Manutenção Preditiva de Motores Turbofan

Sabemos que as aeronaves são muito sensíveis em relação às falhas de seus motores, por isso é muito importante mantê-los em boas condições de funcionamento para a segurança dos passageiros e melhor desempenho da aeronave, pois são equipamentos muito caros e sua manutenção também, então se uma falha não for detectada a tempo pode ficar muito caro reparar os motores ou até mesmo substituí-los.
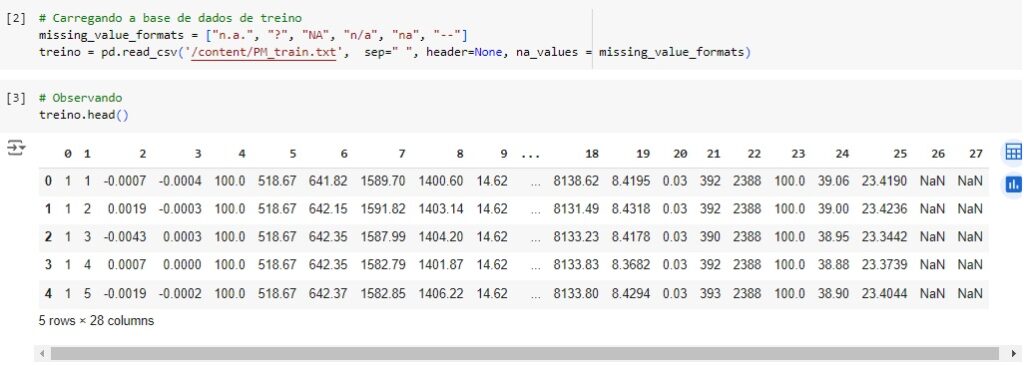
Neste projeto vamos prever o tempo de vida útil restante de um motor aeroáutico turbofan, vamos construir uma rede neural para variáveis dependentes do tempo. O objetivo é prever se o motor irá falhar dentro de um ciclo específico, dado seu histórico de ciclos e dados sensoriais. Os códigos foram desenvolvidos na linguagem Python na plataforma Google Colab.
Vamos importar as bibliotecas.
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
TensorFlow – para criação de redes neurais artificiais.
Vamos carregar os dados de treinamento, onde o último ciclo é o ponto de falha dos motores. Em seguida vamos observá-lo.
Conferindo o shape, percebemos que o banco de dados possui 20631 linhas e 28 colunas.
Com a ajuda do comando info(), obtemos algumas informações e percebemos que existem apenas variáveis do tipo numérico.
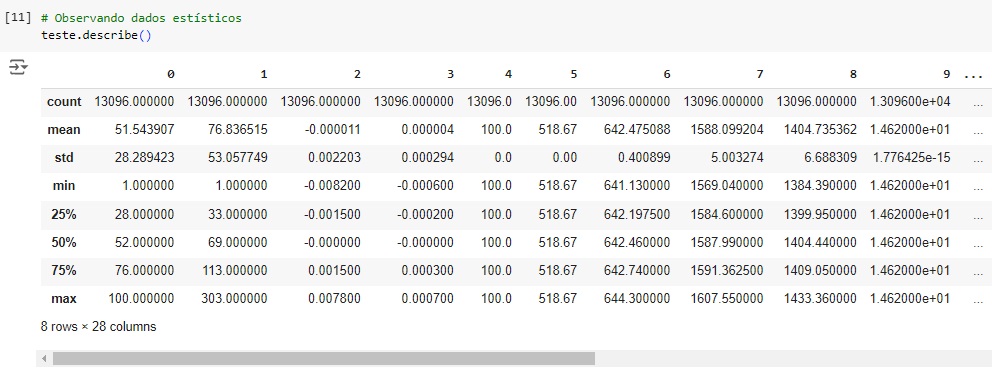
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão.
Carregando a base de teste onde o ponto de falha não é fornecido para os motores.
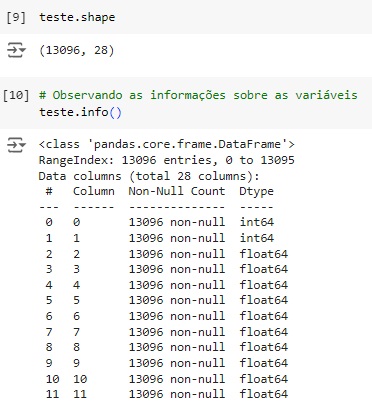
Conferindo o shape, percebemos que o banco de dados possui 13096 linhas e 28 colunas.
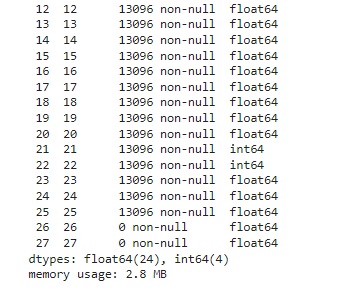
Com a ajuda do comando info(), obtemos algumas informações e percebemos que existem apenas variáveis do tipo numérico.
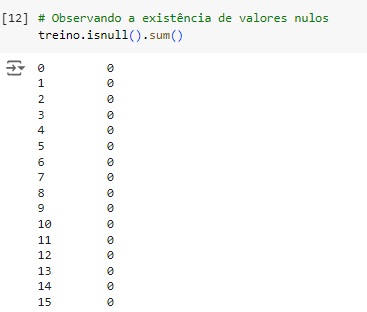
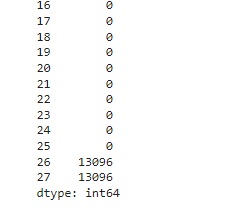
Verificando os valores nulos com o comando isnull().sum(). Podemos observar que todos os valores são nulos nas colunas 26 e 27 da base de treino.
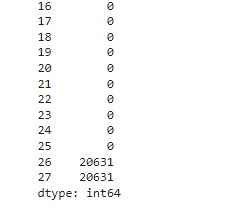
Percebemos a mesma coisa na base de teste.
Vamos excluir as colunas com os valores nulos em ambos os datasets.
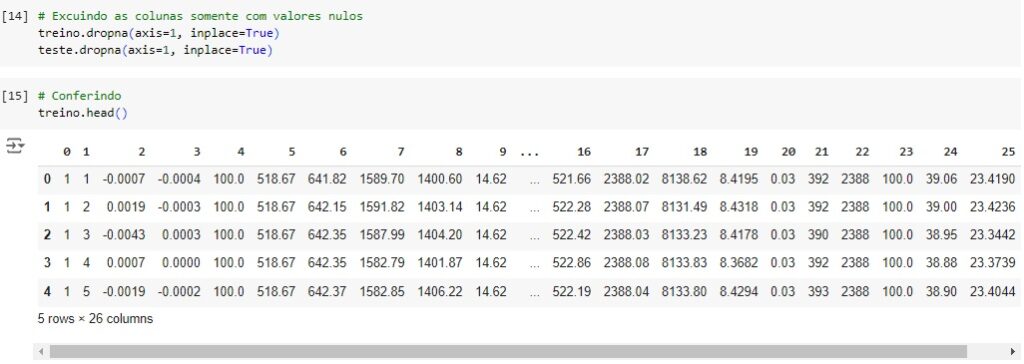
Vamos renomear algumas colunas para facilitar a identificação.
Vamos classificar o conjunto de dados por ID e ciclos para que cada mecanismo possa ter seus valores classificados e armazenados em um só lugar, para isto vamos usar o sort_values().
Primeiro encontramos os ciclos máximos observados para cada motor usando o groupby() e depois mesclamos esses valores para os respectivos dados do motor usando merge().
Agora vamos calcular o RUL que é a vida útil restante subtraindo o valor do ciclo atual do valor máximo. Por exemplo: um ciclo tem vida total de 200 ciclos e já executou 47 ciclos, portanto seu RUL = 200 – 47.
Vamos dropa a coluna ‘max’ porque não iremos mais precisar dela. E vamos observar.
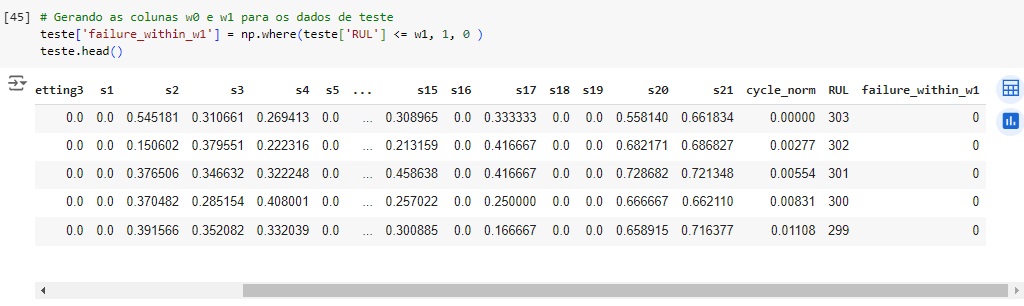
Vamos gerar a variável alvo para a classificação, vamos classificar os ciclos próximos da falha com seus respectivos ids na variável alvo ‘failure_within_w1’. O w1 significa window 1 ou janela 1 que terá o valor 30 mas pode ter outro valor dependendo da empresa da aeronave, etc.
Gerando coluna de rótulos para variável de treino. Vamos criar uma variável para indicar se o motor vai falhar dentro dos ciclos w1 = 30.
Em seguida vamos normalizar algumas variáveis para colocá-las na mesma escala, vamos utilizar o MinMaxScaler() e o fit_transform() para isso.
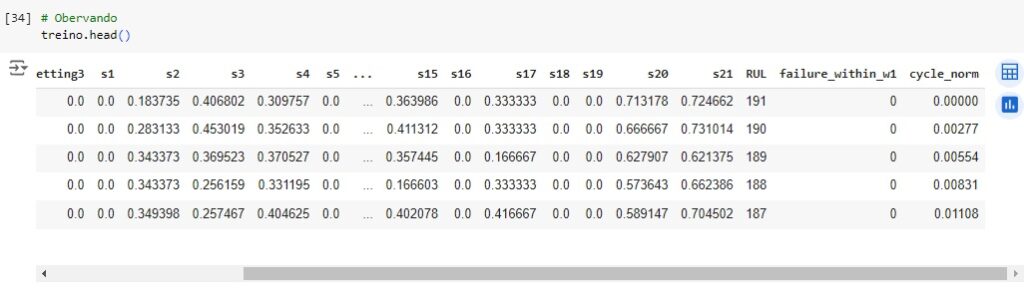
Normalizando agora a base de teste.
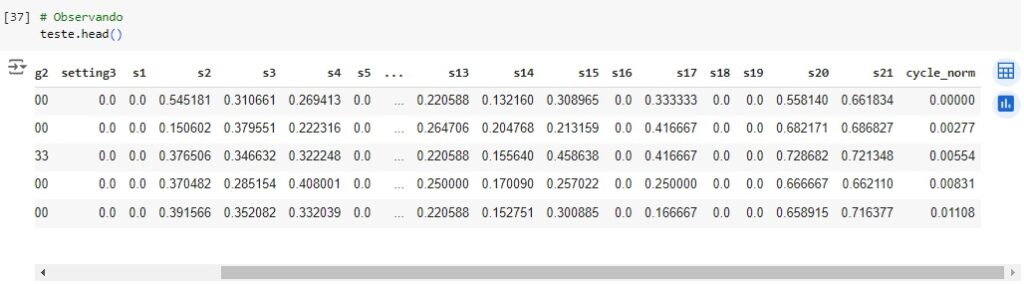
Agora vamos carregar a base de teste com os dados reais que indica os ciclos úteis restantes dos motores. E vamos observar, e notamos que temos uma coluna com valores nulos.
Vamos deletar esta coluna. Agora vamos calcular o RUL total somando os ciclos máximos dados no conjunto de teste e os dados verdadeiros.
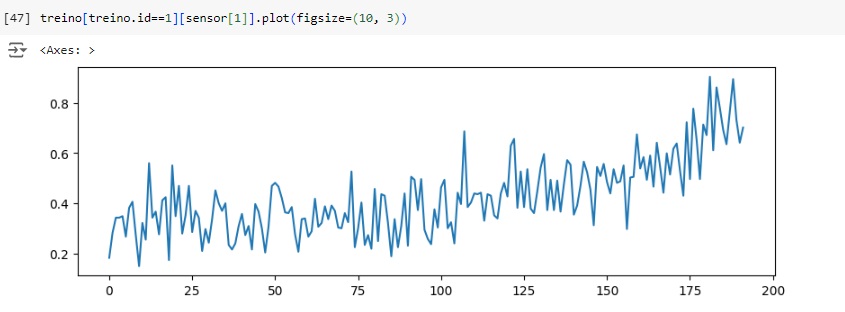
Vamos observar como os valores dos sensores mudam para um ID de mecanismo específico, por exemplo id = 1.

Aqui notamos que os valores do sensor 1 aumentam, quando o ciclo do número aumenta.
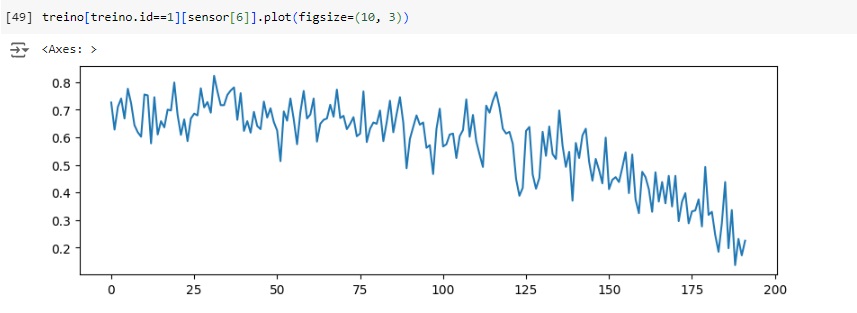
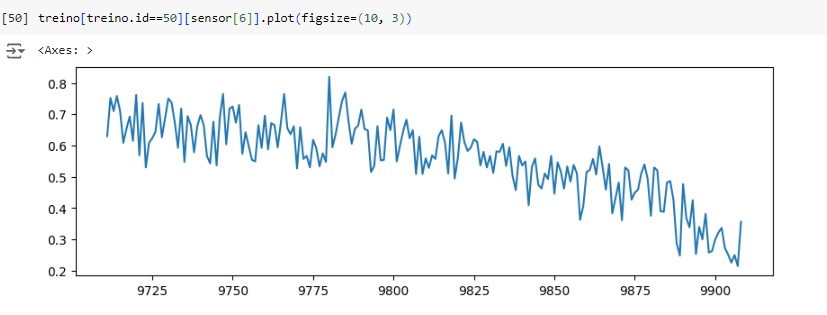
Já os valores do sensor 6 diminuem quando o ciclo de números aumenta.
A maioria dos outros sensores apresentam uma tendência crescente ou decrescente.
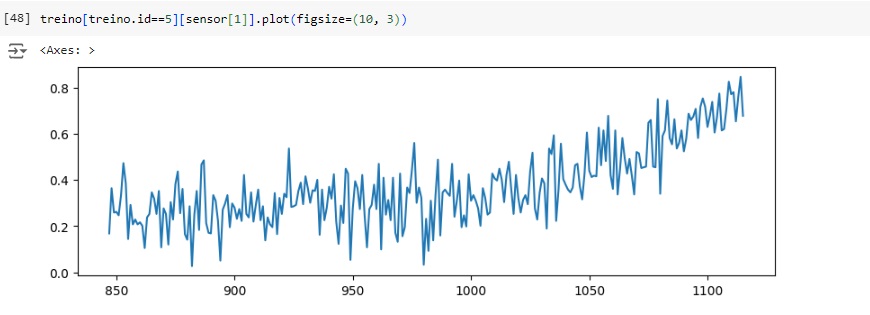
Observamos o sensor 6 para ID 1 e ID 50, notamos que ambas as observações apresentam tendências decrescentes com ciclos crescentes, com isso, podemos ver que quando os valores dos sensores se aproximam de um determinado valor, a aeronave pode deixar de funcionar.
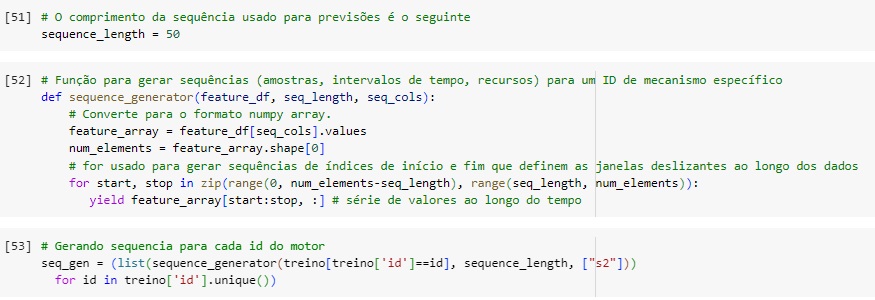
Gerando a sequência de entrada.
Queremos gerar sequências de 50 passos de tempo por vez e vamos iterar sobre dois conjuntos de índices (0.142), (50.192). Por exemplo, ID 1 possui 192 linhas e seu comprimento sequencial ‘seq_length’ é igual a 50.
Em seguida vamos gerar a sequência para cada ID de mecanismo. Vamos usar o unique() para retornar todos os IDs exclusivos de uma lista.
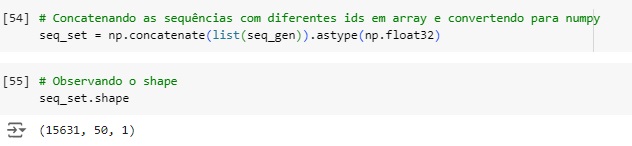
Vamos concatenar as sequências e observar o shape, notamos que temos número de amostras, número de intervalos de tempo e número de recursos.
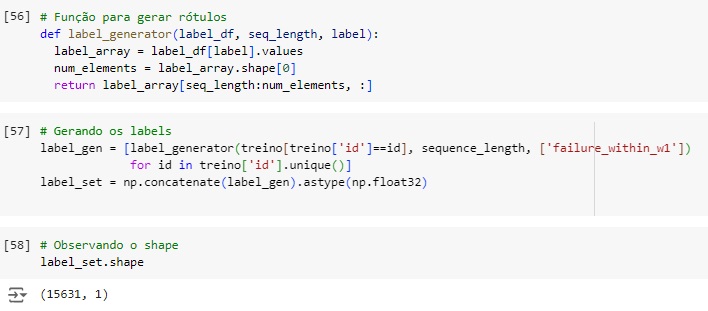
Vamos criar uma função para para gerar rótulos (labels) de uma sequência de dados para a rede neural para garantir que os rótulos estejam alinhados corretamente com as janelas de sequência de entrada que foram geradas anteriormente.
Vamos considerar os dados dos 21 sensores e de 3 configurações (settings), Isso levará os 25 recursos no conjunto de sequência de entrada.
Em seguida vamos gerar a sequência para cada ID de mecanismo, unique() retorna todos os IDs exclusivos de uma lista.
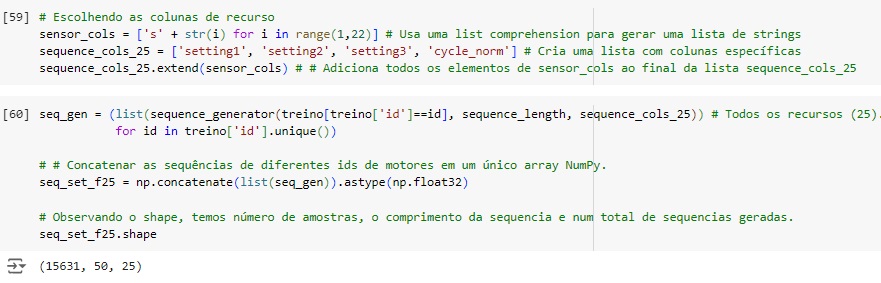
As variáveis ‘features_dim’ e ‘out_dim’ são usadas para definir as dimensões das entradas e saídas do modelo de rede neural que vamos construir.
Vamos construir a rede neural.
LSTM Layers: Camadas LSTM são usadas para capturar dependências temporais nas sequências de dados.
input_shape = (sequence_length, features_dim): Define o formato da entrada, onde sequence_length é o comprimento da sequência e features_dim é o número de características (25 no caso).
units = 64: Define o número de unidades LSTM (neurônios) na camada.
return_sequences = True: Indica que a camada deve retornar toda a sequência de saída (não apenas o último passo de tempo), necessário para passar a sequência completa para a próxima camada LSTM.
kernel_regularizer = l2(0.01): Adiciona regularização l2 para ajudar a prevenir overfitting.
Dropout(0.3): Define uma camada Dropout que desativa aleatoriamente 30% dos neurônios durante o treinamento para ajudar a prevenir overfitting.
BatchNormalization(): Normaliza a saída da camada anterior para estabilizar e acelerar o treinamento.
A segunda camada se assemelha a primeira, mas sem as entradas.
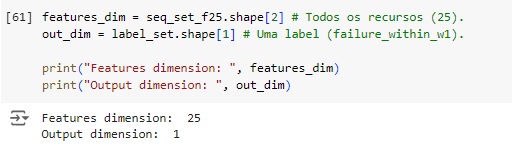
Vamos para a terceira camada.
units = 32: Define 32 unidades LSTM.
return_sequences = False: Indica que apenas a saída do último passo de tempo deve ser retornada, adequado para a camada final LSTM antes da camada de saída.
Camada de saída densa.
Dense Layer with Sigmoid Activation: A camada de saída com ativação sigmoid fornece probabilidades para a classe de saída, adequada para classificação binária.
units = out_dim: Define o número de neurônios na camada de saída (igual ao número de classes de saída).
activation =’ sigmoid’: Utiliza a função de ativação sigmoid, adequada para problemas de classificação binária ou multi-label (várias saídas binárias).

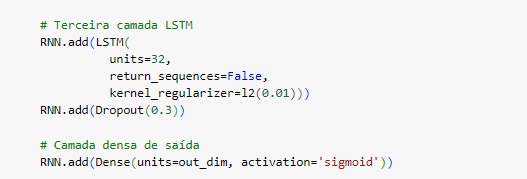
Compilando a rede neural.
loss=’binary_crossentropy: A função de perda é binary_crossemtropy, que é usada para problemas de classificação binária. Ela mede a diferença entre as distribuições de probabilidade previstas e reais. A binary_crossemtropy é apropriada quando a saída é uma probabilidade (por exemplo, valores entre 0 e 1, que é o caso quando se usa a função de ativação sigmoid na camada de saída).
optimizer=’adam’: O otimizador usado é o adam (Adaptive Moment Estimation). O adam é amplamente utilizado em redes neurais por sua eficiência e boa performance em muitos tipos de problemas. Ele combina as vantagens dos otimizadores AdaGrad e RMSProp e ajusta as taxas de aprendizado individualmente para cada parâmetro.
metrics=[‘accuracy’]: As métricas para avaliação do modelo incluem a accuracy (precisão). A precisão mede a fração de previsões corretas entre o total de previsões feitas. É uma métrica comum e intuitiva para classificação, especialmente quando as classes são balanceadas.


Salvando o modelo e iniciando o treinamento com o comando fit() e alguns parâmetros detalhas abaixo:
seq_set_f25: Conjunto de dados de entrada, uma matriz de sequências temporais dos sensores e ajustes.
label_set: Conjunto de rótulos correspondente às entradas, indicando se a falha ocorrerá dentro da janela especificada.
epochs=epochs: Número de épocas para treinar o modelo. Uma época é uma passagem completa pelos dados de treinamento.
batch_size=batch_size: Número de amostras por atualização de gradiente. Isso define o tamanho do lote durante o treinamento.
validation_split=0.05: Fração dos dados de treinamento a ser usada como dados de validação. Nesse caso, 5% dos dados serão usados para validação.
verbose=2: Define o nível de verbosidade durante o treinamento. O nível 2 exibe uma linha por época.
Callbacks são funções que podem ser aplicadas em diferentes pontos durante o treinamento. Aqui, dois callbacks são usados:
keras.callbacks.EarlyStopping: Monitora a métrica val_loss (perda na validação).
min_delta=0: Mudança mínima na métrica para qualificar como uma melhora.
patience=10: Número de épocas com pouca ou nenhuma melhoria após a qual o treinamento será interrompido.
mode=’min‘: O treinamento parará quando a métrica monitorada parar de diminuir.
keras.callbacks.ModelCheckpoint: Salva o modelo após cada época se houver uma melhora na métrica monitorada (val_loss).
save_best_only=True: Apenas o melhor modelo será salvo.
mode=’min’: Salva o modelo quando a métrica monitorada diminui.
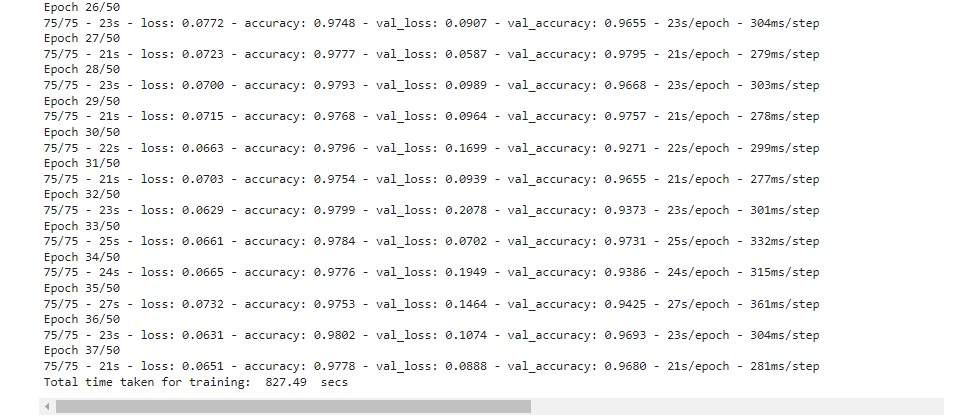
Função para plotar a evolução da acurácia de um modelo durante o treinamento e a validação.

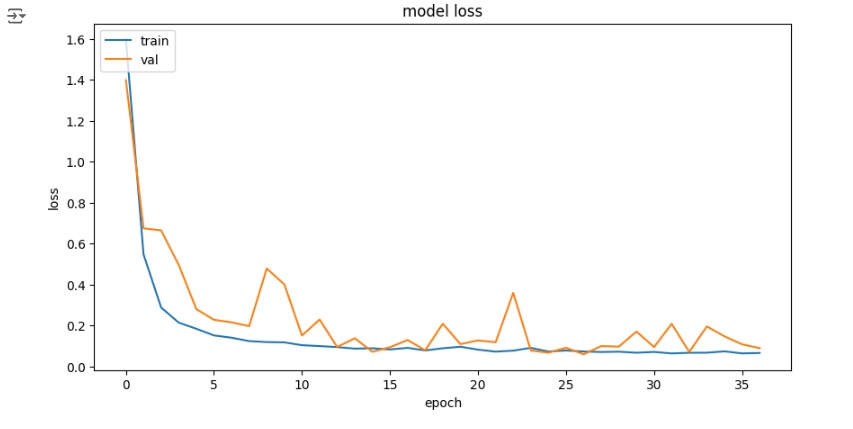
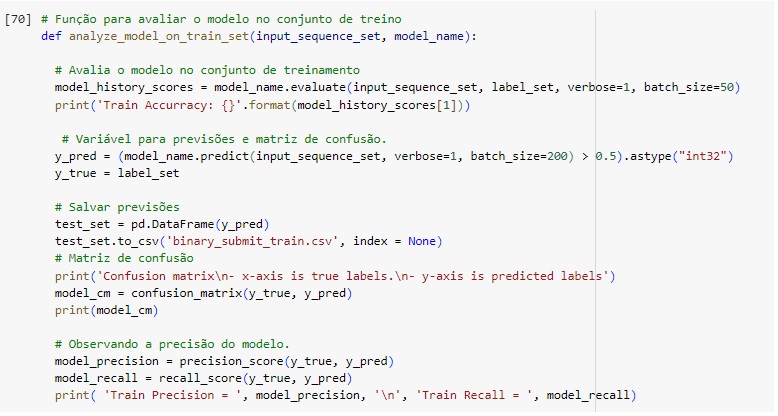
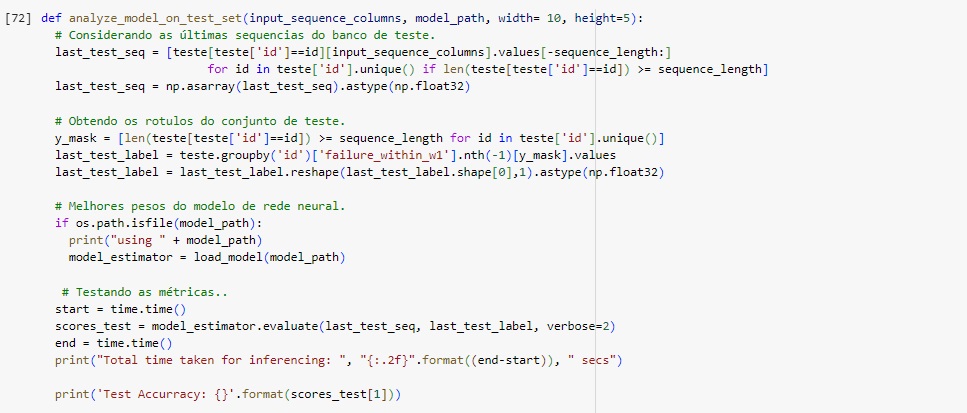
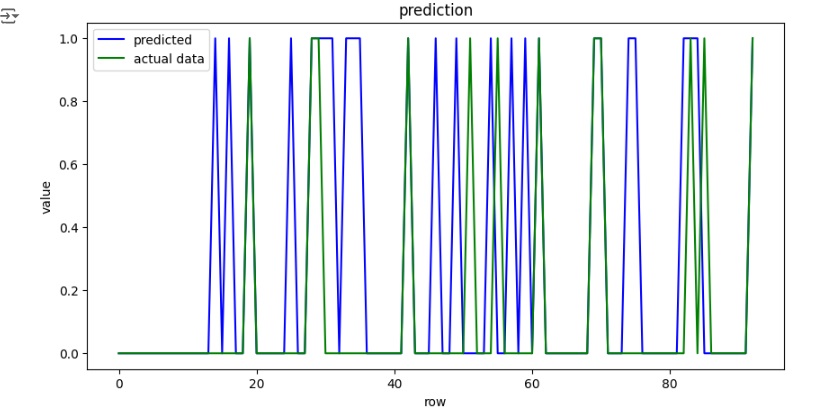
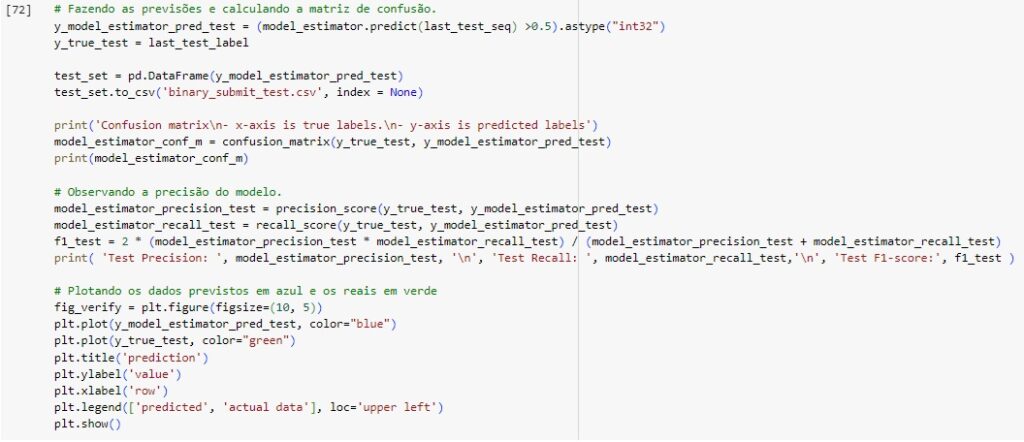
Função para observar as previsões em comparação com os dados reais.
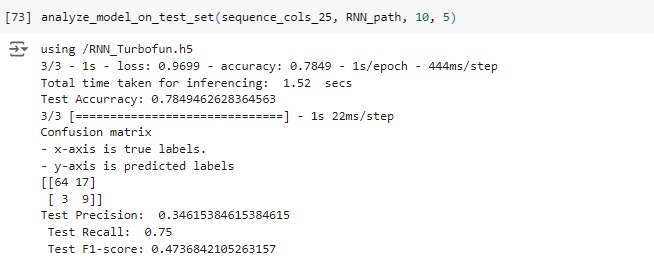
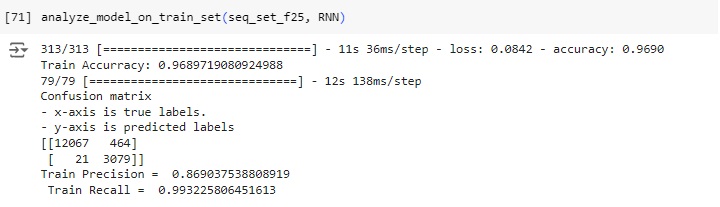
Podemos observar que a acurácia do modelo é de 78.49%, o que significa que o modelo acertou esta porcentagem no conjunto de teste.
Analisando a matriz de confusão:
TN (64): O modelo previu corretamente a classe negativa (0) em 64 casos.
FP (17): O modelo previu incorretamente a classe positiva (1) em 17 casos quando a classe real era negativa (0).
FN (3): O modelo previu incorretamente a classe negativa (0) em 3 casos quando a classe real era positiva (1).
TP (9): O modelo previu corretamente a classe positiva (1) em 9 casos.