O Que São Redes Adversariais Generativas (GANs)?

Hoje vamos falar um pouco sobre as GANs, esta tecnologia incrível de IA que consegue por exemplo, criar uma imagem através de um texto.
Em termos leigos: ” GANs é um sistema que coloca duas redes neurais uma contra a outra para melhorar a qualidade dos seus resultados”.
As Redes Adversariais Generativas (GANs) têm atraído atenção significativa no campo da Inteligência Artificial, não apenas pelos seus métodos inovadores na geração e aprimoramento de dados, mas também pelo seu papel fundamental em aplicações como a criação de imagens realistas, transferência de estilos em imagens, geração de imagens, rostos humanos realistas, entre outros. Revelados pela primeira vez por Ian Goodfellow e sua equipe em um artigo da NeurIPS de 2014, as GANs se destacam como sistemas de aprendizado de máquina adeptos da replicação de distribuições de dados específicos. Em sua essência, eles consistem em duas redes neurais interligadas: o gerador, responsável pela criação dos dados, e o discriminador, cuja tarefa é diferenciar entre dados genuínos e simulados. Esta interação resulta num processo de formação único, com as GANs funcionando de forma “adversária”, formulado como um desafio de aprendizagem supervisionada. Aqui, o gerador cria dados tão genuínos até que o discriminador seja enganado aproximadamente 50% das vezes.
Um avanço notável dentro dos GANs é o surgimento de Deep Convolutional GANs (DC-GANs), que utilizam camadas convolucionais e provaram ser especialmente eficazes na geração de imagens realistas e de alta qualidade para uma infinidade de aplicações. Essas redes têm sido muito importantes em diversas conquistas na geração de imagens e vídeos. Aplicações renomadas incluem a transformação da estética da imagem via CycleGAN e a síntese de rostos humanos hiper-realistas usando StyleGAN, como exemplificado na plataforma “This Person Does Not Exist”.
Arquitetura
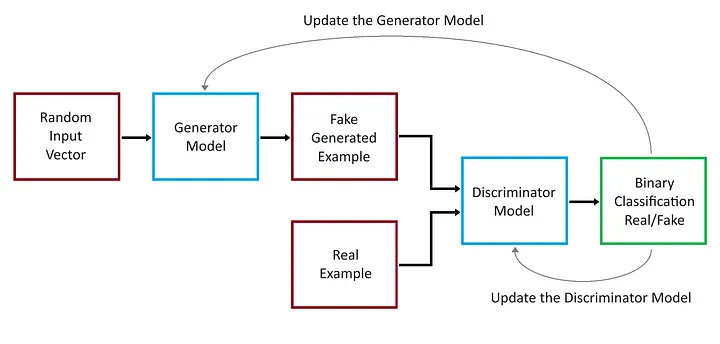
Uma Rede Adversarial Generativa (GAN) consiste em duas redes neurais, nomeadamente o Gerador e o Discriminador, que são treinadas simultaneamente através de treinamento adversário.
Gerador: esta rede recebe ruído aleatório como entrada e produz dados como imagens. Seu objetivo é gerar dados o mais próximo possível dos dados reais.
Discriminador: esta rede toma como entrada os dados reais e os dados gerados pelo Gerador, e tenta distinguir entre os dois. Ele gera a probabilidade de que os dados fornecidos sejam reais.
Treinamento de Modelo GAN
Durante o treinamento, o Gerador tenta produzir dados que o Discriminador não consegue distinguir dos dados reais, enquanto o Discriminador tenta diferenciar melhor os dados reais dos dados falsos. As duas redes estão, em essência, competindo em um jogo, pois o Gerador visa produzir dados falsos convincentes e o Discriminador visa distinguir o real do falso. Este processo adversário faz com que o Gerador crie dados cada vez melhores ao longo do tempo.
Internamente, a GAN possui duas redes neurais que competem entre si. O objetivo da rede geradora é enganar a rede discriminadora e o objetivo da rede discriminadora é identificar corretamente se a entrada é real ou falsa.
Gerador
A função principal do gerador é gerar dados. Inicialmente, é provável que esses dados sejam ruídos aleatório porque o gerador inicia sem muito conhecimento sobre a verdadeira distribuição dos dados. Com o tempo, à medida que a GAN é treinada, o gerador aprende a produzir dados que se aproximam da distribuição real dos dados.
Arquitetura
Embora a arquitetura possa variar, os geradores em muitas GANs populares (como DCGAN) são construídos usando camadas convolucionais transpostas, que ajudam a aumentar a resolução do vetor de ruído para produzir uma imagem. O gerador geralmente consiste na sequência dos seguintes componentes:
Camada de entrada: o gerador começa com uma camada de entrada que recebe um vetor de ruído aleatório, geralmente amostrado de uma distribuição normal ou uniforme.
Camadas Totalmente Conectadas: no início da rede, camadas totalmente conectadas podem ser usadas para transformar o vetor de ruído de entrada em um formato adequado para processamento posterior.
Normalização em lote: esta técnica é frequentemente usada entre camadas para estabilizar o aprendizado, normalizando a saída de uma camada anterior. Ajuda a resolver problemas como colapso de modo e auxilia na convergência mais rápida.
Funções de ativação: ReLU (unidade linear retificada) ou Leaky ReLU são escolhas comuns para funções de ativação no gerador. Essas funções introduzem não linearidade ao modelo, permitindo gerar dados complexos.
Camadas Convolucionais Transpostas: essas camadas são fundamentais no gerador, pois aumentam a amostragem da entrada da camada anterior para uma dimensão espacial superior, fazendo efetivamente o oposto do que as camadas convolucionais fazem em uma CNN.
Remodelando camadas: essas camadas são usadas para remodelar os dados no formato de saída desejado, especialmente ao gerar imagens.
Camada de saída: a camada final geralmente emprega uma função de ativação tanh ou sigmóide, dependendo da natureza dos dados que estão sendo gerados. Para geração de imagens, uma função tanh é frequentemente usada para gerar valores de pixel em um intervalo normalizado.
Treinamento: durante o treinamento, o gerador tenta enganar o discriminador produzindo dados que o discriminador não consegue distinguir dos dados reais.
O gerador atualiza seus pesos com base no feedback do discriminador. Se o discriminador identificar corretamente os dados gerados como falsos, o gerador ajusta seus pesos para produzir dados mais convincentes durante a próxima iteração.
O processo é uma espécie de “jogo” onde o gerador tenta melhorar constantemente, com o objetivo de eventualmente produzir dados quase indistinguíveis dos dados reais.
Saída: o gerador produz dados como saída. No caso de uma GAN projetada para geração de imagens, a saída seria uma imagem. Os dados são então passados ao discriminador para serem classificados como reais ou falsos.
Desafios
Instabilidade de treinamento: GANs, em geral, são difíceis de serem treinadas, principalmente o treinamento do gerador, por ser particularmente desafiador. Isso ocorre porque o cenário de otimização envolve dois modelos (gerador e discriminador) que estão sendo treinados simultaneamente em um ambiente dinâmico. Este problema pode ser reduzido adotando técnicas como Gradient Penalty, usando escalonadores de taxa de aprendizagem ou adotando arquiteturas GANs mais específicas e mais estáveis para o problema em questão.
Discriminador
O papel do discriminador é distinguir entre dados reais e falsos. Se você está pensando em GANs no contexto de imagens (que é uma aplicação comum), o discriminador tenta distinguir as imagens reais das imagens falsas geradas pelo gerador.
Entrada: Recebe amostras de dados, que podem ser dados reais ou dados gerados.
Saída: fornece um valor escalar entre 0 e 1, representando a probabilidade de a amostra de entrada ser real. Um valor próximo de 1 sugere que a amostra é provavelmente real, enquanto um valor próximo de 0 sugere que é provavelmente falsa.
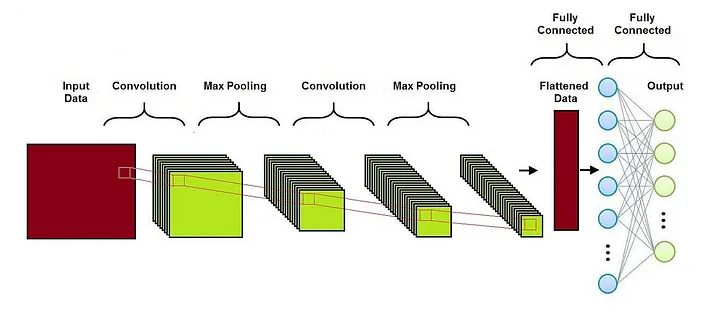
A arquitetura real (como o número de camadas, tipos de camadas, etc), pode variar amplamente com base no problema específico e no conjunto de dados. Para dados de imagem, os discriminadores costumam usar redes neurais convolucionais (CNNs).
Arquitetura: a arquitetura do discriminador muitas vezes reflete a das redes neurais convolucionais tradicionais (CNNs), mas com alguns ajustes. Geralmente consiste na sequência dos seguintes componentes:
Camadas de convolução: essas camadas são fundamentais no processamento de dados de imagem. Elas ajudam na extração de recursos das imagens de entrada. O número de camadas convolucionais pode variar dependendo da complexidade dos dados.
Normalização em lote: às vezes é usada entre camadas para estabilizar o aprendizado, normalizando a entrada para uma camada.
Funções de ativação: Leaky ReLU é uma escolha comum para funções de ativação no discriminador. Permite um pequeno gradiente quando a unidade não está ativa, o que pode ajudar a manter o fluxo do gradiente durante o treino.
Camadas de pooling: algumas arquiteturas usam camadas de pooling (como pooling máximo) para reduzir progressivamente as dimensões espaciais dos dados de entrada.
Camadas Totalmente Conectadas: No final da rede, camadas totalmente conectadas são utilizadas para processar os recursos extraídos pelas camadas convolucionais, culminando em uma camada de saída final.
Camada de saída: a camada final é normalmente um único neurônio com uma função de ativação sigmóide para gerar um valor de probabilidade.
Obviamente, o valor real pode variar amplamente com base no problema específico e no conjunto de dados. A principal diferença entre uma arquitetura CNN clássica e uma arquitetura discriminadora GAN é a seguinte:
Função de perda: CNNs usam muitas funções de perda diferentes, enquanto o Discriminador da GAN sempre usa perda binária de entropia cruzada, uma vez que distingue entre duas classes (verdadeiro vs. falso).
Loop de feedback: enquanto na CNN não há loop de feedback com outra rede durante seu treinamento e a CNN é treinada isoladamente usando um conjunto de dados rotulado, o Discriminador da GAN opera em conjunto com o Gerador. O Discriminador fornece feedback ao Gerador, permitindo-lhe melhorar as suas capacidades de geração de imagens.
Função de ativação de saída: Dependendo da tarefa, as CNNs podem usar ou não a ativação softmax, enquanto o Discriminador da GAN normalmente usa uma função de ativação sigmóide na camada de saída para fornecer uma pontuação de probabilidade indicando se a imagem é real ou falsa.
Profundidade e complexidade: o discriminador da GAN costuma ser mais simples e superficial do que as CNNs convencionais, mas é claro que a complexidade depende da arquitetura GAN específica e do conjunto de dados usado.
Treinamento: Durante o treinamento, o discriminador atualiza seus pesos da seguinte forma.
São mostrados dados reais e devem ser treinados para gerar valores próximos a 1. São mostrados dados falsos (gerados pelo gerador) e devem ser treinados para gerar valores próximos a 0.
Desafios
Discriminador avassalador: se o discriminador se tornar forte muito rapidamente, ele poderá sempre fornecer uma saída muito confiável (próxima de 0 ou 1) para qualquer entrada, dificultando o aprendizado do gerador. Esse problema pode ser mitigado pela implementação de técnicas como suavização de rótulos, correspondência de recursos ou desaceleração deliberada do treinamento do discriminador.
Discriminador fraco: Por outro lado, se o discriminador for muito fraco, o gerador pode não obter feedback significativo para melhorar. O equilíbrio entre o gerador e o discriminador durante o treinamento é crucial para o sucesso de uma GAN. Este problema pode ser reduzido aumentando a capacidade do discriminador, ajustando cuidadosamente a sua taxa de aprendizagem ou utilizando arquiteturas avançadas que melhorem o poder discriminativo.
Perda da GAN
Redes Adversariais Generativas utilizam funções de perda para treinar tanto o gerador quanto o discriminador. A função de perda ajuda a ajustar os pesos desses modelos durante o treinamento para otimizar seu desempenho. Tanto o gerador quanto o discriminador utilizam a perda binária de entropia cruzada para treinar os modelos, que pode ser escrito como:
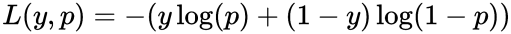
onde
L (y, p) é o valor da perda;
y é o rótulo verdadeiro (0 ou 1);
p é a probabilidade prevista da amostra pertencer à classe 1.
Perda do Discriminador
O objetivo do discriminador é classificar corretamente as amostras reais como reais e as amostras falsas (produzidas pelo gerador) como falsas. Sua perda é normalmente representada como:
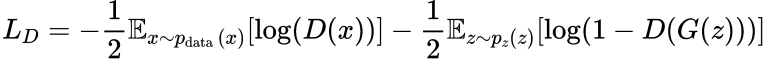
onde

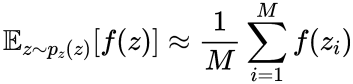
x_i são amostras do conjunto de dados real, N é o número de amostras do conjunto de dados real, z_i são amostras da distribuição de ruído e M é o número de amostras da distribuição de ruído.
O primeiro termo à direita penaliza o discriminador por classificar incorretamente os dados reais, enquanto o segundo termo penaliza o discriminador por classificar incorretamente os dados falsos produzidos pelo gerador.
Perda do Gerador
O objetivo do gerador é produzir amostras que o discriminador classifica incorretamente como reais. Sua perda é normalmente representada como:
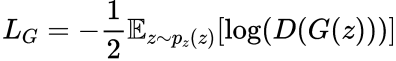
Este termo penaliza o gerador quando o discriminador identifica corretamente suas saídas como falsas.
Perda Combinada
A perda GAN combinada, muitas vezes chamada de perda minimax, é uma combinação das perdas do discriminador e do gerador. Pode ser expresso como:
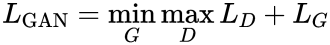
Isso representa a natureza adversária do treinamento GAN, onde o gerador e o discriminador estão em um jogo minimax para dois jogadores. O discriminador tenta maximizar sua capacidade de classificar corretamente dados reais e falsos, enquanto o gerador tenta minimizar a capacidade do discriminador gerando dados realistas.
Penalidade do Gradiente
Penalidade de gradiente é uma técnica usada para estabilizar o treinamento, penalizando os gradientes se eles se tornarem muito íngremes. Isso pode ajudar a estabilizar o treinamento e evitar problemas.

onde
GP representa o termo de penalidade do gradiente;
λ é um hiperparâmetro que controla a força da penalidade;
o componente gradiente é o gradiente da saída do discriminador em relação à sua entrada x ^;
P_x ^ representa a distribuição de amostras interpoladas entre dados reais e gerados;
k é uma norma alvo para o gradiente, geralmente definida como 1;
A perda do discriminador com penalidade de gradiente pode ser incorporada da seguinte forma:
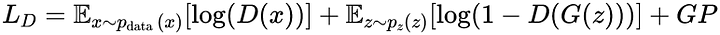
Esta função de perda consiste nos componentes usuais de perda do discriminador da GAN para dados reais e gerados, mais o termo de penalidade de gradiente para regularizar o comportamento do discriminador. O conceito principal é que, ao penalizar grandes gradientes, você incentiva o discriminador a se comportar de maneira mais suave, o que pode levar a um processo de treinamento mais estável tanto para o gerador quanto para o discriminador. Esta abordagem pode ser ajustada e adaptada dependendo das características específicas da arquitetura GAN e do problema em questão.
Aplicações
As GANs ganharam atenção significativa desde o seu início e têm sido empregadas em uma ampla gama de aplicações. Algumas das aplicações mais importantes incluem:
Geração de imagens: esta foi uma das aplicações iniciais das GANs. Elas podem ser treinadas para gerar imagens realistas e de alta resolução a partir de ruído aleatório.
Aumento de dados: em domínios onde os dados são limitados, as GANs podem ser usadas para aumentar o conjunto de dados gerando novas amostras, que podem ser particularmente valiosas para treinar modelos de aprendizado de máquina mais robustos.
Transferência de estilo: as GANs podem modificar o estilo das imagens, como converter fotos no estilo de pinturas famosas ou alterar cenas diurnas para cenas noturnas.
Super-resolução: GANs de super-resolução (SRGANs) podem melhorar a resolução das imagens, transformando imagens de baixa resolução em equivalentes de alta resolução.
Tradução de imagem para imagem: GANs podem ser usadas para traduzir imagens de um domínio para outro, como transformar imagens de satélite em mapas ou esboços em imagens coloridas.
Gerando arte: artistas e amadores têm usado GANs para criar peças de arte originais, tanto na forma de imagens estáticas quanto de vídeos.
Conclusão
As Redes Adversariais Generativas (GANs) representam um passo transformador no domínio da Inteligência Artificial e do aprendizado de máquina. A sua arquitetura única, que coloca um gerador contra um discriminador numa “dança” de criação e validação de dados, abriu caminhos para a inovação anteriormente considerada desafiadora. Desde a criação de imagens fotorrealistas até avanços pioneiros no aumento de dados, as GANs estabeleceram firmemente sua importância no cenário atual de IA. Embora apresentem o seu próprio conjunto de desafios e complexidades, a investigação e os avanços contínuos neste campo proporcionam uma visão promissora do futuro.