Antes vamos ver alguns fatores importantes sobre o banco de dados:
Education
1 – Abaixo da faculdade;
2 – Faculdade;
3 – Bacharelado;
4 – Mestre;
5 – Doutor.
EnvironmentSatisfaction
1 – Baixa;
2 – Média;
3 – Alta;
4 – Muito Alta.
JobInvolvement
1 – Baixo;
2 – Médio;
3 – Alto;
4 – Muito Alto.
JobSatisfaction
1 – Baixa;
2 – Média;
3 – Alta;
4 – Muito Alta.
PerformanceRating
1 – Baixo;
2 – Bom;
3 – Excelente;
4 – Acima da Média.
RelationshipSatisfaction
1 – Baixa;
2 – Média;
3 – Alta;
4 – Muito Alta.
WorkLifeBalance
1 – Ruim;
2 – Médio;
3 – Bom;
4 – Excelente.
Vamos iniciar a implementação. Vamos começar importando as bibliotecas:
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Smote – para balancear os dados.
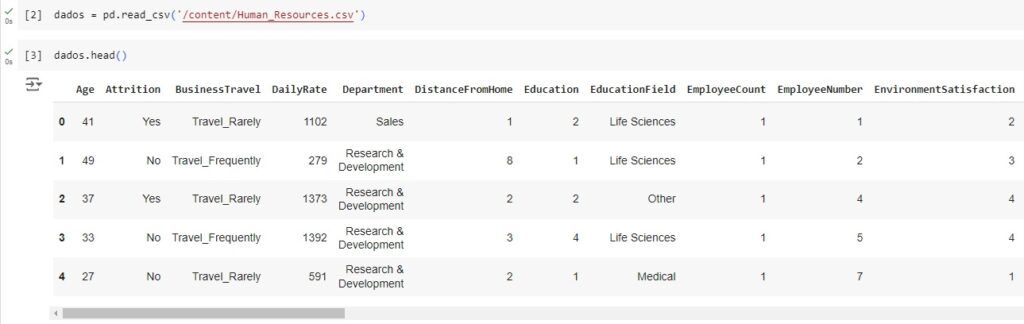
Agora vamos carregar a base de dados e observá-la.
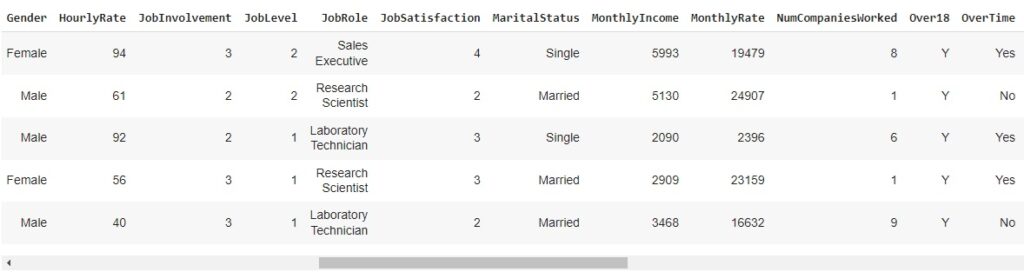
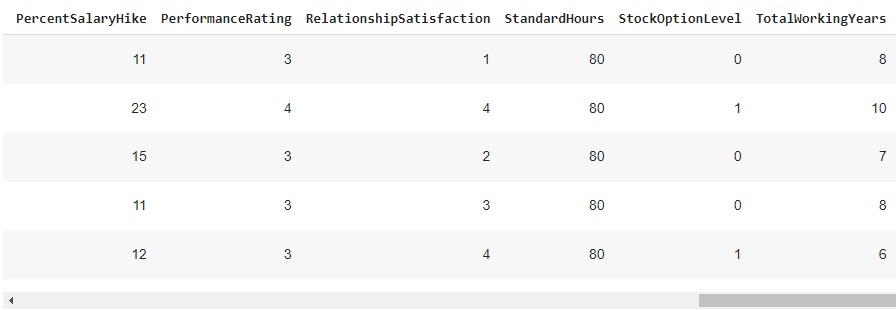
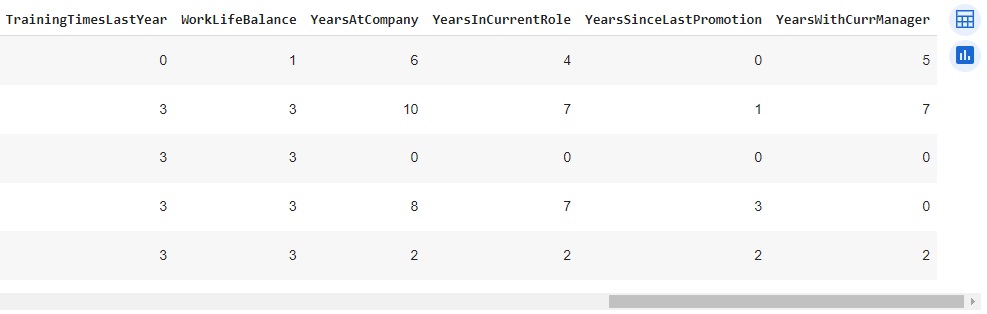
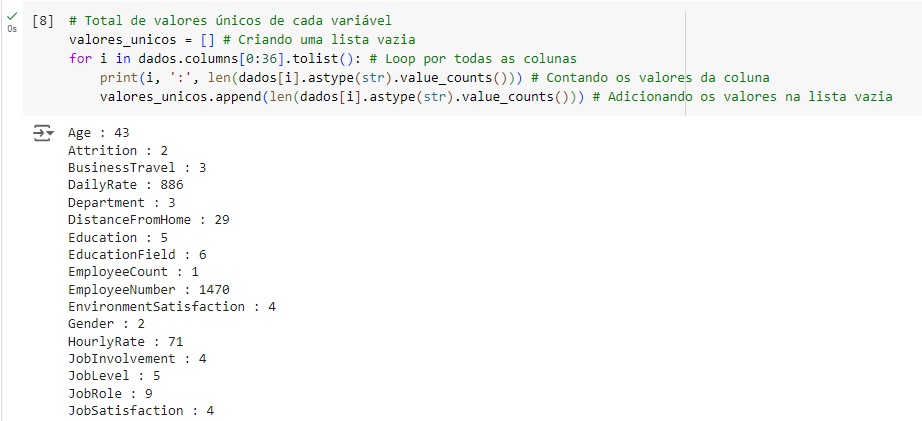
Com a ajuda do comando info(), obtemos algumas informações informações e percebemos que existem variáveis do tipo object, que mais adiante serão tratadas.
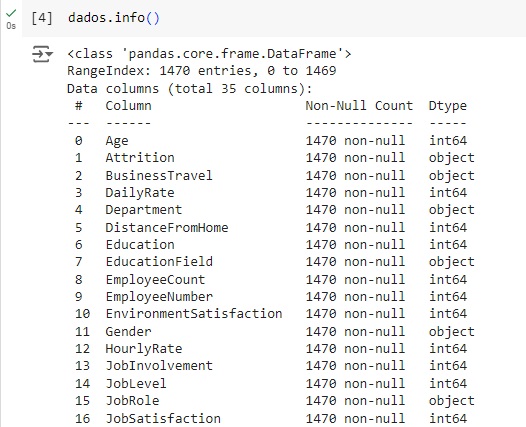
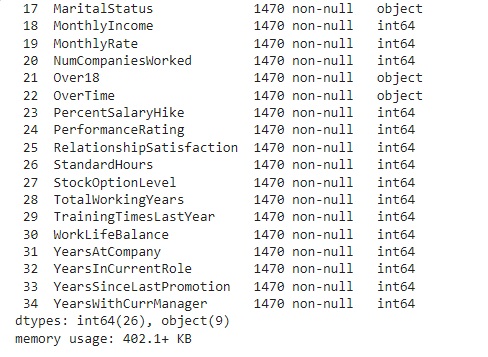
Observando o shape notamos que a base de dados possui 1470 linhas e 35 colunas.

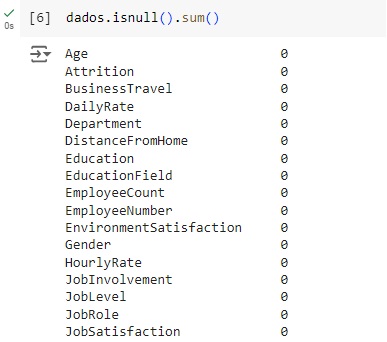
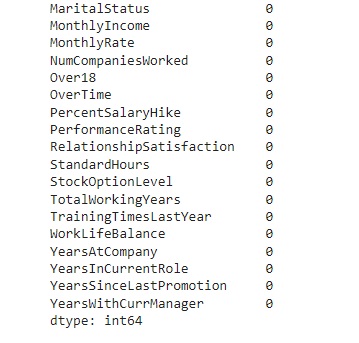
Verificando os valores nulos e contando os mesmos utilizando o comando isnull().sum(). Podemos observar que não existem valores nulos no banco de dados.
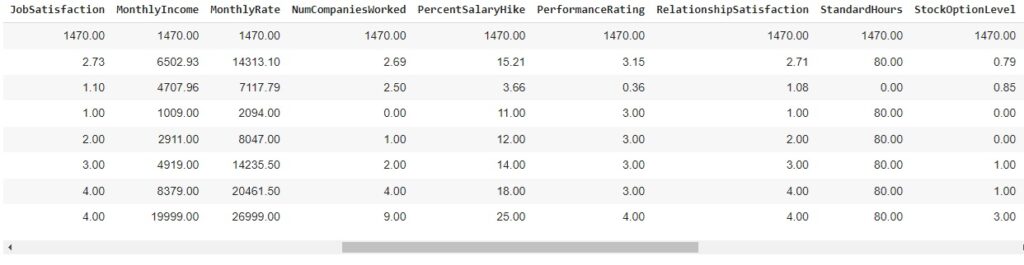
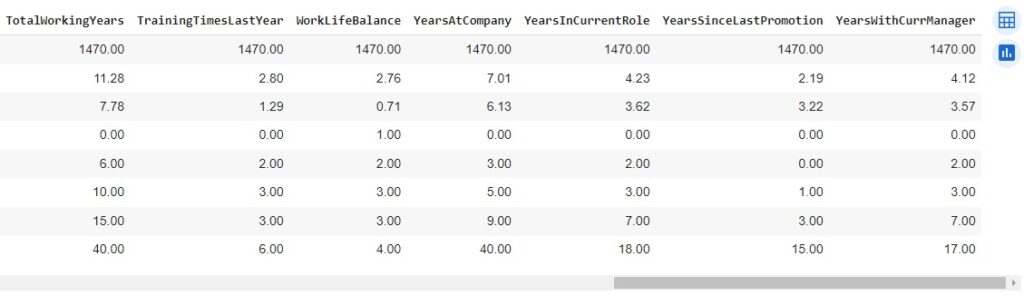
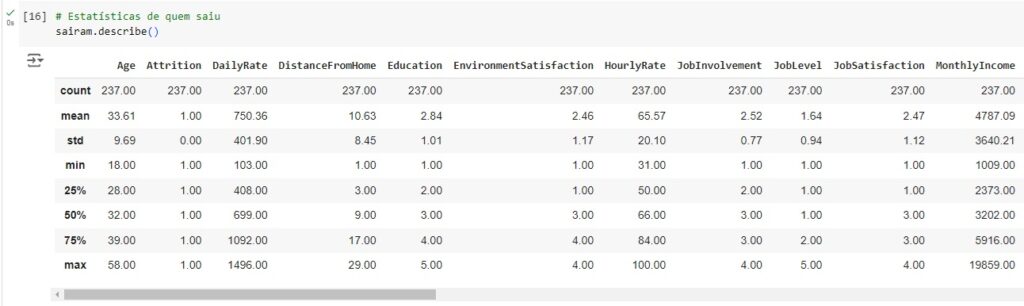
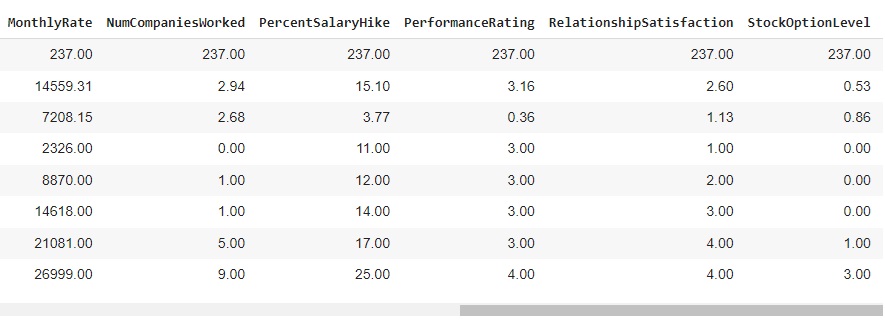
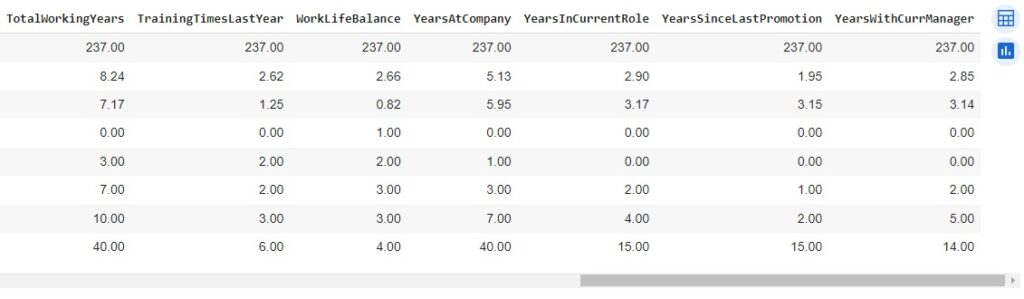
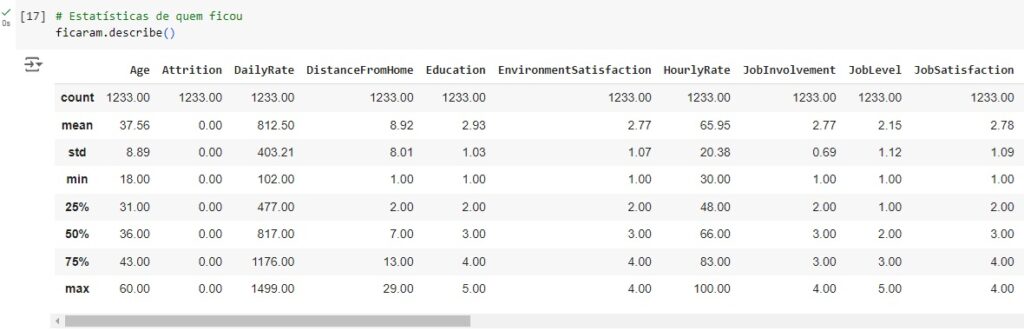
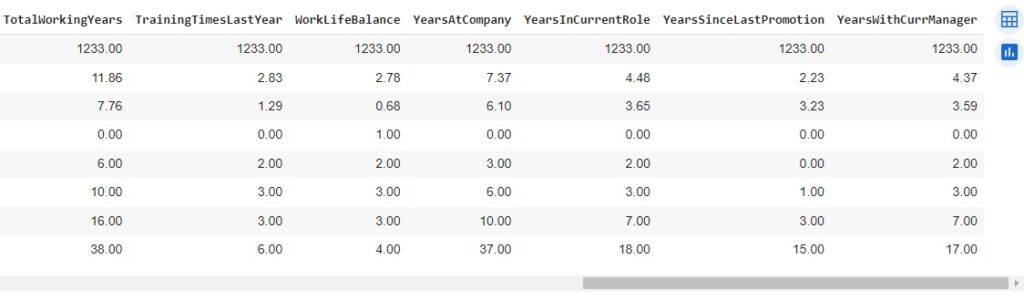
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão. Também podemos notar que os dados estão em diversas escalas, logo mais iremos padronizar estes dados.

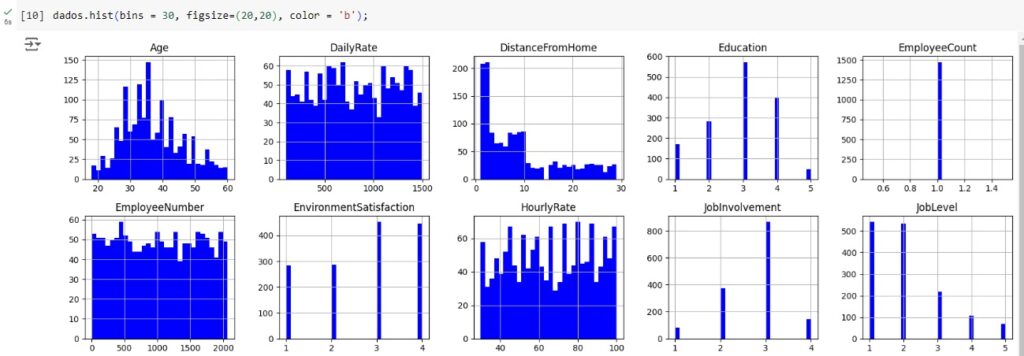
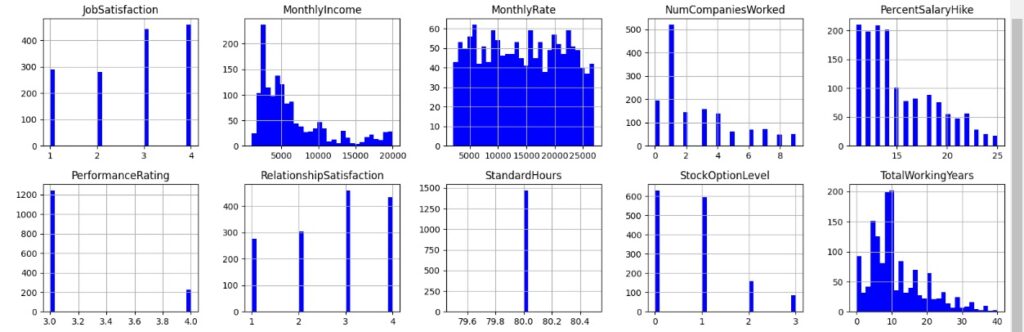
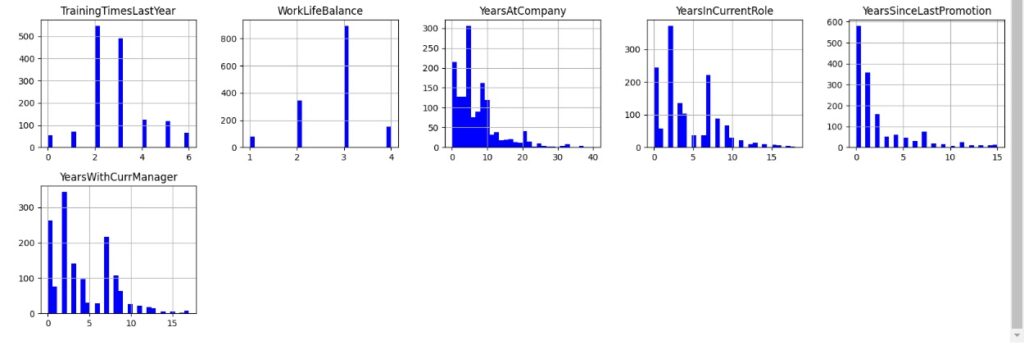
Vamos gerar histogramas para cada atributo e fazer algumas análises através da distribuição dos dados. Obs: bins = 30 significa 30 faixas de valores. Percebemos no gráfico da variável ‘Age’ que significa idade que a maioria das pessoas da empresa tem entre 25 e 40 anos. Na variável ‘DistanceFromHome’ que significa distância de casa percebemos que a maioria mora perto da empresa, menos de 10km. Em ‘Education’ notamos que a maioria dos funcionário tem nível escolar 3 que é o bacharelado, em ‘MonthlyIncome’ vemos que a maioria ganha até 5000 dólares por mês. Na variável ‘YearsAtCompany’ percebemos que a maioria dos empregados estão na empresa entre 0 e 10 anos.
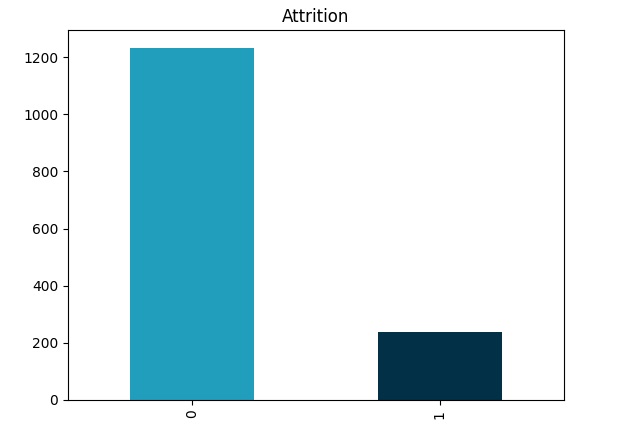
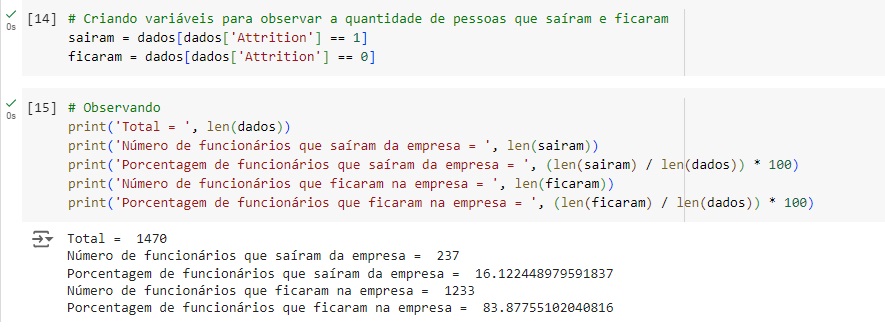
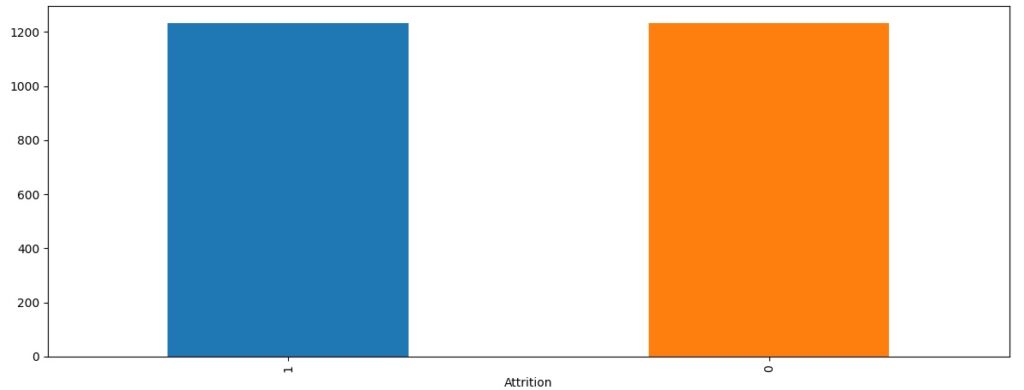
Vamos apagar algumas variáveis que não usaremos e também observar a nossa variável target, podemos notar um grande desbalanceamento na base de dados, pois o valor 0 indica as pessoas que ficam na empresa e o valor 1 indica as pessoas que tem tendência a sair.


No gráfico abaixo podemos perceber que funcionários com menos de 20 anos tem maior tendência a deixar a empresa, enquanto funcionários acima dos 25 anos tem uma tendência maior a ficar.


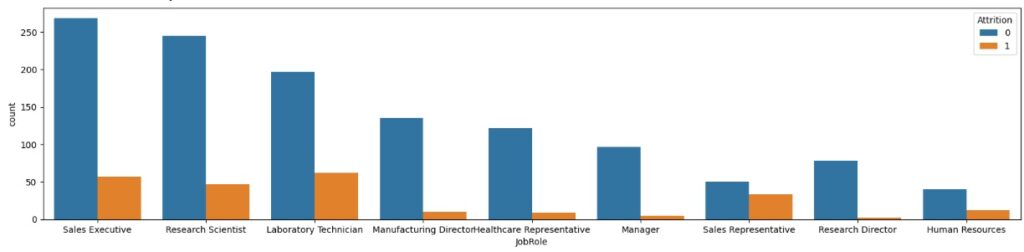
No gráfico 1 percebemos que as pessoas que mais saem da empresa são os Sales Representative (Representantes de vendas)).
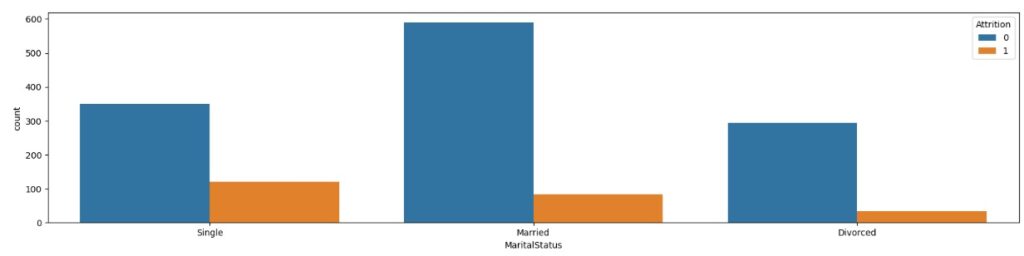
No gráfico 2 temos o estado civil e notamos que os solteiros tem uma maior tendência em sair.
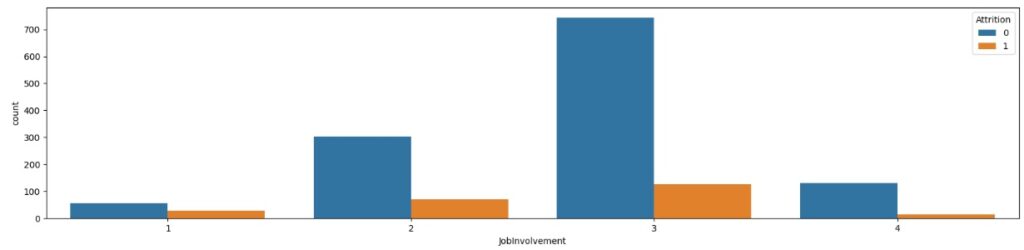
No gráfico 3 em relação ao envolvimento com o trabalho, as pessoas com nível 3, ou seja com um envolvimento alto, tendem a sair.
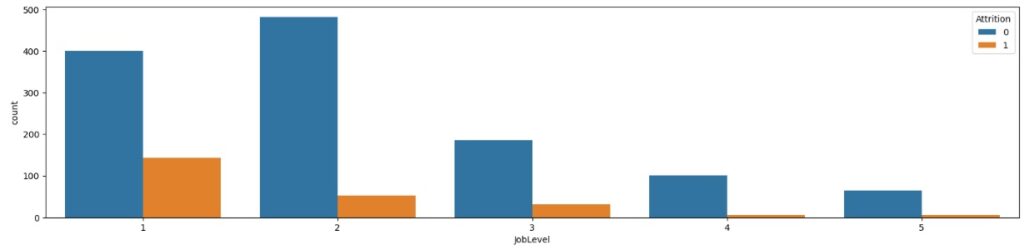
No gráfico 4 em relação ao nível do cargo na empresa, notamos que os funcionários com cargos mais baixos como 1 e 2 tem maior tendência a sair do que 4 e 5 que são cargos mais altos e consequentemente com melhores salários.

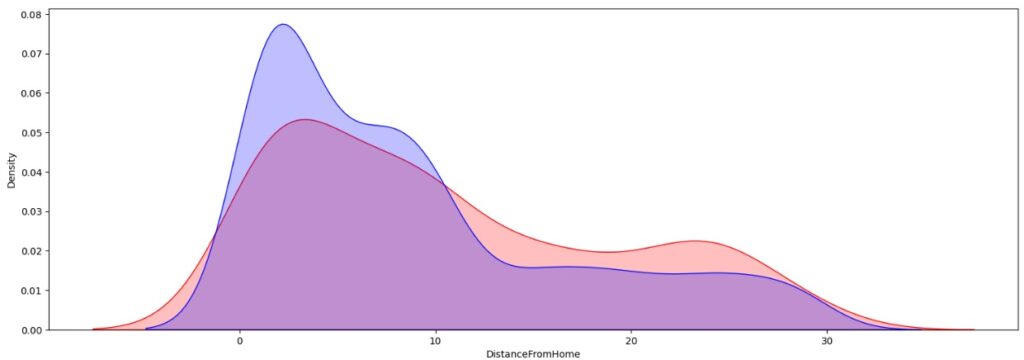
No gráfico abaixo, vemos através da parte azul que funcionários que moram até 10km da empresa tendem a ficar em relação a parte vermelha, que simboliza os que saíram.

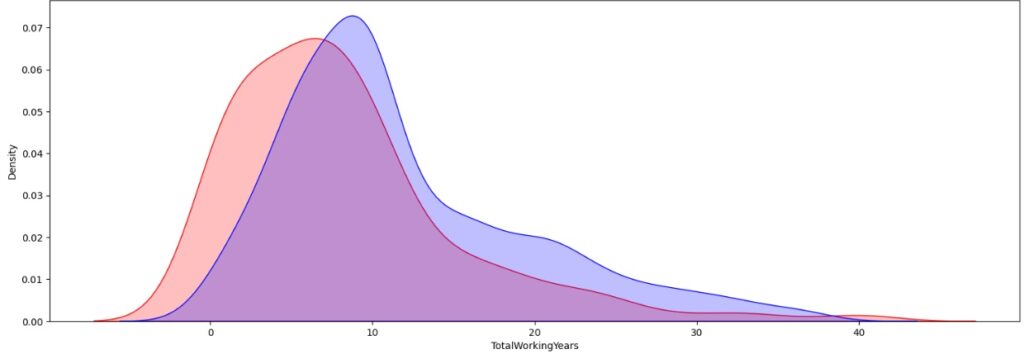
Neste outro gráfico percebemos que os funcionários que trabalharam na empresa mais de 10 anos tendem a continuar como mostra a parte azul em relação as que saíram que na sua maioria trabalharam menos de 10 anos como mostra a parte vermelha.

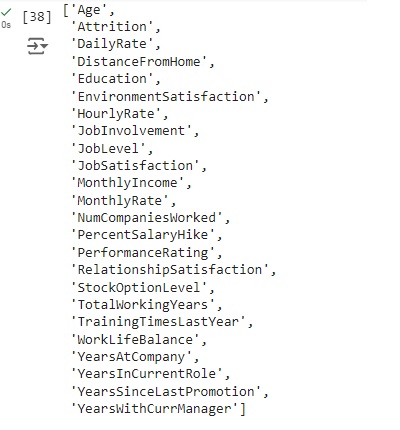
Separando as variáveis numéricas.

Agora vamos transformar as variáveis categóricas em numéricas utilizando o OneHotEncoder através da biblioteca do scikit-learn LabelEncoder(). Vamos passar o comando lb.fit_transform() nas variáveis que queremos converter, menos na variável target. Em seguida verificamos se surgiu algum valor nulo e percebemos que não.
Observando se apareceu algum valor nulo durante a transformação, percebemos que não.

Confirmando se as transformações foram feitas e percebemos que sim, todos as variáveis agora estão como numéricas.

Separando a variável target das variáveis preditoras.
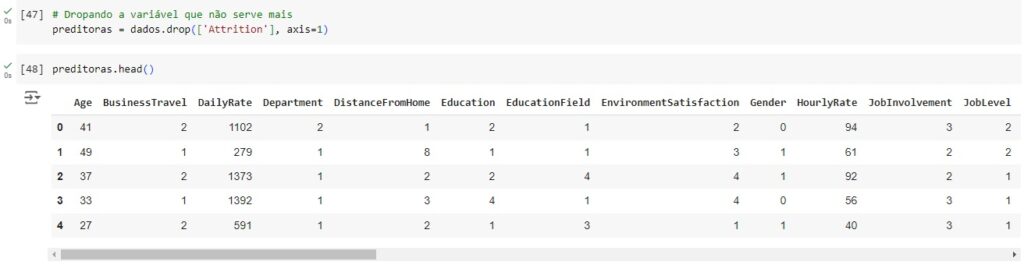


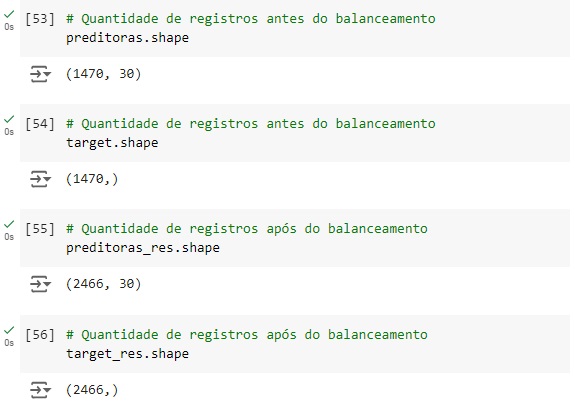
Agora vamos balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento em seguida usaremos o fit_resmple() que é o método balanceardor do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target.
Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.


Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 75% dos dados para treinamento e 25% para teste. Em seguida vamos normalizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o MinMaxScaler() e o fit_transform() para isso.
Criando o classificador com o algoritmo de machine learning RandomForestClassifier() com alguns hiperparâmetros para melhorar a acurácia do modelo, n_estimators = 50 é o número de árvores de decisão que terá o modelo. Em seguida criamos o modelo, passamos o classificador com o comando fit() e passamos como parâmetro as variáveis de treino normalizadas.
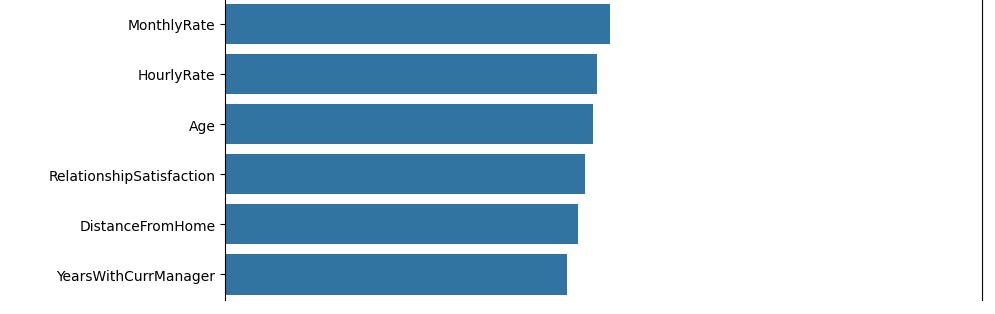
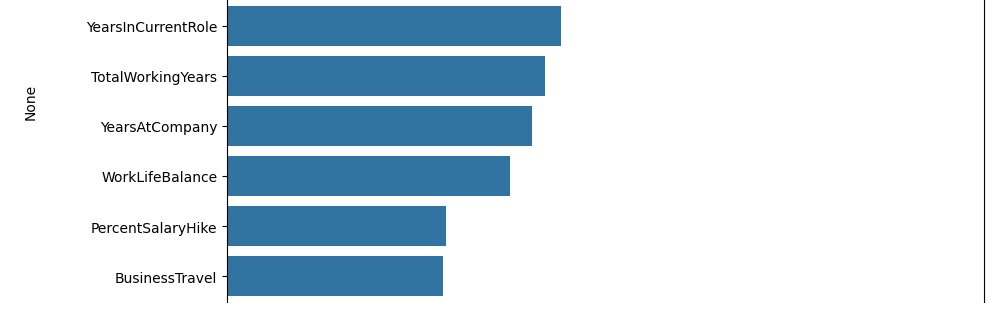
Logo abaixo vamos observar graficamente o peso de cada variável no modelo. Vamos criar a variável importances onde vamos passar os dados, o classificador o feature_importances_ que é um comando do próprio Random Forest, pois ele pega as variáveis com um peso maior ao longo do treinamento, no caso seriam as variáveis que tiveram um impacto maior para o resultado do modelo.


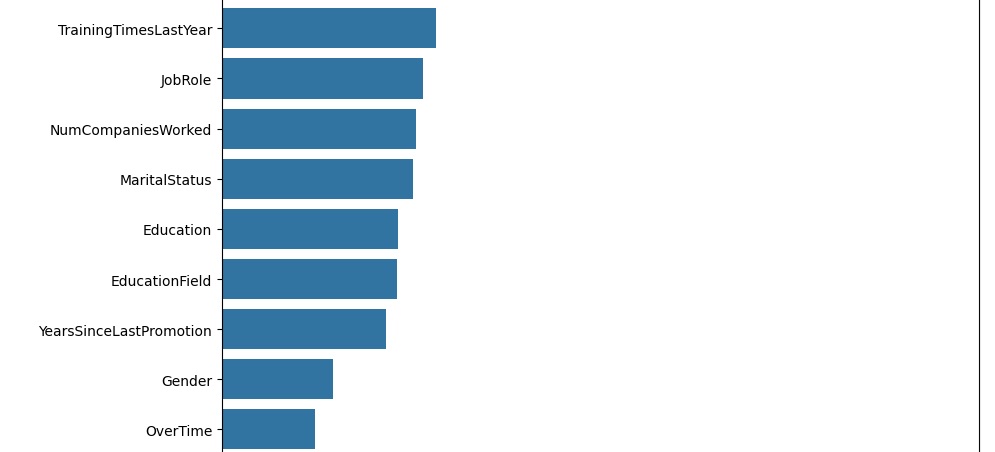

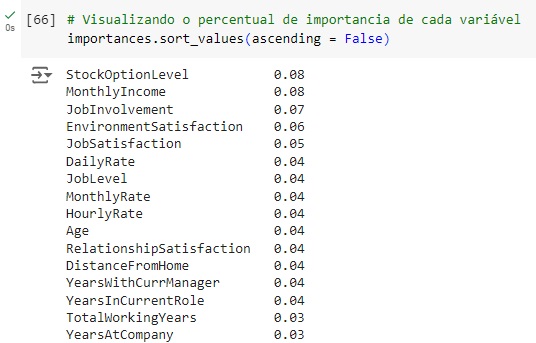
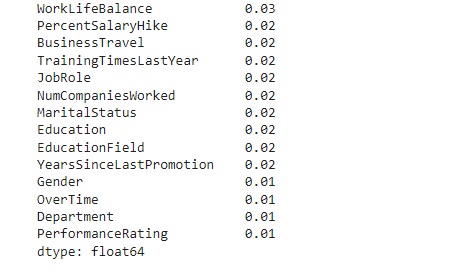
Olhando a acurácia do modelo, percebemos que tivemos 91,08% de acurácia.

Comparando as previsões com os dados reais percebemos que o algoritmo errou as 3 primeiras, acertou a quarta, a quinta a sexta e a sétima acertou novamente…


Através do classification report percebemos que o algoritmo consegue identificar corretamente 93% das pessoas que ficam na empresa (recall 0.93) e quando identifica uma pessoa desta classe a precisão é de 89% (precision 0.89). Para as pessoas que possuem tendência a sair da empresa o resultado do algoritmo foi de 90% das identificações corretas (recall 0.90) com 93% de certeza (precision 0.93).
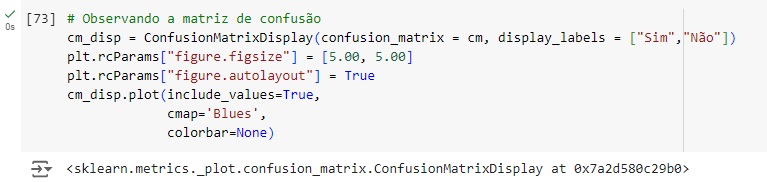
Vamos afazer uma análise a partir da matriz de confusão. Vamos importar a biblioteca sklearn.metrics import confusion_matrix.

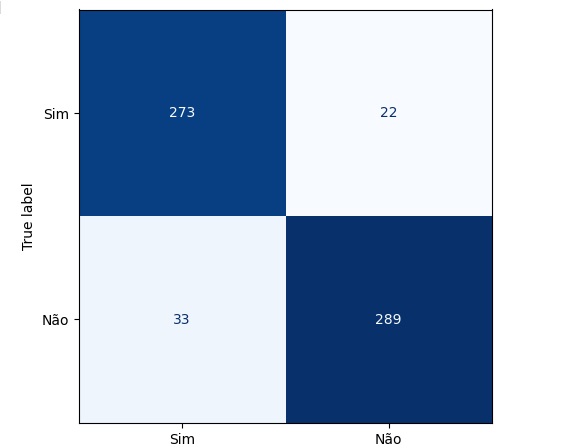
Plotando a matriz de confusão podemos perceber que 273 pessoas ficam na empresa no banco de dados real e foi também o valor que o modelo previu, ou seja, é um verdadeiro positivo. No outro lado da matriz percebemos que segundo os dados reais 289 pessoas tendem a sair, o mesmo valor que o modelo previu. Com isso conseguimos perceber que a diagonal que está azul mais escuro são os acertos do modelo.
Passando para a diagonal azul claro, percebemos que o banco de dados real tem 22 pessoas ficam na empresa, mas o modelo previu que sai, ou seja, é um falso positivo, no caso o modelo errou a previsão. Na outra diagonal percebemos que tem 33 pessoas que saem segundo o banco de dados real, mas o modelo previu que não vão sair.