O Que é Visão Computacional?

Um dos tipos mais poderosos e atraentes de IA é a visão computacional, que você quase certamente já experimentou de várias maneiras, mesmo sem saber. Então vamos ver um pouco como funciona e porque é tão incrível.
A visão computacional é o campo da inteligência artificial que se concentra em replicar partes da complexidade do sistema de visão humana e permitir que os computadores identifiquem e processem objetos em imagens e vídeos da mesma forma que os humanos fazem. Até recentemente, a visão computacional funcionava apenas com capacidade limitada.
Graças aos avanços na inteligência artificial e às inovações em aprendizagem profunda e redes neurais, o campo conseguiu dar grandes saltos nos últimos anos e conseguiu superar os humanos em algumas tarefas relacionadas à detecção e rotulagem de objetos.
Um dos fatores que impulsionam o crescimento da visão computacional é a quantidade de dados que geramos hoje e que são usados para treinar e melhorar a visão computacional.

Juntamente com uma enorme quantidade de dados visuais (mais de 3 bilhões de imagens são partilhadas online todos os dias), o poder computacional necessário para analisar os dados agora é acessível. À medida que o campo da visão computacional cresceu com novos hardwares e algoritmos, também cresceram as taxas de precisão para identificação de objetos. Em menos de uma década, os sistemas atuais atingiram 99% de precisão, contra 50%, se tornando mais precisos do que os humanos na reação rápida de informações visuais.
Os primeiros experimentos em visão computacional começaram na década de 1950 e ela foi utilizada comercialmente pela primeira vez para distinguir entre texto digitado e manuscrito na década de 1970. Hoje, as aplicações para visão computacional cresceram exponencialmente.
Como Funcional a Visão Computacional?
Uma das principais questões em aberto tanto na neurociência quanto no aprendizado de máquina é: como exatamente funciona o nosso cérebro e como podemos aproximar isso com nossos próprios algoritmos? A realidade é que existem muito poucas teorias funcionais e abrangentes sobre a computação cerebral; portanto, apesar do fato de que as redes neurais supostamente “imitam o modo como o cérebro funciona”, ninguém tem certeza se isso é realmente verdade.
O mesmo paradoxo vale para a visão computacional, uma vez que não estamos decididos sobre como o cérebro e os olhos processam as imagens, é difícil dizer até que ponto os algoritmos usados na produção se aproximam dos nossos próprios processos mentais internos.
Em certo nível, a visão computacional trata do reconhecimento de padrões. Portanto, uma maneira de treinar um computador para entender dados visuais é alimentá-lo com imagens, milhares de imagens, milhões, se possível, que foram rotuladas, e então submetê-las a várias técnicas de software, ou algoritmos que permitem ao computador caçar padrões em todos os elementos que se relacionam com esses rótulos.
Então, por exemplo, se você alimentar um computador com um milhão de imagens de gatos, ele irá submetê-los a algoritmos que permitem analisar as cores da foto, as formas, as distâncias entre as formas, onde os objetos fazem fronteira entre si, e assim por diante, para identificar um perfil do que significa “gato”. Quando terminar, o computador será, pelo menos em teoria, capaz de usar sua experiência se alimentado com outras imagens não rotuladas para encontrar aquelas que são de gato.
Abaixo está uma ilustração simples do buffer de imagem em tons de cinza que armazena uma imagem de Abraham Lincoln. O brilho de cada pixel é representado por um único número de 8 bits, cujo intervalo vai de 0 (preto) a 255 (branco).

Na verdade, os valores dos pixels são armazenados quase universalmente, no nível do hardware, em uma matriz unidimensional. Por exemplo, os dados da imagem acima são armazenados de maneira semelhante a esta longa lista mostrada abaixo de caracteres não assinados:

Esta forma de armazenar dados de imagem pode ir contra as expectativas, uma vez que os dados certamente parecem ser bidimensionais quando são exibidos. No entanto, este é o caso, uma vez que a memória do computador consiste simplesmente numa lista linear cada vez maior de espaços de endereço.
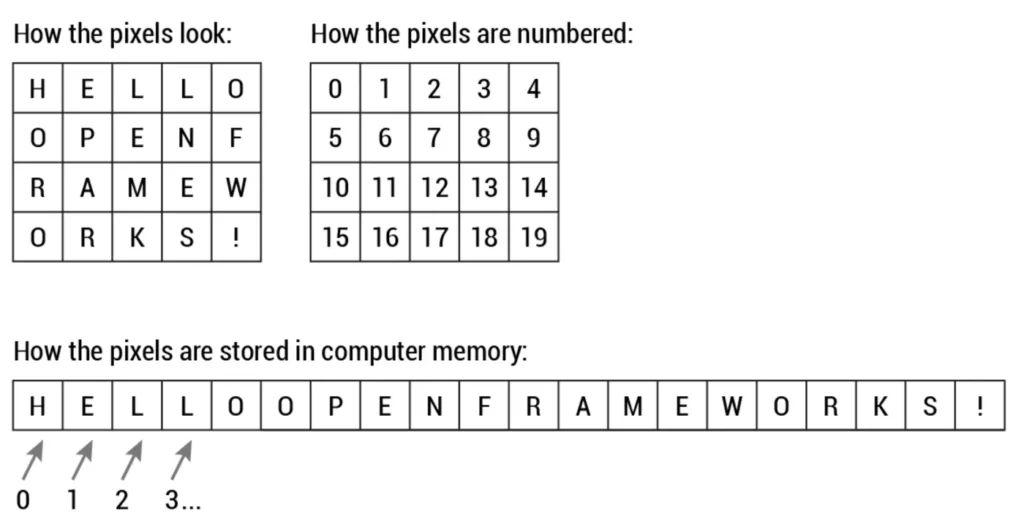
Vamos voltar à primeira imagem e imaginar se ela fosse colorida. Agora as coisas começam a ficar mais complicadas. Os computadores geralmente leem as cores como uma série de 3 valores, vermelho, verde e azul (RGB), na mesma escala de 0–255. Agora, cada pixel possui, na verdade, 3 valores para o computador armazenar, além de sua posição. Se coloríssemos o presidente Lincoln, isso levaria a valores 12 x 16 x 3, ou 576 números.
É necessária muita memória para uma imagem com muitos pixels ser processada por um algoritmo. Mas para treinar um modelo com precisão significativa, especialmente quando se trata de deep learning (aprendizado profundo), normalmente precisaria de dezenas de milhares de imagens, e quanto mais, melhor.
A Evolução da Visão Computacional
Antes da evolução do aprendizado profundo, as tarefas que a visão computacional podia realizar eram muito limitadas e exigiam muita codificação manual e esforço por parte dos desenvolvedores. Por exemplo, se você quisesse realizar o reconhecimento facial, teria que realizar os seguintes passos:
1 – Criar um banco de dados: precisava capturar imagens individuais de todos os assuntos que desejava rastrear em um formato específico;
2 – Anotar imagens: para cada imagem individual, teria que inserir vários pontos de dados importantes, como distância entre os olhos, largura da ponte nasal, distância entre o lábio superior e o nariz e dezenas de outras medidas que definem as características únicas de cada pessoa.
3 – Capturar novas imagens: em seguida, teria que capturar novas imagens, seja de fotografias ou de conteúdo de vídeo. E então teria que passar pelo processo de medição novamente, marcando os pontos chave na imagem. Também precisava levar em consideração o ângulo em que a imagem foi tirada.
Depois de todo esse trabalho manual, o aplicativo finalmente seria capaz de comparar as medidas da nova imagem com as armazenadas em seu banco de dados e informar se ela correspondia a algum dos perfis que estava rastreando. Na verdade, havia muito pouca automação envolvida e a maior parte do trabalho era feita manualmente. E a margem de erro ainda era grande.
O aprendizado de máquina (machine learning) forneceu uma abordagem diferente para resolver problemas de visão computacional. Com o aprendizado de máquina, os desenvolvedores não precisariam mais codificar manualmente cada regra em seus aplicativos de visão. Em vez disso, programaram “recursos”, aplicativos menores que poderiam detectar padrões específicos em imagens. Eles então usaram um algoritmo de aprendizagem estatística, como regressão linear, regressão logística, árvores de decisão ou máquinas de vetores de suporte (SVM) para detectar padrões e classificar imagens e detectar objetos nelas.
O aprendizado de máquina (machine learning) ajudou a resolver muitos problemas que eram historicamente desafiadores para ferramentas e abordagens clássicas de desenvolvimento de software. Por exemplo, anos atrás, engenheiros de aprendizado de máquina conseguiram criar um software que poderia prever as janelas de sobrevivência do câncer de mama melhor do que especialistas humanos. No entanto, a construção dos recursos do software exigiu o esforço de dezenas de engenheiros e especialistas em câncer de mama e levou muito tempo para ser desenvolvido.
A deep learning forneceu uma abordagem fundamentalmente diferente para realizar o aprendizado de máquina. A deep learning depende de redes neurais, uma função de uso geral que pode resolver qualquer problema representável por meio de exemplos. Quando você fornece a uma rede neural muitos exemplos rotulados de um tipo específico de dados, ela será capaz de extrair padrões comuns entre esses exemplos e transformá-los em uma equação matemática que ajudará a classificar informações futuras.
Por exemplo, criar um aplicativo de reconhecimento facial com deep learning requer apenas que você desenvolva ou escolha um algoritmo pré-treinado com exemplos de rostos de pessoas que ele deve detectar. Dados exemplos suficientes, a rede neural será capaz de detectar rostos sem instruções adicionais sobre recursos ou medições.
A deep learning é um método muito eficaz para fazer visão computacional. Na maioria dos casos, a criação de um bom algoritmo de deep learning se resume à coleta de uma grande quantidade de dados de treinamento rotulados e ao ajuste de parâmetros como tipo e número de camadas de redes neurais e épocas de treinamento. Em comparação com os tipos anteriores de aprendizado de máquina, a deep learning é mais fácil e rápida de desenvolver e implantar.
A maioria das aplicações atuais de visão computacional, como detecção de câncer, carros autônomos e reconhecimento facial, fazem uso de deep learning. O aprendizado profundo e as redes neurais profundas passaram do domínio conceitual para aplicações práticas graças à disponibilidade e aos avanços nos recursos de hardware e computação em nuvem.
Quanto Tempo Leva Para Decifrar Uma Imagem
Em suma, não muito. Essa é a chave para explicar por que a visão computacional é tão emocionante, pois enquanto no passado até mesmo os supercomputadores podiam levar dias, semanas ou até meses para realizar todos os cálculos necessários, os chips ultrarrápidos de hoje e o hardware relacionado, juntamente com uma internet rápida e confiável e redes em nuvem, tornam o processo extremamente rápido. Outrora um fator crucial foi a vontade de muitas das grandes empresas que realizam investigação em IA de partilharem o seu trabalho no Facebook, Google, IBM e Microsoft, abrindo o código-fonte de alguns dos seus trabalhos de aprendizagem automática.
Isso permite que outros desenvolvam seu trabalho em vez de começar do zero. Como resultado, a indústria da IA está avançando, e as experiências que há pouco tempo demoravam semanas para realizar, hoje podem demorar 15 minutos. E para muitas aplicações reais de visão computacional, todo esse processo acontece continuamente em microssegundos, de modo que um computador hoje é capaz de ser o que os cientistas chamam de “consciente da situação”.
Aplicações da Visão Computacional
A visão computacional é uma das áreas do aprendizado de máquina onde os conceitos básicos já estão sendo integrados aos principais produtos que usamos todos os dias.
Carros Autônomos
A visão computacional permite que carros autônomos entendam o que os rodeia. As câmeras capturam vídeos de diferentes ângulos ao redor do carro e os transmitem ao software de visão computacional, que então processa as imagens em tempo real para encontrar as extremidades das estradas, ler sinais de trânsito, detectar outros carros, objetos e pedestres. O carro autônomo pode então dirigir pelas ruas e rodovias, evitar bater em obstáculos e quem sabe um dia, conduzir com segurança seus passageiros ao seu destino.
Reconhecimento Facial
A visão computacional também desempenha um papel importante nas aplicações de reconhecimento facial, a tecnologia que permite aos computadores combinarem imagens dos rostos das pessoas com as suas identidades. Algoritmos de visão computacional detectam características faciais em imagens e as comparam com bancos de dados de perfis faciais. Os dispositivos de consumo usam reconhecimento facial para autenticar as identidades de seus proprietários. Os aplicativos de mídia social usam reconhecimento facial para detectar e marcar usuários. As agências de aplicação da lei também contam com tecnologia de reconhecimento facial para identificar criminosos em feeds de vídeo.
Saúde
A visão computacional também tem sido uma parte importante dos avanços na tecnologia da saúde. Algoritmos de visão computacional podem ajudar a automatizar tarefas como detectar manchas cancerígenas em imagens da pele ou encontrar sintomas em exames de raios X e ressonância magnética.
Desafios da Visão Computacional
Não é simples ensinar um computador a enxergar. Inventar uma máquina que veja como nós é uma tarefa difícil, não apenas porque é difícil fazer com que os computadores façam isso, mas porque, em primeiro lugar, não temos certeza de como a visão humana funciona.
O estudo da visão biológica requer uma compreensão dos órgãos de percepção, como os olhos, bem como a interpretação da percepção dentro do cérebro. Muito progresso foi feito, tanto no mapeamento do processo quanto na descoberta dos truques e atalhos utilizados pelo sistema, embora, como qualquer estudo que envolva o cérebro, ainda existe um longo caminho a percorrer.
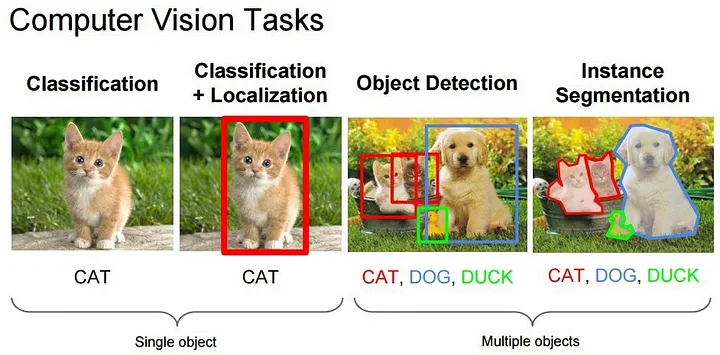
Muitas aplicações populares de visão computacional envolvem a tentativa de reconhecer algo específico em fotografias, por exemplo:
Classificação do objeto: que categoria ampla de objeto está nesta fotografia?
Identificação do objeto: que tipo de determinado objeto está nesta fotografia?
Verificação do objeto: o objeto está na fotografia?
Detecção de objetos: onde estão os objetos na fotografia?
Detecção de marco de objeto: quais são os pontos-chave do objeto na fotografia?
Segmentação de objetos: quais pixels pertencem ao objeto na imagem?
Reconhecimento de objetos: quais objetos estão nesta fotografia e onde eles estão?
Fora do simples reconhecimento, outros métodos de análise incluem:
A análise de movimento de vídeo: usa visão computacional para estimar a velocidade dos objetos em um vídeo ou da própria câmera.
Na segmentação de imagens: os algoritmos particionam as imagens em vários conjuntos de visualizações.
A reconstrução de cena: cria um modelo 3D de uma cena inserida por meio de imagens ou vídeo.
Na restauração de imagens: ruídos como desfoque são removidos das fotos usando filtros baseados em aprendizado de máquina.
Conclusão
Apesar do progresso recente, que tem sido impressionante, ainda não estamos nem perto de resolver a visão computacional. No entanto, já existem múltiplas instituições e empresas de saúde que encontraram formas de aplicar sistemas CV, alimentados por CNNs, em problemas do mundo real. E não é provável que esta tendência pare tão cedo.