Criando Modelo de Clusterização com Machine Learning

Hoje vamos mostrar passo a passo um modelo de clusterização de consumo de energia em Python.
O Que é Clusterização?
A clusterização é uma técnica de machine learning não supervisionado que visa agrupar os dados em determinados conjuntos distintos entre si. É muito útil para diversos contextos, como para o marketing e para estudos de mercado. Trata-se de um método descritivo, pois apenas realça as características dos dados de entrada, sem intenção de realizar previsões ativas sobre eles.
As soluções que definem os clusters buscam determinar muito bem onde um agrupamento começa e onde termina, ou seja, com “contornos” muito bem estabelecidos. A principal característica é que os conjuntos são diferentes entre si.
Para este projeto, temos dados de consumo de energia e iremos agrupar os consumidores pelas suas similaridades para compreender o comportamento destes clientes, destes consumidores de energia elétrica em relação ao consumo de energia.
O algoritmo foi desenvolvido na plataforma Google Colab utilizando linguagem de programação Python. Vamos para a implementação:
Vamos começar importando as bibliotecas:
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Scipy – para fornecer conjunto de ferramentas e funções para análise de dados científicos.
Em seguida vamos carregar nossa base de dados. O comando delimiter = ‘ ; ‘ , serve para separar por ponto e vírgula os valores.

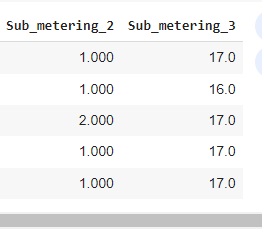
Através do comando head() vamos observar os 5 primeiros valores.

Com o comando info(), podemos verificar algumas informações sobre os dados, como tipos de variáveis, percebemos que a maioria delas estão como object ou seja, são variáveis categóricas que não são numéricas, e para aplicar o modelo de machine learning as variáveis precisam ser numéricas, pois os modelos não interpretam palavras, apenas números, portanto faremos esta transformação mais adiante.

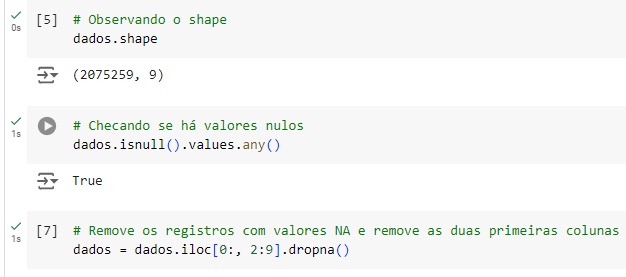
Observando o shape, podemos ver que o este banco de dados possui 2075259 linhas e 9 colunas. Com o comando isnull().values.any(), vamos observar a quantidade de valores nulos e percebemos recebemos a resposta ‘True’, que significa que temos valores nulos que precisamos tratar. Com a ajuda do comando iloc[].dropna(), vamos excluir os valor nulos e as colunas que não servir para o nosso projeto que são ‘Date’ e ‘Time’.
O próximo passo é transformar as variáveis categóricas em numéricas, para isso vamos usar o astype(dtype = ‘float64’), assim as variáveis serão convertidas para o formato float64.

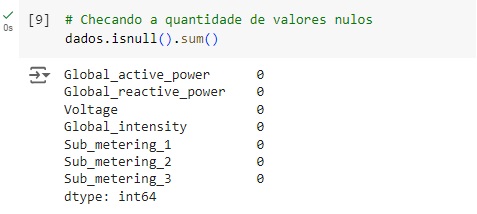
Observamos que não existe mais nenhum valor nulo.
Conferindo a atualização do banco de dados após os pré-processamentos.

Criando uma variável para observarmos todos os valores através do comando values.
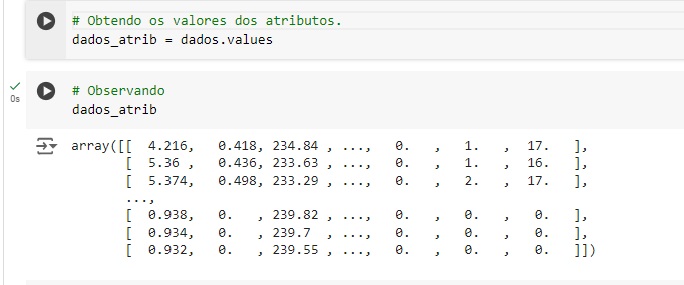
Vamos separar 2% dos nossos dados para treinar o nosso modelo de machine learning e fazer a clusterização, com o comando train_test_split() da biblioteca scikit-learn. Observando o shape, notamos que agora temos 40985 registros e 7 colunas.
PCA (Principal Componente Análise), faz uma redução de dimensionalidade. geralmente é utilizado para banco de dados com muitas variáveis, neste temos apenas 7 variáveis, não seria necessário, mas fica como um conhecimento a mais.
Então, criamos um objeto pca que recebe o pacote PCA com 2 componentes, ou seja, vamos transformar 7 variáveis em apenas 2, as variáveis semelhantes serão agrupadas, então aplicamos o fit_transform() no conjunto de dados amostra1.

Vamos utilizar um algoritmo de machine learning chamado KMeans e vamos passar parâmetros de 1 até 12 para que seja avaliado o melhor valor de número de clusters.

na variável k_means_var vamos passar o número de clusters e fazer o treinamento do pca com as variáveis reduzidas. Isto será executado 12 vezes com a ajuda de um loop for k in k_range.

Agora vamos pegar o centro dos clusters e colocar na variável centroids, ou seja, como foi separado em vários grupos, é marcado um ponto central e vai observando os valores mais próximos daquele ponto.

Calculando a distância Euclidiana para cada ponto do centróide, ou seja, o agrupamento é feito através de distâncias, pois o KMeans utiliza distância Euclidiana; dist é a distância de cada ponto do centróide.

Agora vamos calcular a soma dos quadrados dos clusters, para isso vamos elevar nossa variável dist ao quadrado.



Através da curva de elbow ou curva de cotovelo percebemos que no eixo x temos o número de clusters e no eixo y temos o percentual de variância explicada. Observando o gráfico percebemos que com 8 clusters, conseguimos explicar mais de 90% da variância, ou seja, 8 seria o número ideal para o nosso modelo preditivo. Por isso fizemos todos os cálculos anteriores, para poder gerar este gráfico e obter esta informação.


Criando o nosso modelo, criamos a variável modelo_v1 que recebe o KMeans com o n_clusters que já é um parâmetro do KMeans igual a 8 clusters. Em seguida fazemos o treinamento com o comando fit() que recebe o banco de dados pca que criamos.

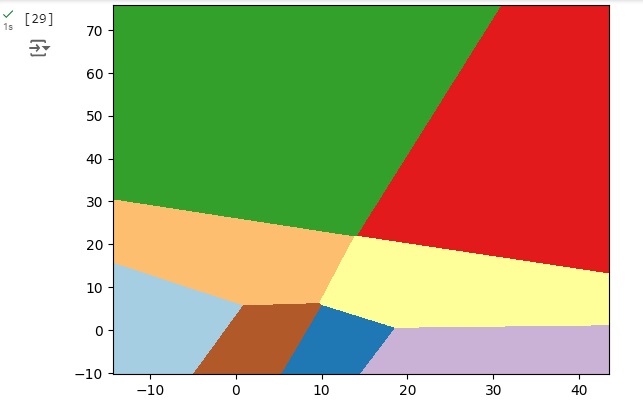
No gráfico abaixo observamos que cada divisão com uma cor diferente equivale a um cluster.

No gráfico abaixo temos os centróides que são representados por cada ‘x’ na cor vermelha.

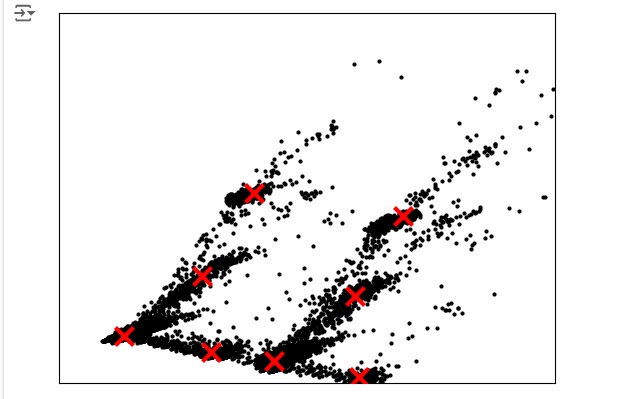
silhouette_score é um método que serve para avaliar a ‘acurácia’ do cluster, como se fosse em um modelo supervisionado, mas como clusters são modelos não-supervisionados, pois não tem variável alvo para fazer a comparação.
Para calcular a silhouette_score, pegamos os labels do modelo que é o que foi gerado de clusters e aplica os dados do pca, os labels e a métrica ‘euclidean’ que é à distância Euclidiana.
Nosso resultado gerado foi 80%.

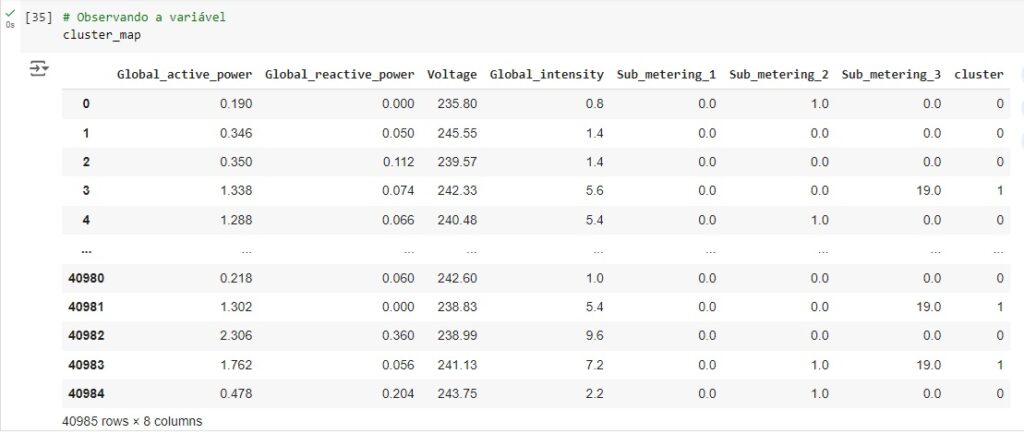
Gerando o resultado final: criamos uma variável com todas as colunas e depois criamos um cluster map. para isso vamos criar um dataframe com os dados e juntando as colunas com os nomes de cada uma. A variável ‘Global_active_power’ vai receber a variável cluster_map e em seguida será criada uma variável chamada ‘cluster’ que vai receber os resultados dos grupos, ou seja, o resultado dos clusters.