Modelo Preditivo Para Identificar Insuficiência Cardíaca

Mais um modelo de machine learning, desta vez vamos classificar se uma pessoa possui ou não insuficiência cardíaca utilizando o algoritmo Random Forest. O algoritmo foi desenvolvido na plataforma Google Colab utilizando linguagem Python. Antes de implementarmos os código vamos ver algumas informações sobre o nosso banco de dados:
1 – Age: idade do paciente em anos;
2 – Sex: sexo do paciente [M: Masculino, F: Feminino];
3 – ChestPainType: tipo de dor torácica [TA: Angina típica, ATA: Angina atípica, NAP: Dor não anginosa, ASY: Assintomática];
4 – ResgingBP: pressão arterial em repouso [mm Hg];
5 – Cholesterol: colesterol sérico [mm/dl];
6 – FastingBS: glicemia em jejum [1: se BS em jejum > 120 mg/dl, 0: caso contrário];
7 – ResgingECG: resultados do eletrocardiograma em repouso [Normal: Normal, ST: com anormalidade das ondas ST-T (inversões das ondas T e/ou elevação ou depressão de ST > 0,05 mV), HVE: mostrando hipertrofia ventricular esquerda provável ou definitiva pelos critérios de testes];
8 – MaxHR: frequência cardíaca máxima alcançada [valor numérico entre 60 e 202];
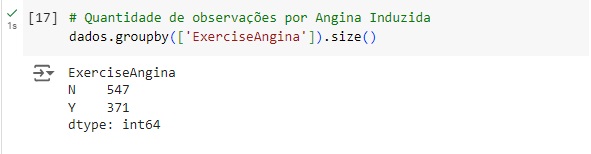
9 – ExercícioAngina: angina induzida por exercício [Y: Sim, N: Não];
10 – Oldpeak: oldpeak = ST [Valor numérico medido na depressão];
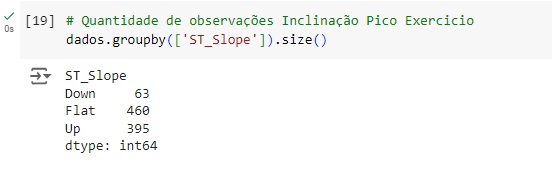
11 – ST_Slope: a inclinação do segmento ST do pico do exercício [Up: subida, Flat: flat, Down: downsloping];
12 – HeartDisease: classe de saída [1: Doença Cardíaca, 0: Normal]. Variável TARGET.
Vamos para a implementação. Começamos importando as bibliotecas:
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Time – para funcionalidades referente ao tempo.
Agora vamos carregar a base de dados e observá-la.

Observando o shape notamos que a base de dados possui 918 linhas e 12 colunas.

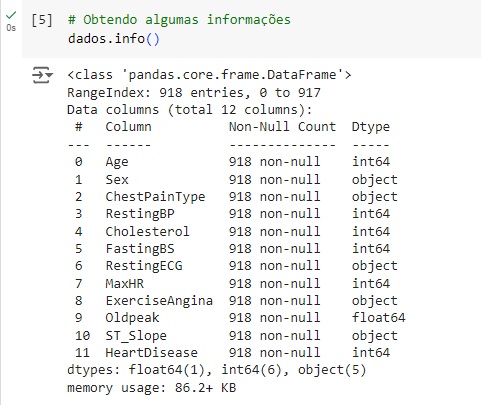
Com a ajuda do comando info(), obtemos algumas informações informações e percebemos que existem variáveis do tipo object, que mais adiante serão tratadas.
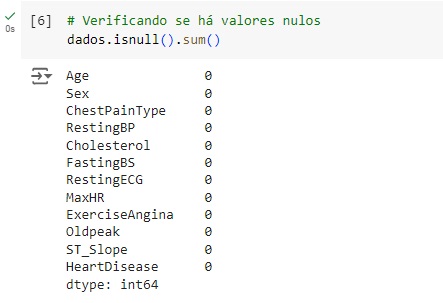
Verificando os valores nulos e contando os mesmos utilizando o comando isnull().sum(). Podemos observar que não existem valores nulos no banco de dados.
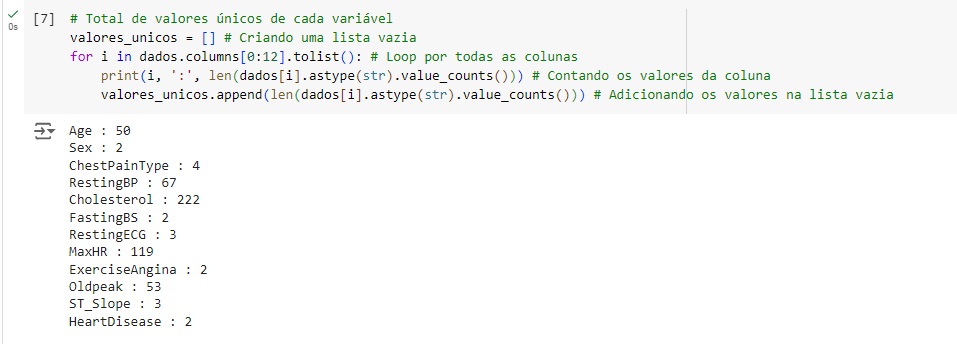
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão. Também podemos notar que os dados estão em diversas escalas, logo mais iremos padronizar estes dados.
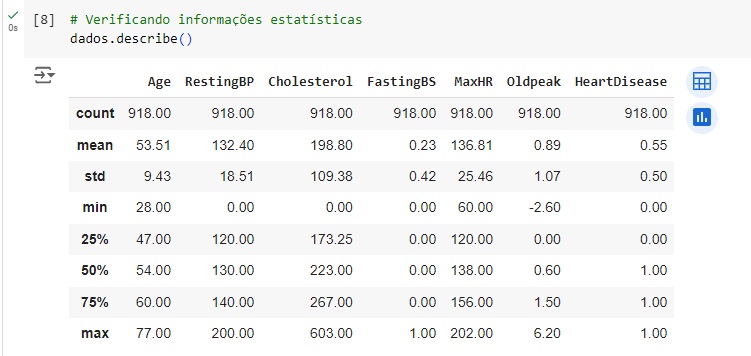
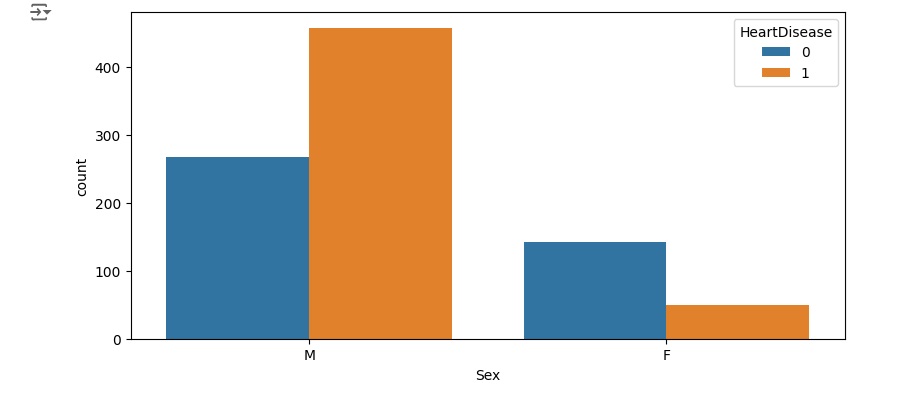
Com o comando groupby(), faremos um agrupamento de uma variável e com o comando size() vamos contar os valores. Na variável Sex temos 193 registros de pessoas do sexo feminino e 725 do sexo masculino.

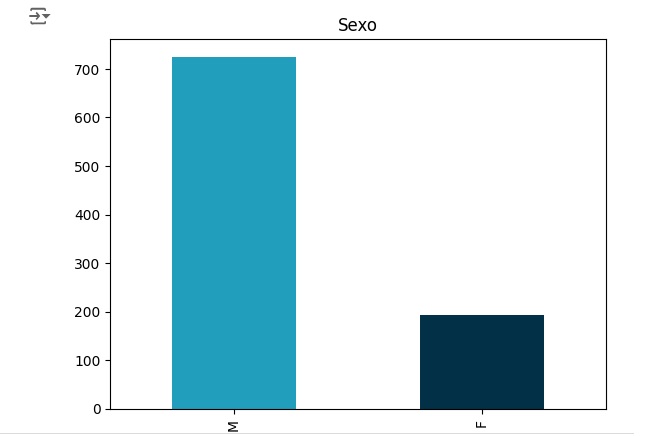
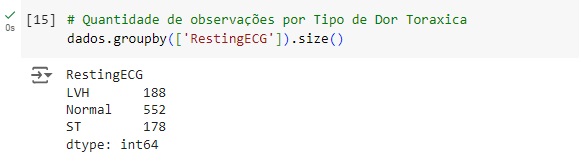
Vamos fazer a mesma análise para a variável ChestPainType, podemos perceber que 496 pessoas estão assintomáticas (ASY), 173 pessoas estão com angina atípica (ATA), 203 apresentam dor não anginosa (NAP) e 46 apresentam angina típica.
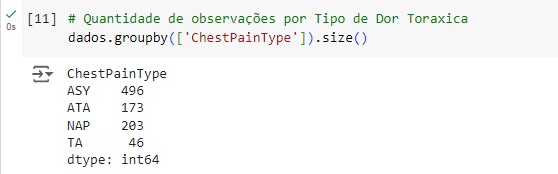


Pela variável FastingBS observamos que 704 pessoas tem a glicemia em jejum < 120 mg/dl e 214 tem glicemia em jejum > 120 mg/dl.
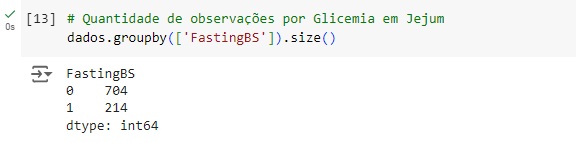


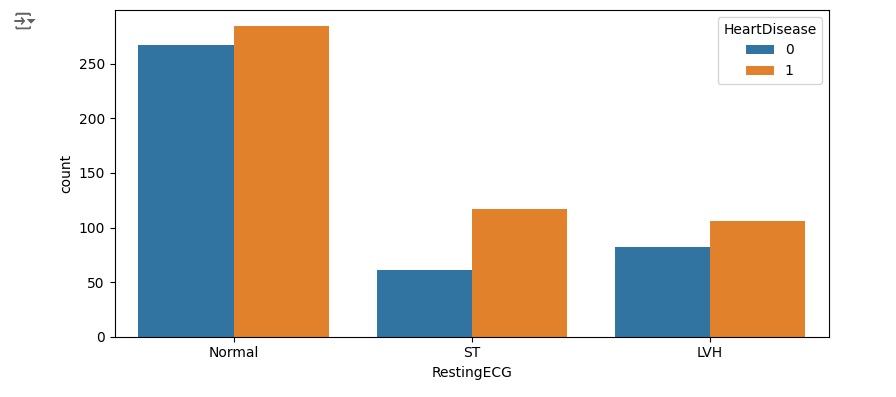
Na variável RestingECG vemos que 188 pessoas



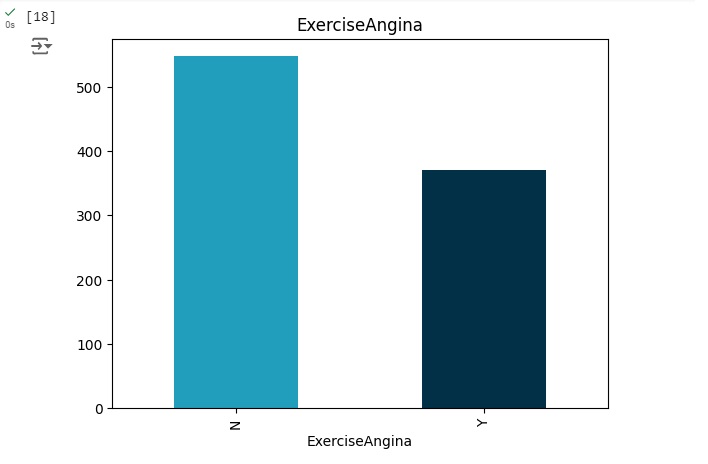

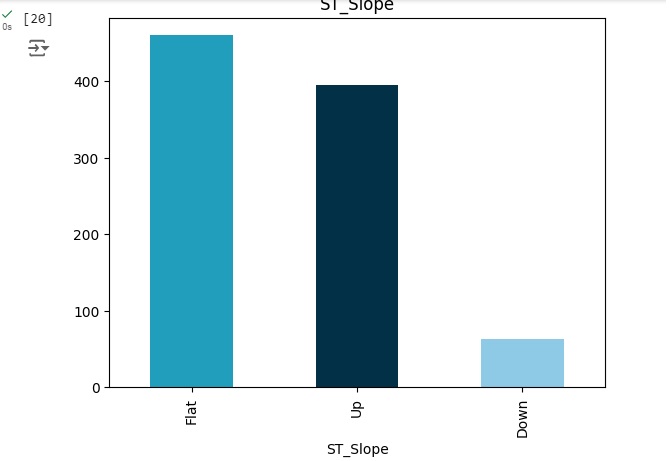


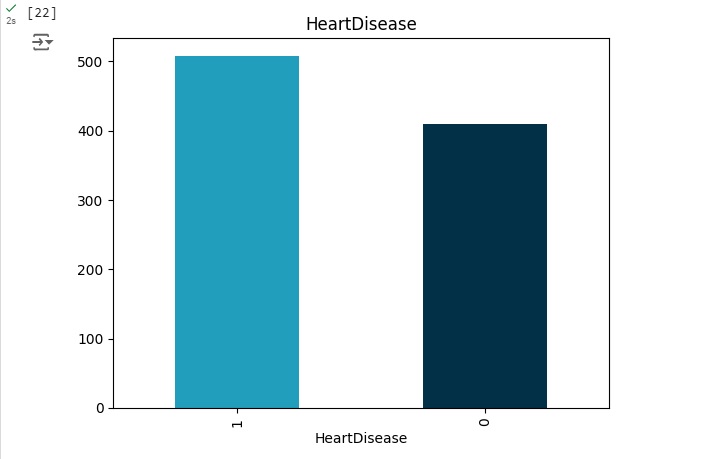
Preparando a geração do gráfico para visualizarmos por sexo as alterações cardíacas.

Temos como parâmetro 0 = normal e 1 = doença cardíaca.
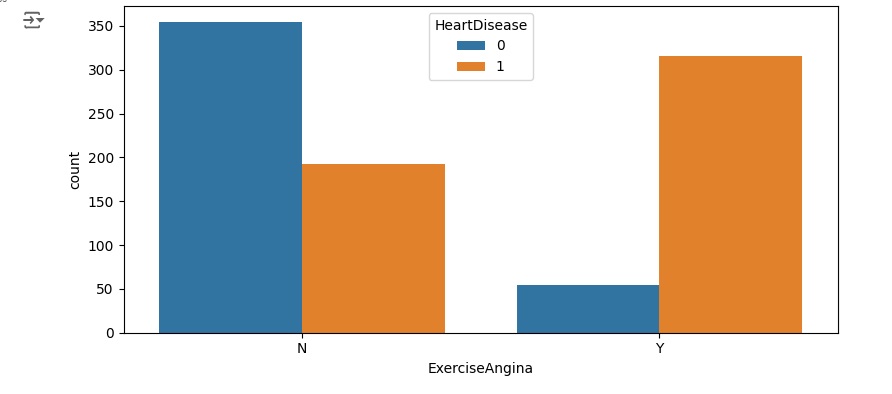
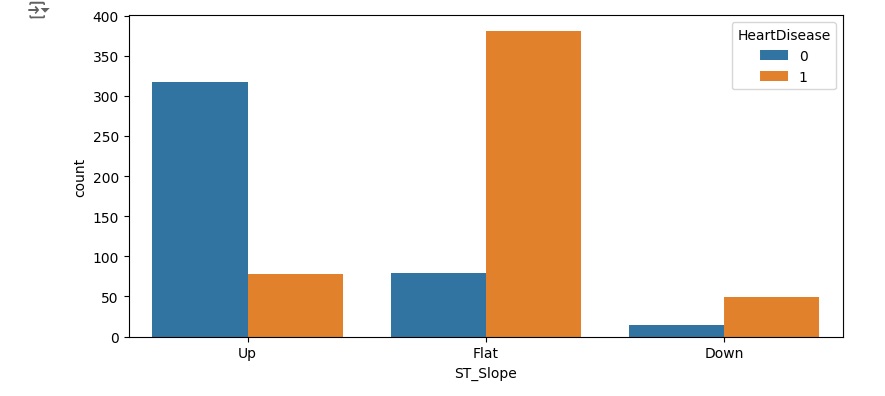
Podemos perceber que entre os homens a grande maioria tem alguma alteração cardíaca, e entre as mulheres bem poucas. Nos outros gráficos, podemos observar outras análises.








Vamos converter as variáveis object para category para reduzir o valor de memória utilizado, para isso, vamos utilizar o comando astype().

Analisando as variáveis numéricas, com a ajuda do comando len() notamos que existem 5.

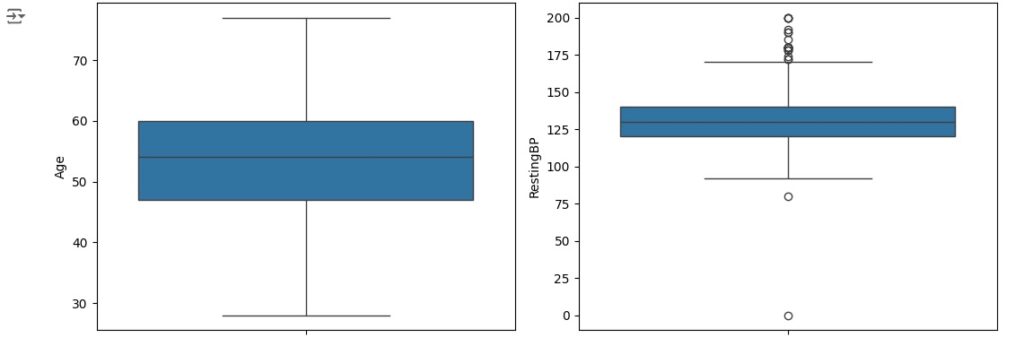
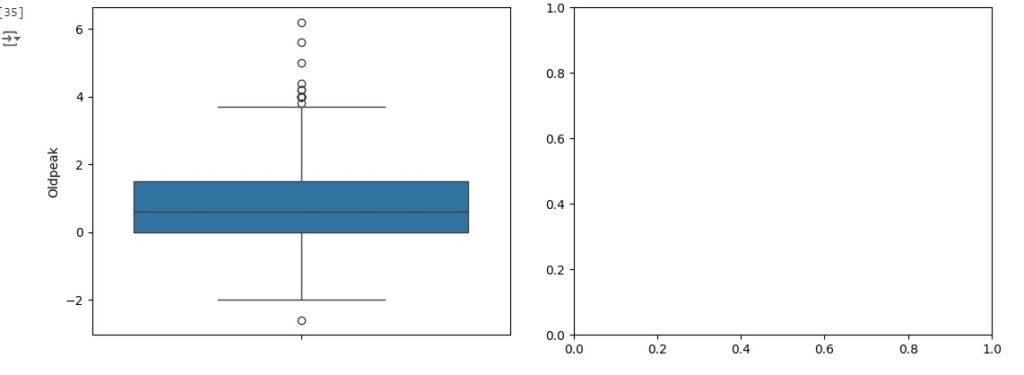
Vamos criar um boxplot para observar outliers que são os valores discrepantes. Os outliers são os pontos escuros que aparecem em cada gráfico.

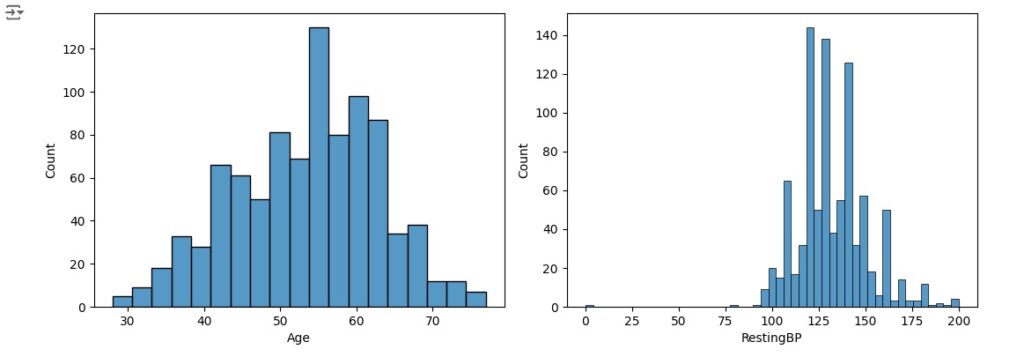
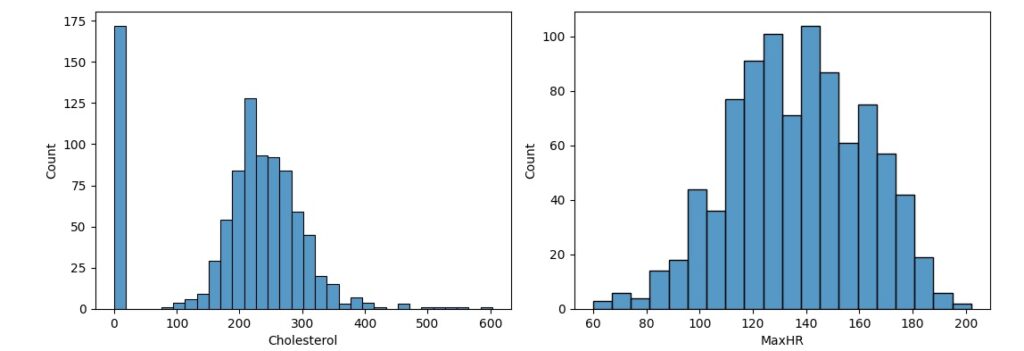
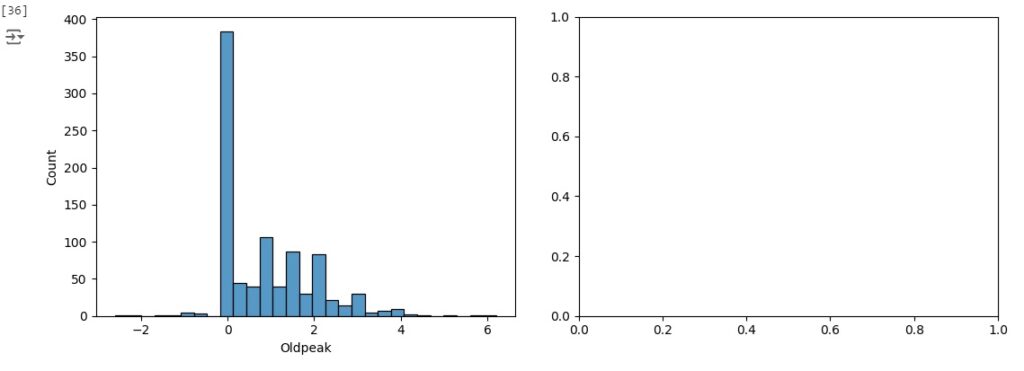
Vamos observar a distribuição normal, para que seja considerada uma distribuição normal dos dados eles precisam ter uma forma simétrica de sino, média igual a zero e desvio padrão igual a 1. Percebemos pelos histogramas gerados que algumas variáveis estão longe de ter uma distribuição normal.


Agora vamos transformar as variáveis categóricas em numéricas utilizando o OneHotEncoder através da biblioteca do scikit-learn LabelEncoder(). Vamos passar o comando lb.fit_transform() nas variáveis que queremos converter, menos na variável target. Em seguida verificamos se surgiu algum valor nulo e percebemos que não.
Agora notamos que as variáveis foram todas convertidas para numérico.
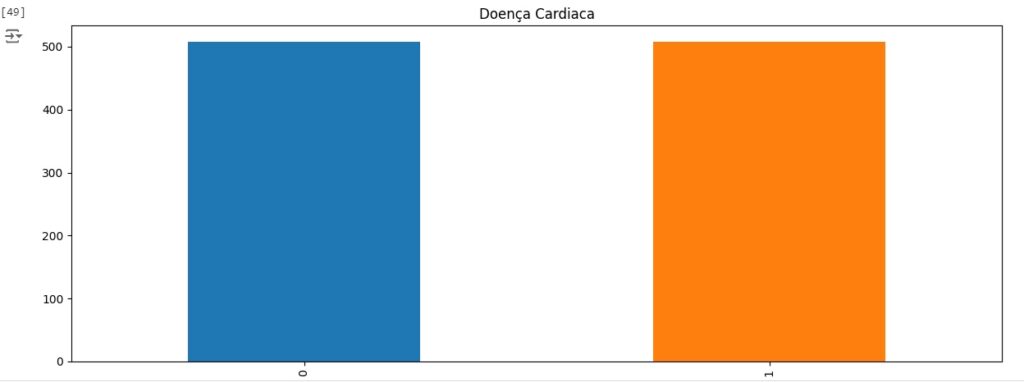
Vamos visualizar o balanceamento da variável target e em seguida com o comando iloc[] vamos criar as variáveis preditoras e target.



Agora vamos balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento em seguida usaremos o fit_resmple() que é o método balanceardor do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target.
Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.


Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 70% dos dados para treinamento e 30% para teste.

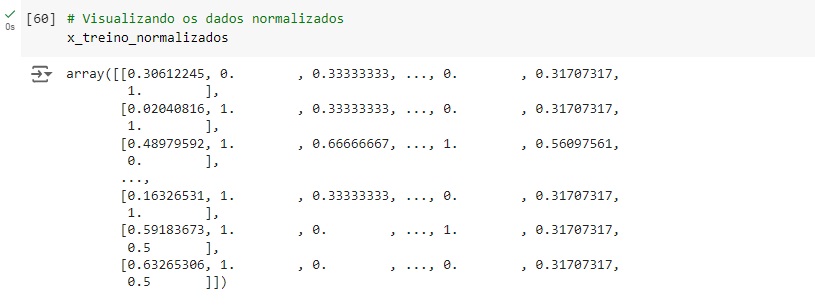
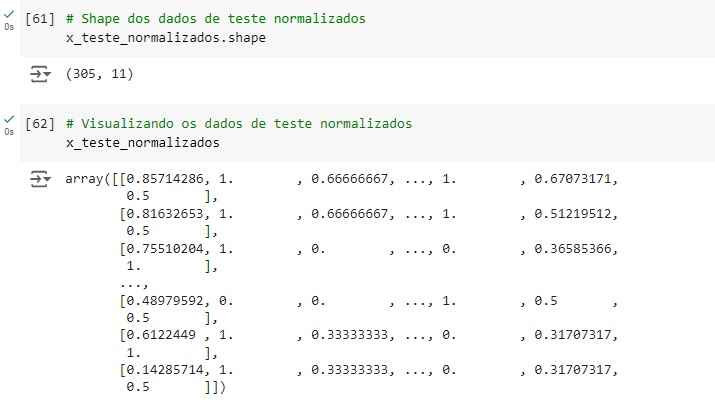
Agora vamos normalizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o MinMaxScaler() e o fit_transform() para isso.
Criando o classificador com o algoritmo de machine learning RandomForestClassifier() com alguns hiperparâmetros para melhorar a acurácia do modelo, n_estimators = 300 é o número de árvores de decisão que terá o modelo. Em seguida criamos o modelo, passamos o classificador com o comando fit() e passamos como parâmetro as variáveis de treino normalizadas.

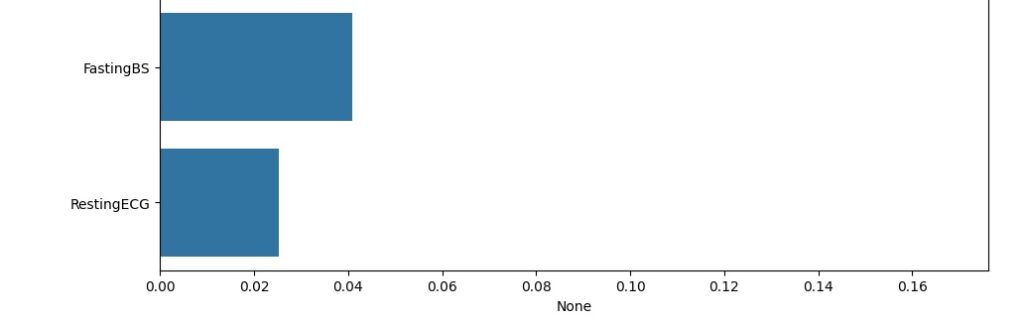
Avaliando graficamente o peso de cada variável no modelo. Vamos cria a variável importances onde vamos passar os dados, o classificador o feature_importances_ que é um comando do próprio Random Forest, pois ele pega as variáveis com um peso maior ao longo do treinamento, no caso seriam as variáveis que tiveram um impacto maior para o resultado do modelo.






Olhando a acurácia do modelo, percebemos que tivemos 86,22% de acurácia.

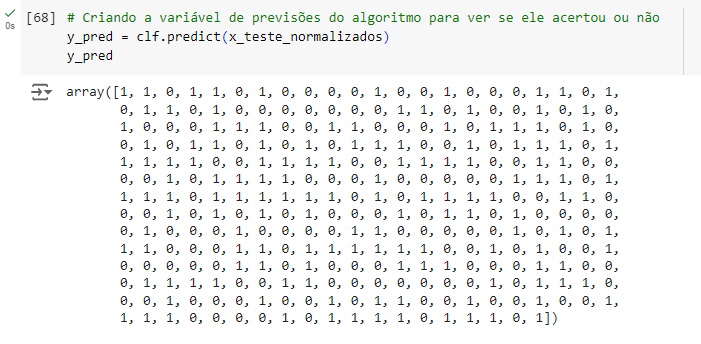
Comparando as previsões com os dados reais percebemos que o algoritmo acertou as 4 primeiras, errou a quinta, a sexta e a sétima acertou novamente…

Vamos afazer uma análise a partir da matriz de confusão. Vamos importar a biblioteca sklearn.metrics import confusion_matrix.

Através do classification report percebemos que o algoritmo consegue identificar corretamente 84% das pessoas não tem doença cardíaca (recall 0.84) e quando identifica uma pessoa desta classe a precisão é de 90% (precision 0.90). Para as pessoas que possuem doença cardíaca o resultado do algoritmo foi de 88% das identificações corretas (recall 0.88) com 82% de certeza (precision 0.82).
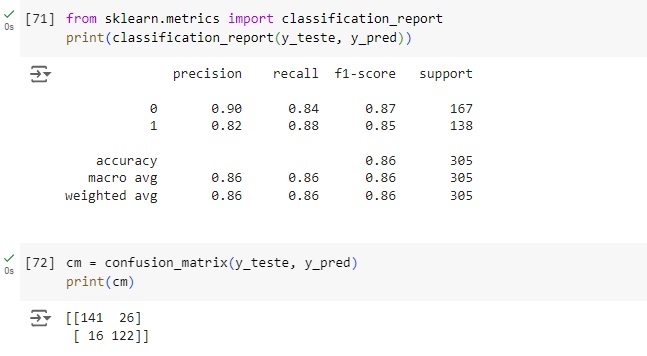
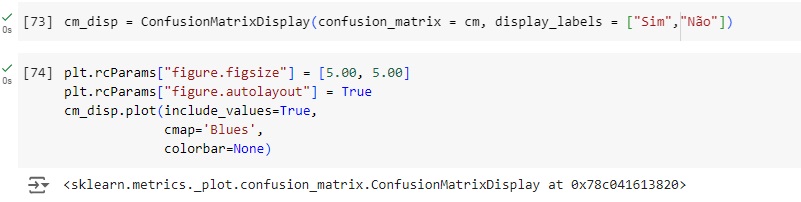
Plotando a matriz de confusão podemos perceber que 141 pessoas tem problemas cardíacos no banco de dados real e foi também o valor que o modelo previu, ou seja, é um verdadeiro positivo. No outro lado da matriz percebemos que segundo os dados reais 122 pessoas não possuem doença cardíaca, o mesmo valor que o modelo previu, ou seja é um verdadeiro negativo. Com isso conseguimos perceber que a diagonal que está azul mais escuro são os acertos do modelo.
Passando para a diagonal azul claro, percebemos que o banco de dados real tem 26 não têm a doença, mas o modelo previu que tem, ou seja, é um falso positivo, no caso o modelo errou a previsão. Na outra diagonal percebemos que tem 16 pessoas positivas segundo o banco de dados real, mas o modelo previu que não havia doença, no caso é um falso negativo.