Modelo Preditivo de Score de Crédito Com Python

Neste post vamos mostrar um projeto de machine learning para prever o score de crédito de clientes de um banco. Vamos mostrar desde o tratamento da base de dados até a aplicação do modelo de regressão linear e os testes. O algoritmo foi desenvolvido na plataforma Google Colab. Vamos para a implementação:
Vamos começar importando as bibliotecas:
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;

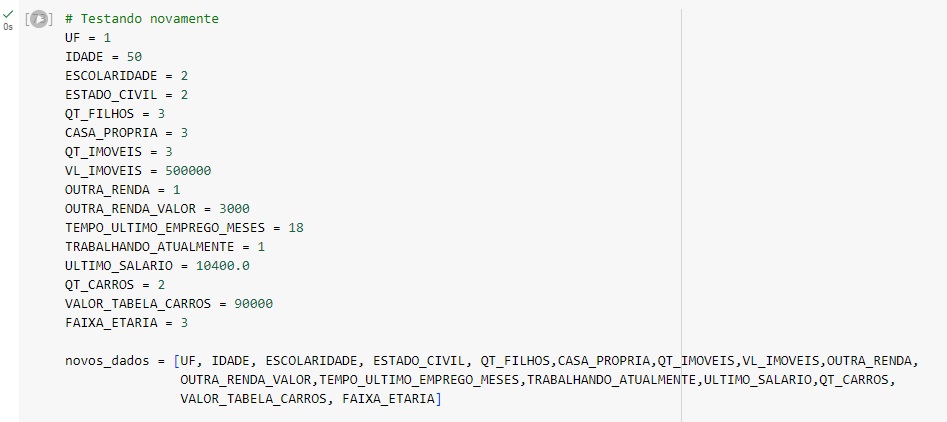
Carregando a base de dados e observando o shape, podemos ver que o este banco de dados possui 10476 linhas e 17 colunas.

Através do comando head() vamos observar os 5 primeiros valores.


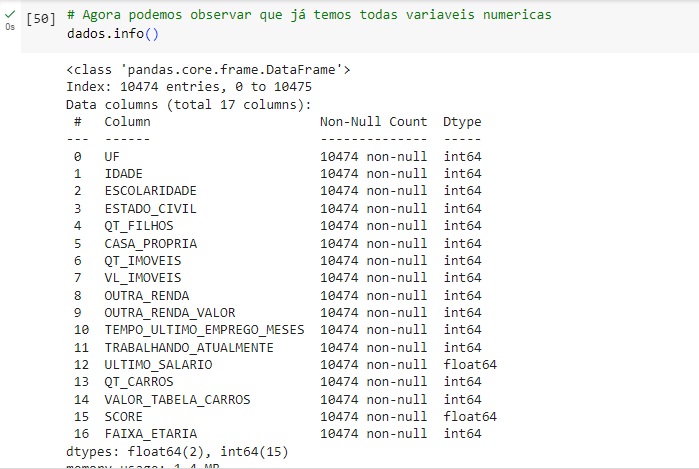
Com o comando info(), podemos verificar algumas informações sobre os dados, como tipos de variáveis, percebemos que algumas estão como object ou seja, são variáveis categóricas que não são numéricas, e para aplicar o modelo de machine learning as variáveis precisam ser numéricas, pois os modelos não interpretam palavras, apenas números, portanto faremos esta transformação mais adiante. Temos também a variável ‘CODIGO_CLIENTE’ que não será utilizada para o modelo preditivo, portanto iremos excluí-la no próximo comando.
Utilizando o comando drop() iremos excluir a variável ‘CODIGO_CLIENTE’, axis = 1 para excluir a coluna e o inplace = True é para atualizar o banco de dados.

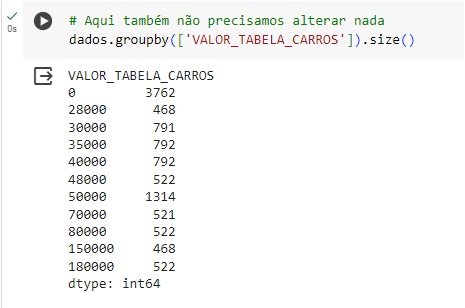
Com o groupby() vamos agrupar os valores e observar a variável ‘ULTIMO_SALARIO’ e analisar como os salários estão divididos. Podemos observar que 1800 reais é a renda de 846 clientes, 2200 é a renda de 792 cliente e assim por diante.
Mas na última informação podemos observar que ao invés de mostrar o valor do salário, mostra a informação ‘SEM DADOS’.

Vamos substituir ‘SEM DADOS’ por um valor nulo, para isso vamos usar o comando replace() que manipula strings e o np.nan irá transformar o SEM DADOS em um valor nulo.

Agora vamos converter para o formato numérico float64 com o comando astype().
Com o comando isnull().sum(), vamos observar a quantidade de valores nulos e percebemos que na variável ‘ULTIMO_SALARIO’ existem 3 valores nulos.

Os valores nulos vamos substituir pela mediana, através do comando fillna().median(), foi escolhido a mediana pois é uma medida estatística que distorce menos dos outros valores.
Em seguida observamos os valores e percebemos que não existem mais valores nulos.
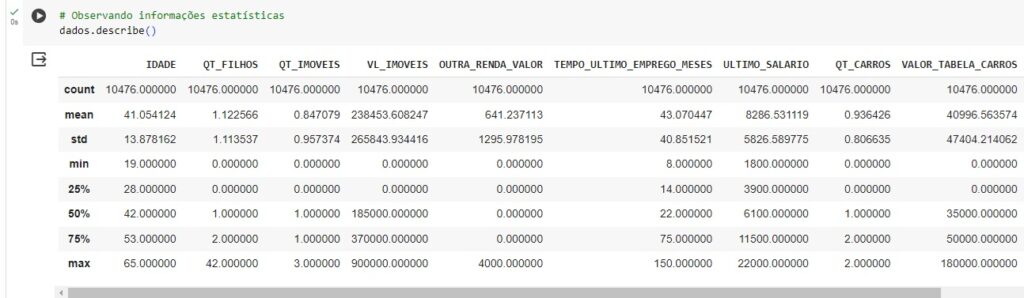
Vamos observar algumas informações estatísticas como média, desvio padrão, mediana, com o comando describe().
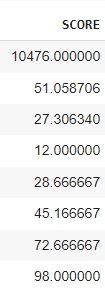
Vamos observar os outliers que são valores discrepantes que estão muito acima ou muito abaixo dos outros.

Vamos criar um boxplot para observar melhor os outliers. Os pontinhos pretos que aparecem nos gráficos são os outliers.

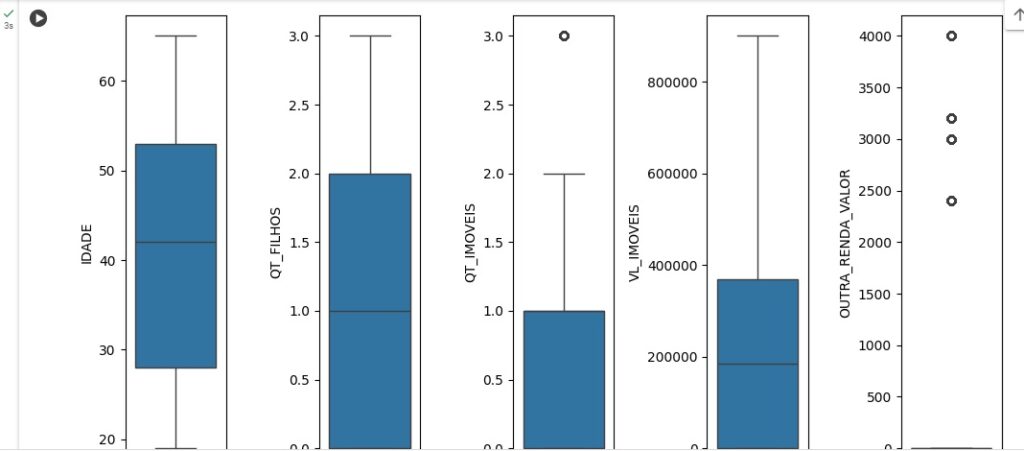

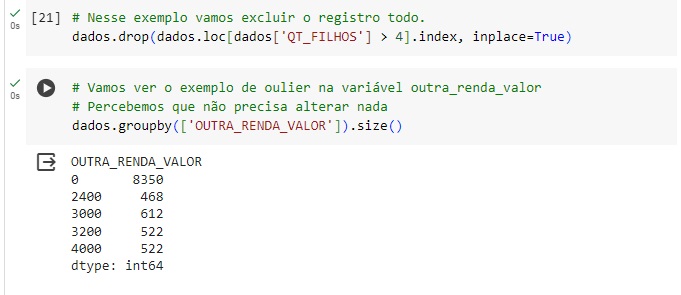
Aqui percebemos que na variável ‘QT_FILHOS’, temos 2 outliers, pois temos uma pessoa com 3 filhos e outra com 42.

Com a ajuda do comando drop() vamos excluir estes registros.




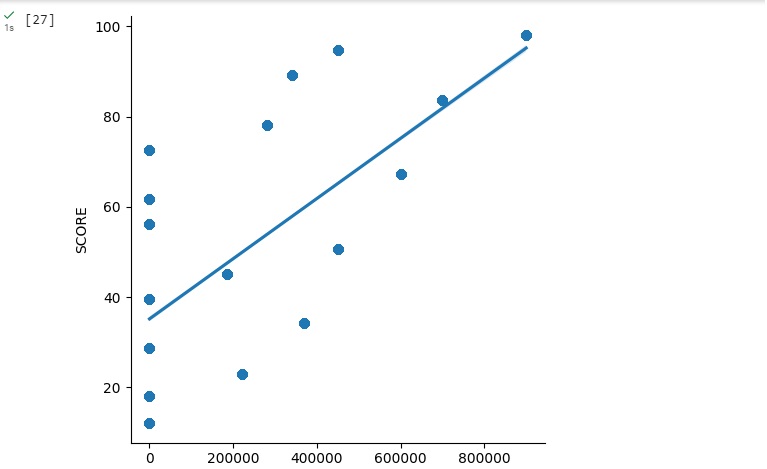
Agora vamos observar a correlação entre o valor do imóvel ‘VL_IMOVEIS’ que está no eixo x do gráfico com o score ‘SCORE’ que está no eixo y do gráfico




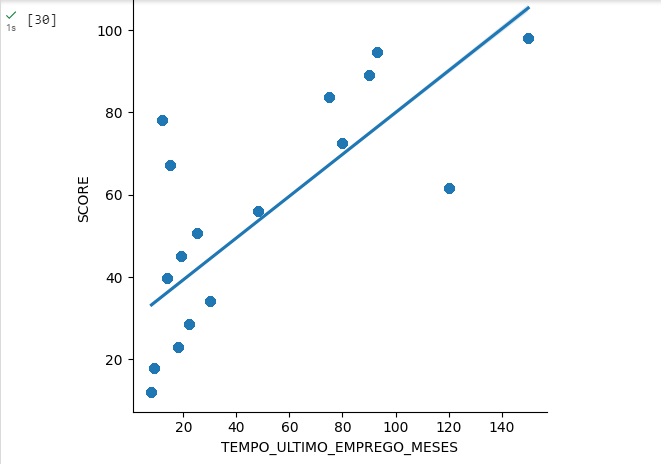
Vamos observar o cliente com a menor e com a maior idade do banco de dados. Percebemos que o cliente mais no tem 19 anos e o mais velho 65 anos.

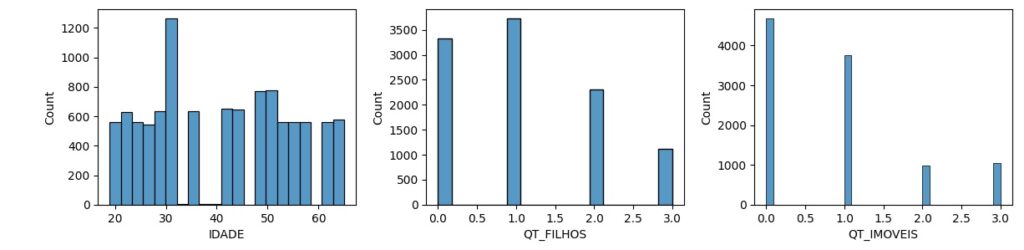
Vamos criar uma nova variável, ou seja, uma nova coluna no banco de dados chamada ‘FAIXA_ETARIA’ a partir da variável ‘IDADE’. Para isso vamos criar separações (bins) com 4 categorias.
Notamos que até 30 anos temos 3552 pessoas, maior que 50 temos 2448 pessoas e assim por diante.

Agora vamos criar uma lista com as variáveis categóricas, ou seja, aquelas que não são numéricas.
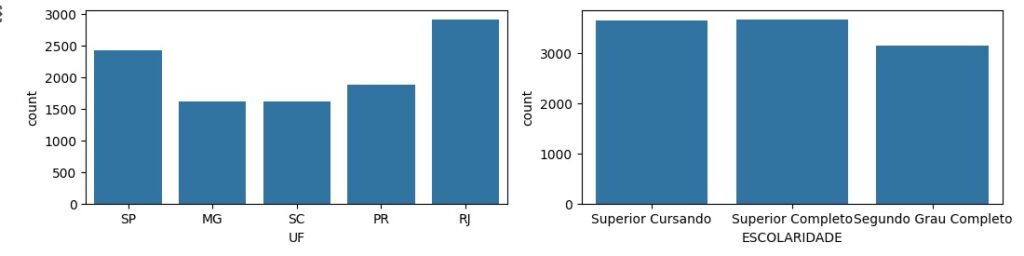
Observando graficamente as variáveis categóricas.
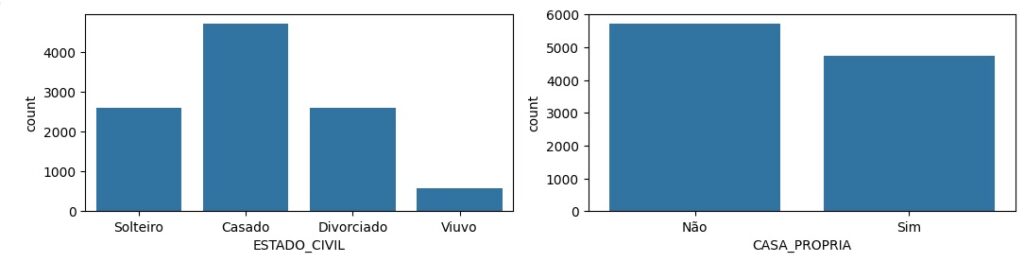
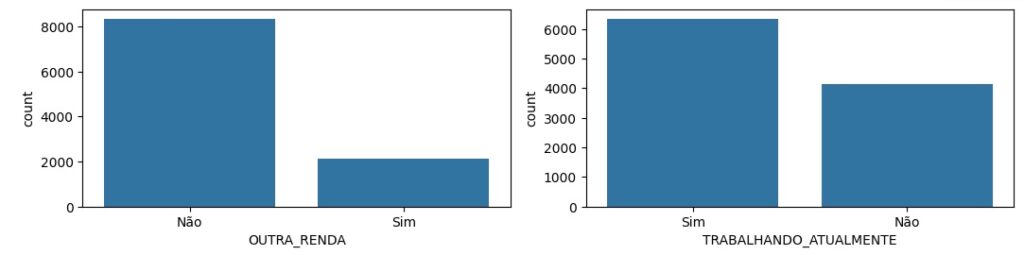
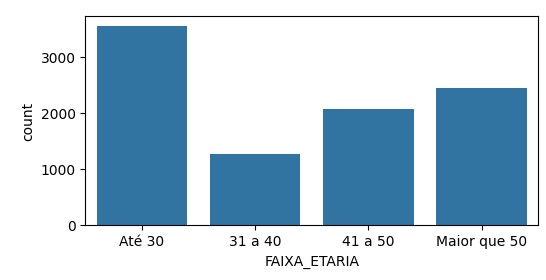
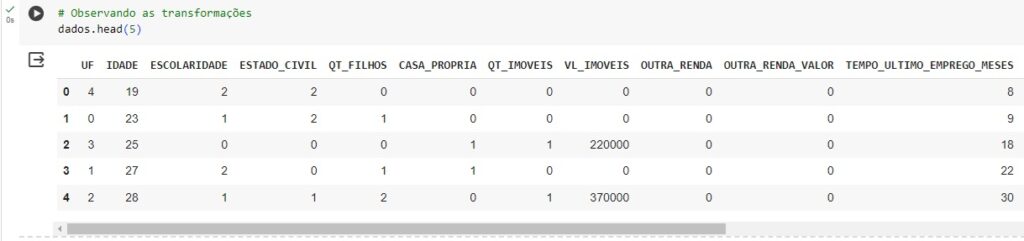
Nesta etapa vamos pré processar os dados. Utilizando o OneHotEncoder, através do LabelEncoder() vamos transformar as variáveis categóricas em um números. Por exemplo: Até 30 anos transforma em 0, de 31 a 40 anos transforma em 1 e assim por diante.
Então usaremos o lb.fit_transform() nas variáveis que queremos transformar.

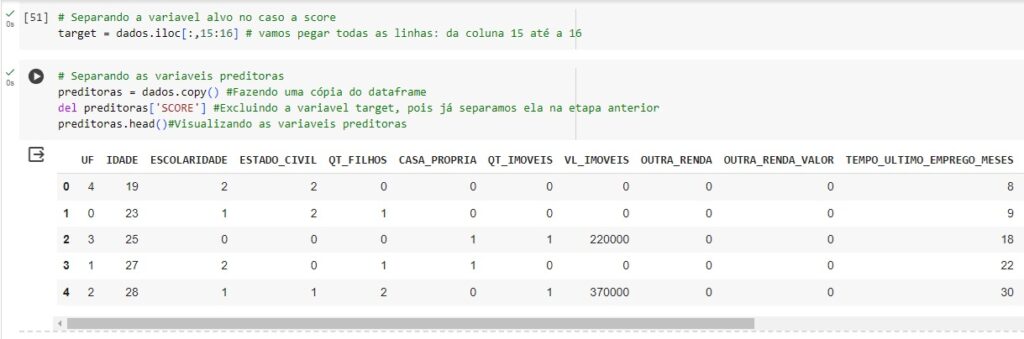
Agora vamos separar a variável ‘SCORE’ que é a nossa variável alvo, no caso é a variável que queremos fazer as previsões e vamos separá-la das variáveis preditores.
Para isso vamos criar um novo banco de dados sem a variável alvo chamada preditoras.
Dividindo o banco de dados em base de treino e de teste, no caso vamos separar 70% dos valores para treino através das variáveis x_treino e y_treino e 30% do valores para teste no caso x_teste e y_teste. Sendo que passaremos para o algoritmo de machine learning apenas as variáveis de treino. As de teste será para ver a acurácia do modelo. Vamos fazer esta divisão com a ajuda da função train_test_split(). O comando test_size = 0.3 significa a separação dos 30% da base de dados de teste.

Agora vamos fazer a normalização do dados, ou seja, deixar os dados na escala entre 0 e 1.

Treinando o modelo com o LinearRegression() e a função fit()

Observamos que nosso modelo teve 79,8% de acurácia.

Simulando alguns testes.