Adaptabilidade Estudantil em Aulas Online

Neste projeto vamos criar um modelo preditivo para prever a adaptabilidade de alunos que estudam na modalidade online. O código foi desenvolvido em linguagem Python na plataforma Google Colab. Vamos para a implementação.
Vamos começar importando as bibliotecas.
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Time – para funcionalidades referente ao tempo;
Smote – para o balanceamento dos dados.
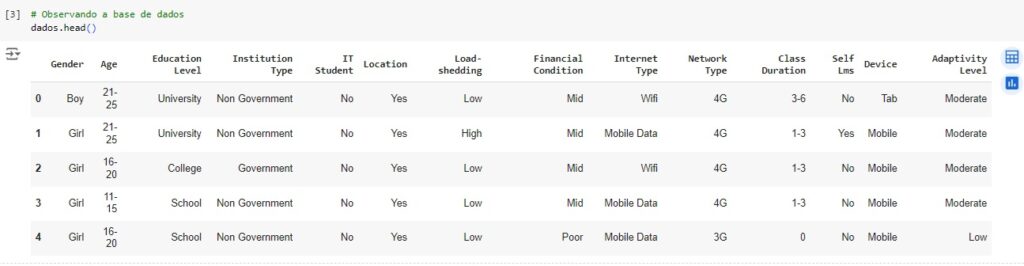
Carregando a base de dados e observando as variáveis. Nossa variável alvo será ‘Adaptivity Level’.

Conferindo o shape, percebemos que o banco de dados possui 1205 linhas e 14 colunas. O comando info() nos mostra que todas as variáveis são do tipo object, mais tarde vamos tratá-las para poder aplicar o modelo de machine learning.

Verificando os valores nulos com o comando isnull().sum(). Podemos observar que não existem valores nulos no dataset.
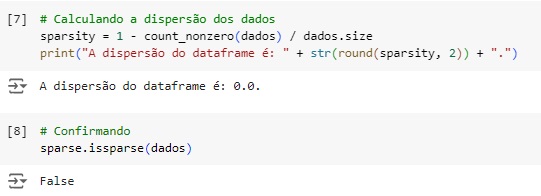
Agora vamos analisar a dispersão do dataset. Para que um dataset seja esparso aproximadamente metade das observações ou mais da metade delas deve ser zero. Percebemos que temos 0%. Através da função do scipy issparse() temos como resposta que o conjunto de dados não é esparso, consta como False.
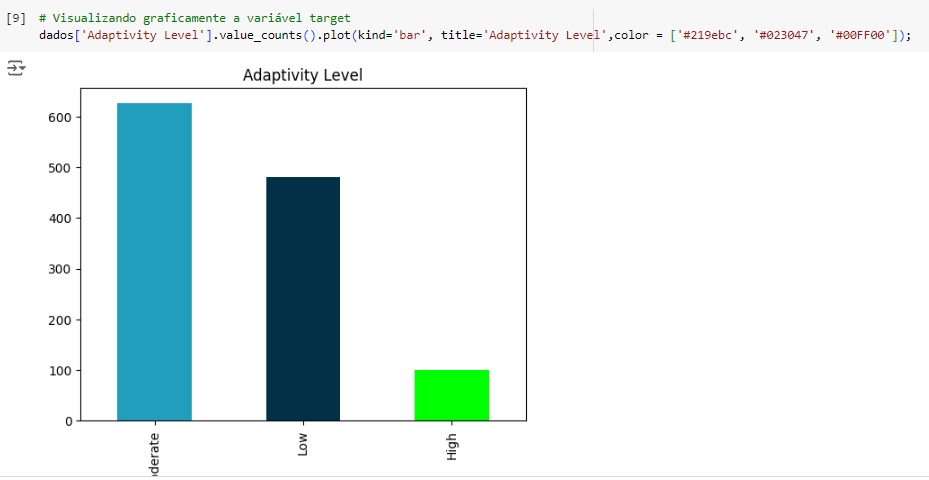
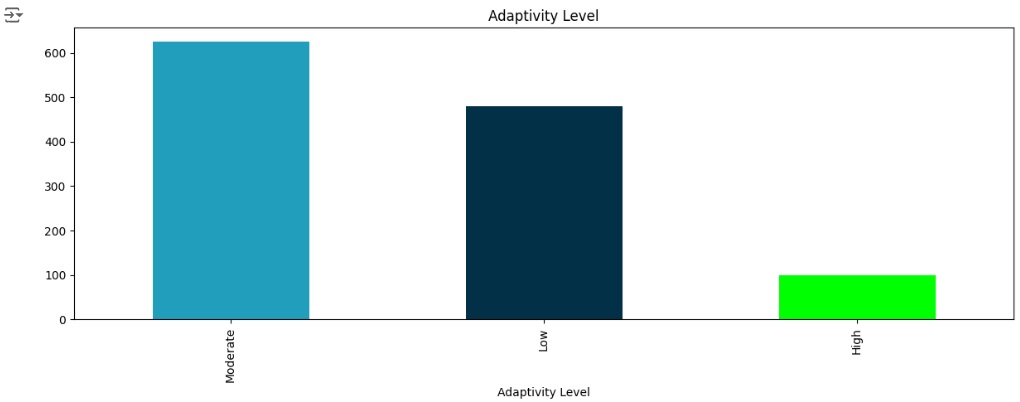
Vamos observar a nossa variável target ‘Adaptivity Level’. Percebemos através do gráfico que ela esta bem desbalanceada, logo mais iremos cuidar disso.

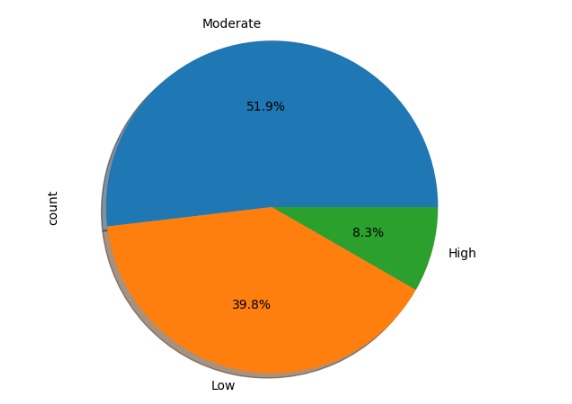
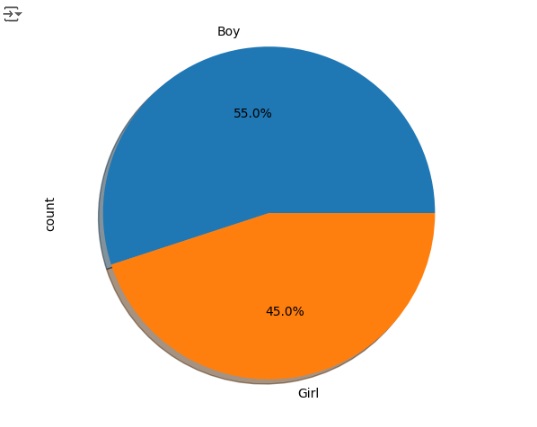
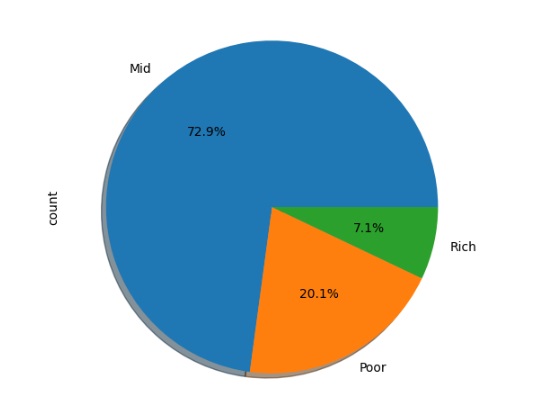
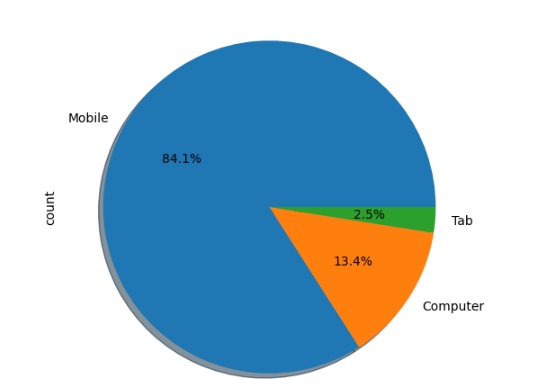
Vamos analisar a adaptabilidade em outras variáveis através do gráfico de pizza.


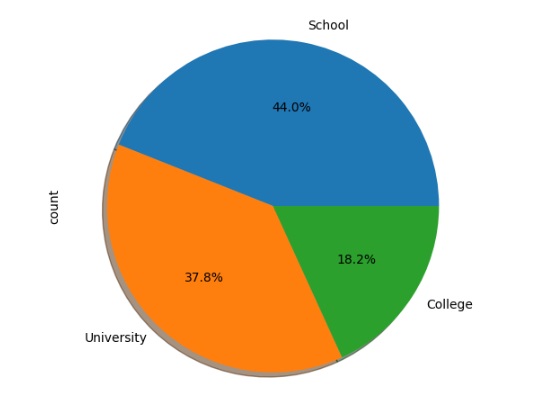


Mostrando a adaptabilidade no gráfico de barras em cada tipo de instituição.


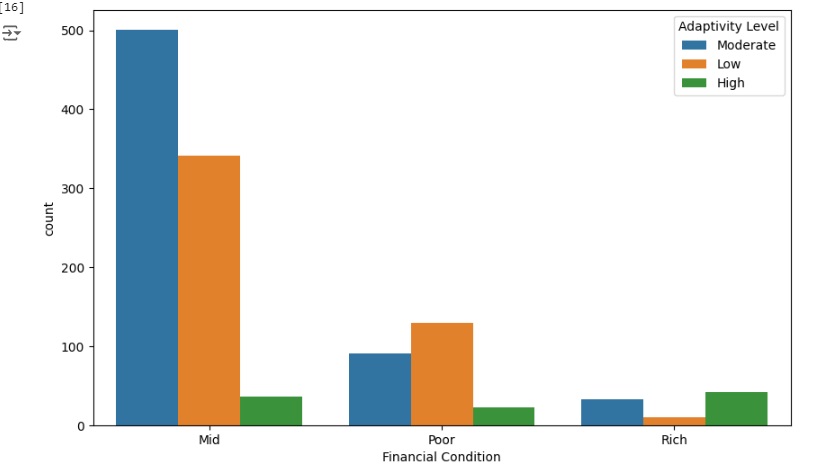
No gráfico abaixo percebemos que as famílias de classe média tem uma maior adaptabilidade ao ensino online, seguido pelas famílias mais pobres, notamos que as famílias mais ricas têm mais dificuldade de adaptação.


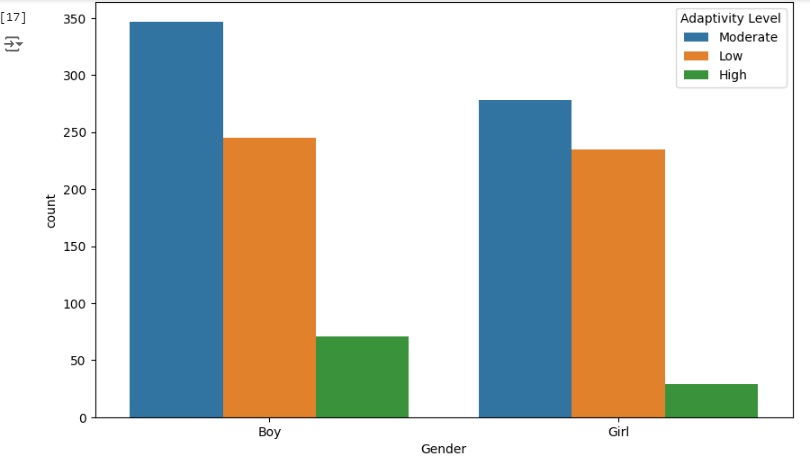
Aqui podemos notar que os alunos que utilizam rede 4G tem melhor adaptabilidade.


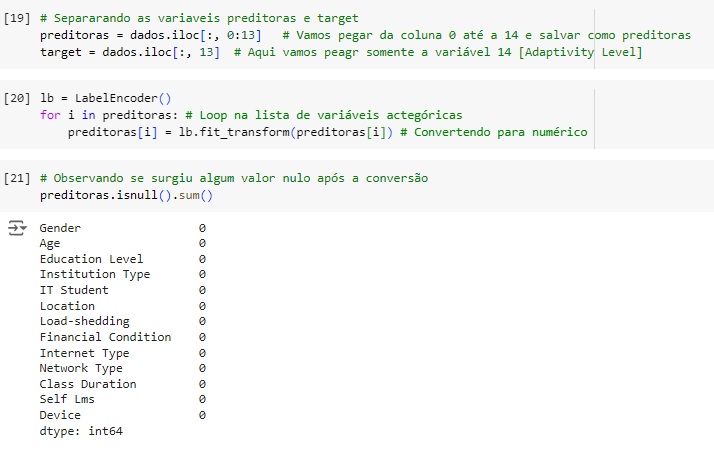
Agora vamos separar a variável alvo das preditoras e em seguida transformar as variáveis categóricas em numéricas utilizando o LabelEncoder através da biblioteca do scikit-learn LabelEncoder(). Vamos passar o comando lb.fit_transform() nas variáveis que queremos converter, menos na variável target. Em seguida verificamos se surgiu algum valor nulo e percebemos que não.
Depois de ter feito a conversão, vamos ver a quantidade de 0 e 1 no dataset, isso é importante para evitar o overfitting que é o ajuste excessivo dos dados e pode prejudicar o resultado final do nosso modelo.
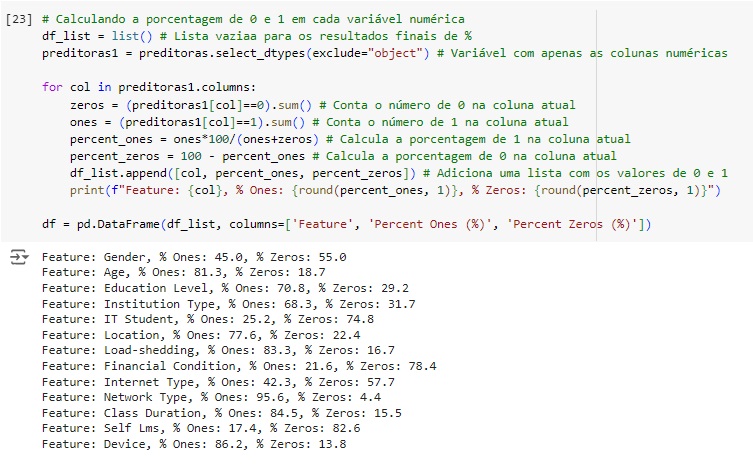
Vamos encontrar as colunas que possuem 99% valores 0 e 1. Percebemos que não existem.

Agora vamos balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento, em seguida usaremos o fit_resmple() que é o método balanceador do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target. Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.

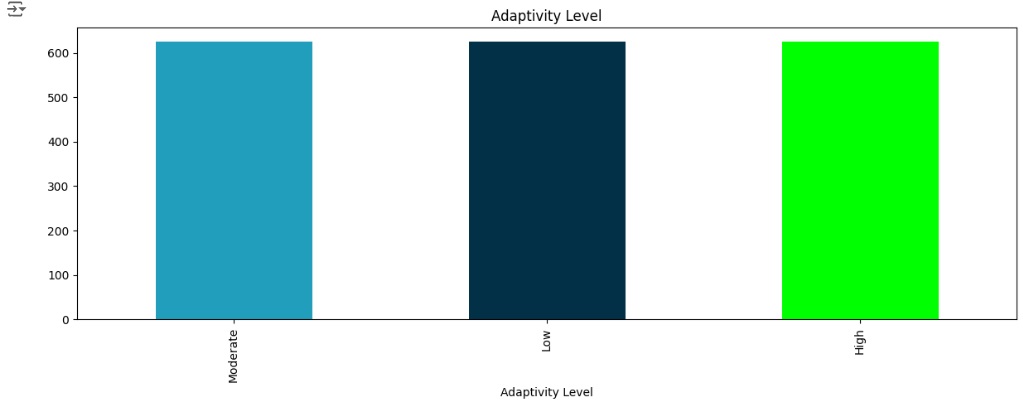
Observando o shape da variável alvo antes e depois do balanceamento.
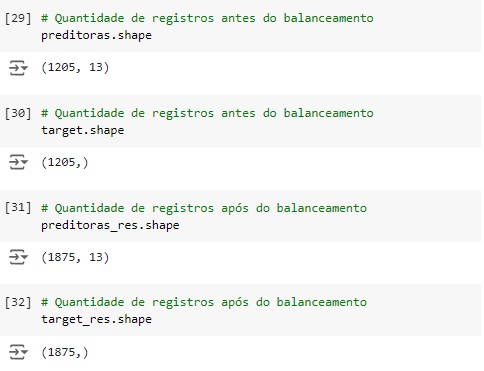
Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 70% dos dados para treinamento e 30% para teste.
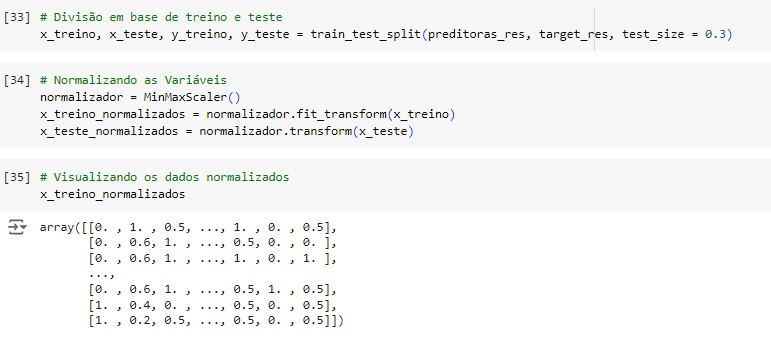
Em seguida vamos normalizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o MinMaxScaler() e o fit_transform() para isso e em seguida vamos observá-los.
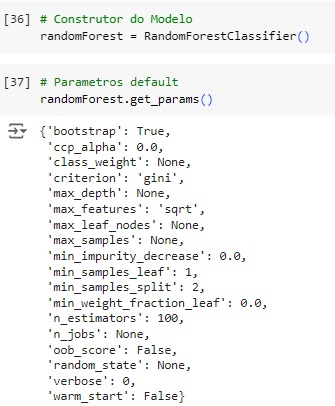
Vamos utilizar o algoritmo Random Forest e para isto vamos primeiro encontrar os melhores parâmetros para que o modelo tenho melhores resultados.
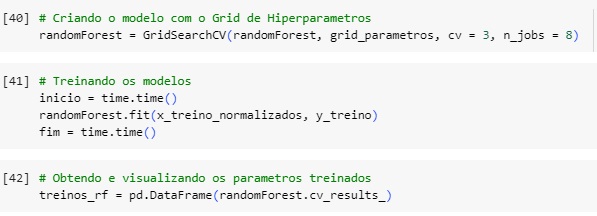
n_estimators – é o número de árvores da floresta, podem aumentar a performance até certo ponto, mas também aumentam o tempo de treinamento e a complexidade computacional.
max_depth – limita a profundidade das árvores pode evitar o overfitting (quando o modelo se ajusta muito aos dados de treinamento e não generaliza bem para dados novos). Árvores muito profundas podem capturar todos os detalhes dos dados de treinamento, mas falhar em generalizar.
criterion – função para medir a qualidade de uma divisão (split).
max_features – controla o número de características consideradas em cada divisão. Valores menores reduzem a variância do modelo, mas podem aumentar o viés.
min_samples_split – define o número mínimo de amostras necessárias para dividir um nó interno. Em outras palavras, determina o número mínimo de amostras que um nó deve ter para que ele seja considerado para divisão em dois novos nós.
min_samples_leaf – define o número mínimo de amostras que deve estar presente em um nó folha. Ou seja, determina o número mínimo de amostras que um nó final (sem filhos) deve conter para não ser dividido.

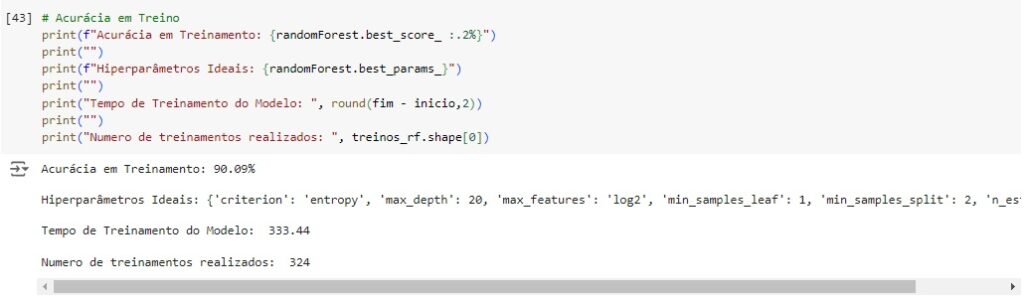
Vamos criar o modelo com os parâmetros indicados.
Agora vamos avaliar graficamente o peso de cada variável no modelo. Vamos criar a variável importances onde vamos passar os dados, o classificador o feature_importances_ que é um comando do próprio Random Forest, pois ele pega as variáveis com um peso maior ao longo do treinamento, no caso seriam as variáveis que tiveram um impacto maior para o resultado do modelo.



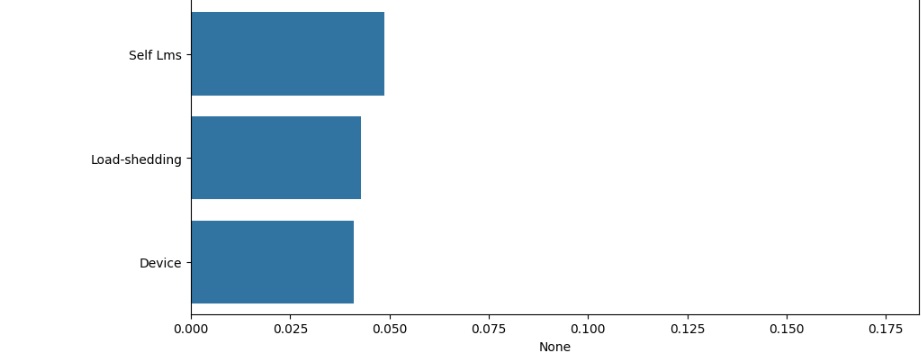
Observando a porcentagem de cada variável no modelo e logo abaixo podemos ver a acurácia que foi de 90.76%.
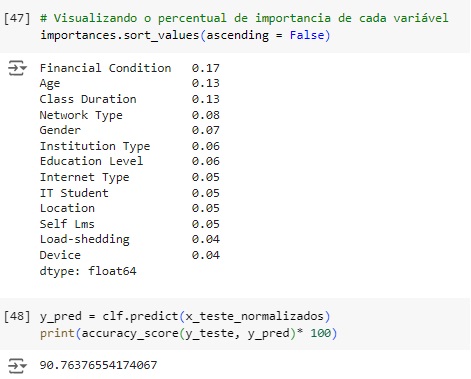
Comparando as previsões com os dados reais percebemos que o algoritmo acertou as 5 primeiras, errou a sexta, a sétima e a oitava acertou novamente…

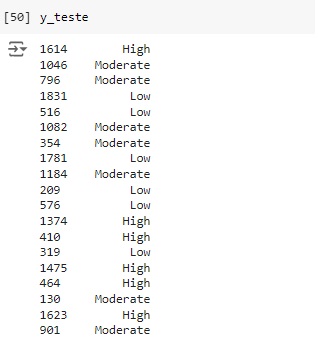
Através do classification report percebemos que o algoritmo consegue identificar corretamente 97% das pessoas tem adaptabilidade alta (high) ao aprendizado online (recall 0.97) e quando identifica uma pessoa desta classe a precisão é de 88% (precision 0.88). Para as pessoas que possuem adaptabilidade baixa (low) o resultado do algoritmo foi de 91% das identificações corretas (recall 0.91) com 94% de certeza (precision 0.94). Já para as pessoas com adaptabilidade média (moderate) o resultado do algoritmo foi de 85% das identificações corretas (recall 0.85) com 91% de certeza (precision 0.91).
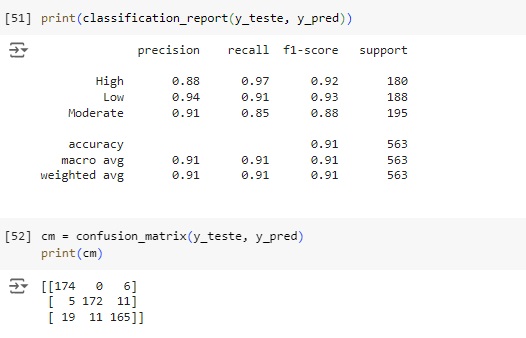
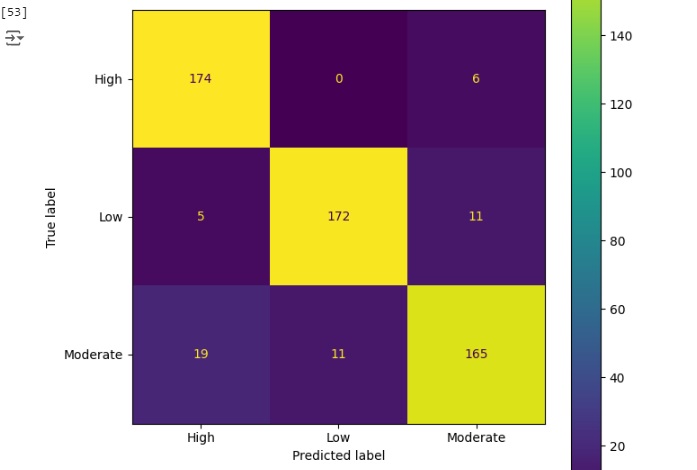
Na matriz de confusão abaixo percebemos que o modelo acertou que 174 pessoas tem adaptabilidade alta (high), disse que 0 adaptabilidade baixa (low) e errou dizendo que 6 tem adaptabilidade alta, quando na verdade tem adaptabilidade média (moderate).
Na parte do meio da tabela na parte amarela o algoritmo acertou que 172 pessoas têm baixa (low) adaptabilidade e errou prevendo que 5 pessoas têm adaptabilidade baixa quando na verdade é alta, e errou também prevendo que 11 pessoas têm adaptabilidade baixa, quando na verdade tem média.
Na parte baixa da tabela em amarelo, percebemos que o modelo acertou que 165 das pessoas têm adaptabilidade média (moderate), mas errou quando previu que 11 pessoas têm adaptabilidade média quando na verdade a adaptabilidade é baixa e também errou prevendo que 19 pessoas têm adaptabilidade média quando na verdade é alta.