Previsão de Inundações

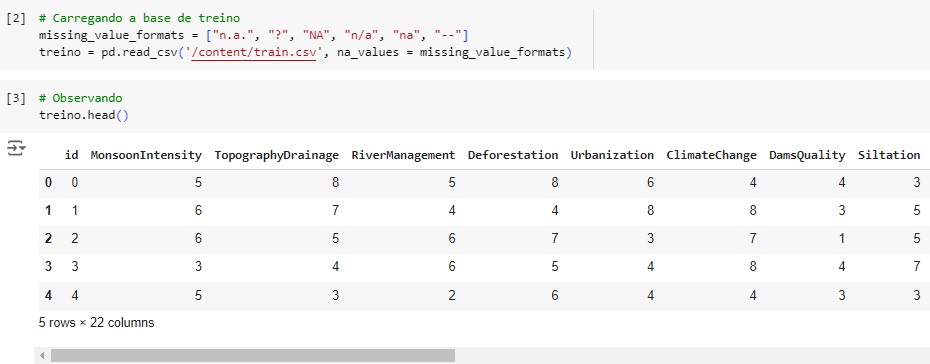
Neste projeto vamos fazer previsões de inundações utilizando machine learning. A detecção de inundações refere-se ao processo de identificação e monitoramento e alerta das autoridade e dos cidadãos sobre a probabilidade de inundação em determinada área. Os códigos foram desenvolvidos em linguagem Python na plataforma Google Colab, antes de imlementação vamos observar algumas informações. No dataset temos os seguintes atributos:
- Id;
- MonsoonIntensity: Intensidade das chuvas de monção;
- TopographyDrainage: A eficiência da drenagem em função da topografia da área;
- RiverManagement: Gestão de rios e vazões fluviais;
- Deforestation: A taxa de desmatamento nos países;
- Urbanization: O nível de desenvolvimento urbano;
- ClimateChange: Mudanças climáticas;
- DamsQuality: Qualidade de barragens;
- Siltation: O nível de entupimento dos leitos dos rios e reservatórios;
- AgriculturalPractices: As práticas da agricultura, incluindo o uso da terra e sistemas de irrigação;
- Encroachments: Ocupação ilegal de terras e corpos d’água;
- IneffectiveDisasterPreparedness: Preparação insuficiente para emergências e desastres naturais;
- DrainageSystems: Estado dos sistemas de drenagem e esgoto;
- CoastalVulnerability: Vulnerabilidade das zonas costeiras às inundações;
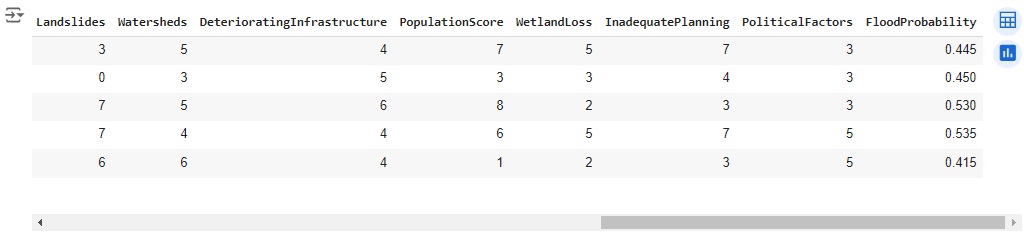
- Landslides: Risco de deslizamentos e deslizamentos de terra;
- Watersheds: Estado das bacias hidrográficas;
- DeteriorationInfrastructure: Degradação dos trabalhadores;
- PopulationScore: Densidade populacional e fatores relacionados;
- WetlandLosss: Perda de áreas úmidas e condições dos corpos d’água;
- InadequatePlanning: Planejamento e gerenciamento de problemas insuficientes;
- PoliticalFactors: Fatores políticos que influenciam o risco de inundações;
- FloodProbability: Probabilidade de ocorrência de inundação.
Vamos começar importando as bibliotecas.
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Carregando a base de dados de treino e observando as variáveis. Nossa variável alvo será ‘FloodProbability’.
Conferindo o shape, percebemos que o banco de dados possui 1117957 linhas e 22 colunas.

Carregando a base de dados de teste e observando.
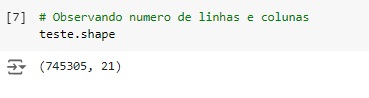
Conferindo o shape, percebemos que o banco de dados possui 745305 linhas e 21 colunas.
Vamos retirar das 2 bases de dados a coluna ‘ID’, pois não será útil para nosso modelo, mas vamos salvá-la na variável idvar.

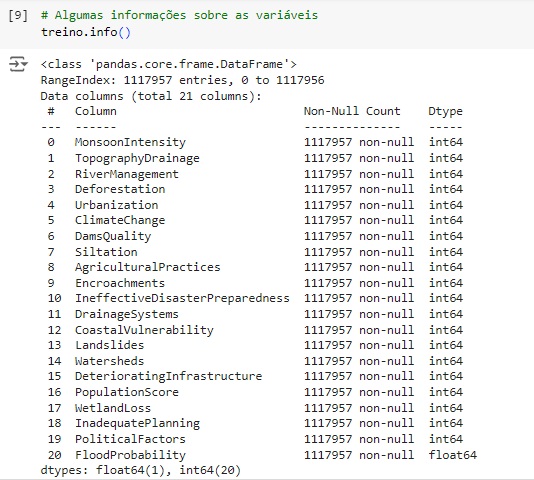
Com a ajuda do comando info(), obtemos algumas informações e percebemos que existem apenas variáveis do tipo numérico.
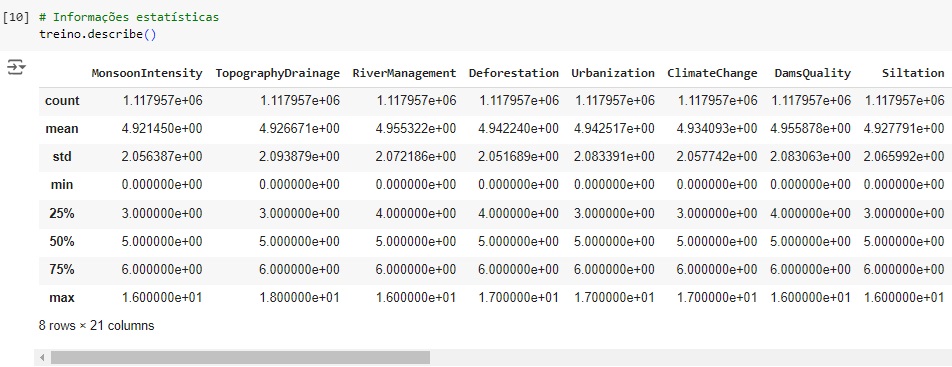
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão.
Verificando os valores nulos com o comando isnull().sum(). Podemos observar que não existem valores nulos no dataset.
Percebemos através do comando duplicated() que o dataset não possui valores duplicados.
Agora vamos analisar a dispersão do dataset. Para que um dataset seja esparso aproximadamente metade das observações ou mais da metade delas deve ser zero. Percebemos que temos 0%. Através da função do scipy issparse() temos como resposta que o conjunto de dados não é esparso, consta como False.
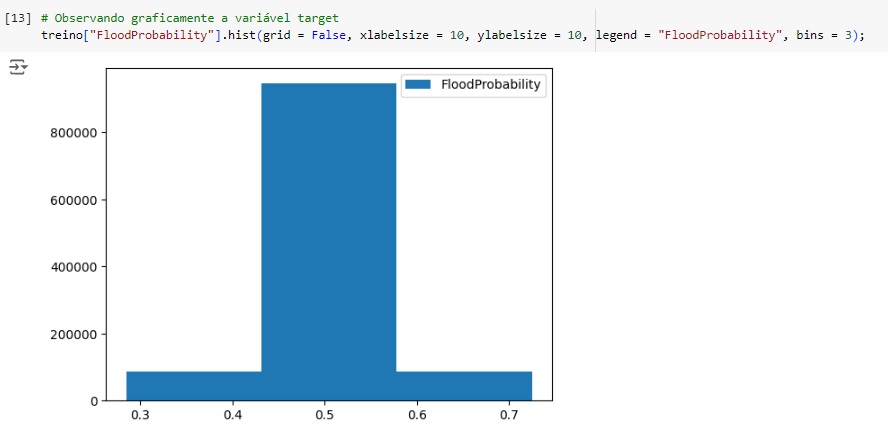
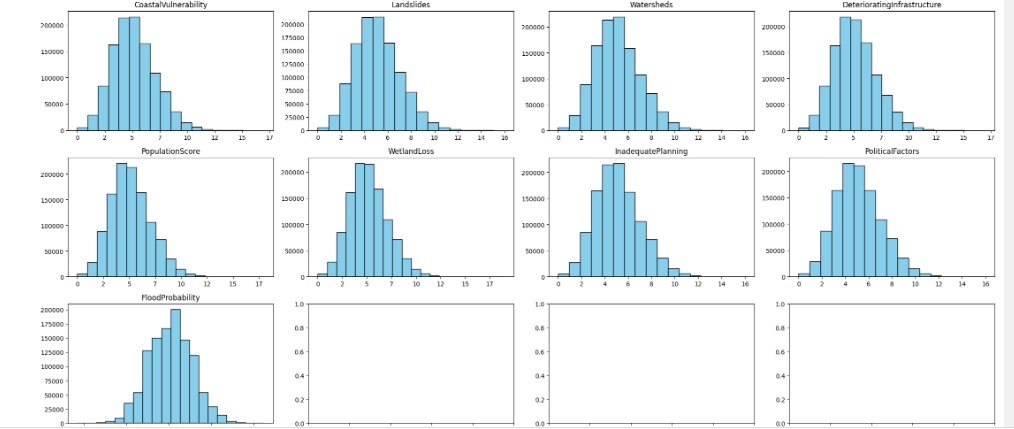
Observando a distribuição do banco de dados.

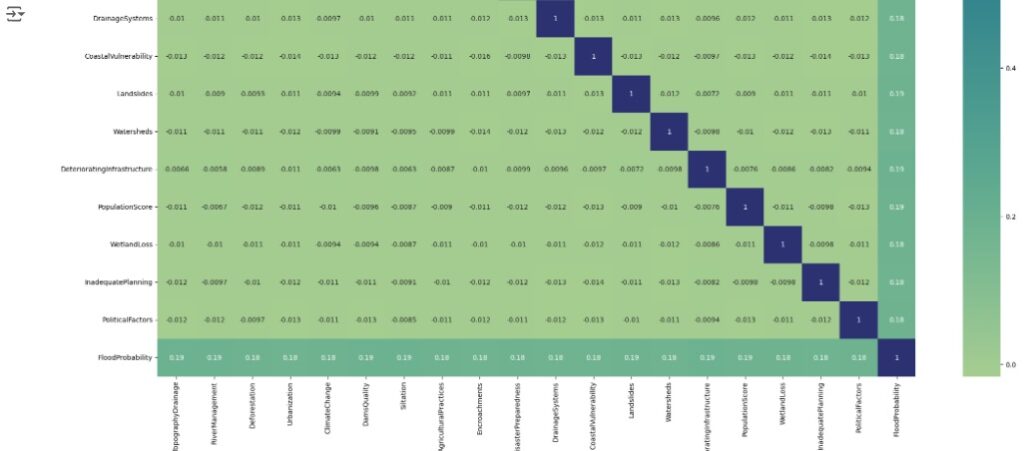
Agora vamos analisar a matriz de correlação.
Criando um boxplot para observar a existência de outliers. Percebemos através dos gráficos que existem muitos, serão tratados.
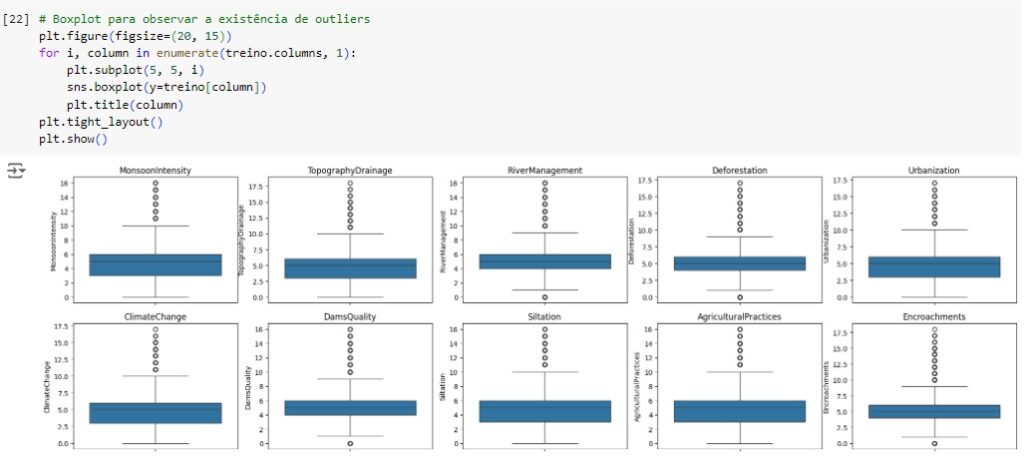
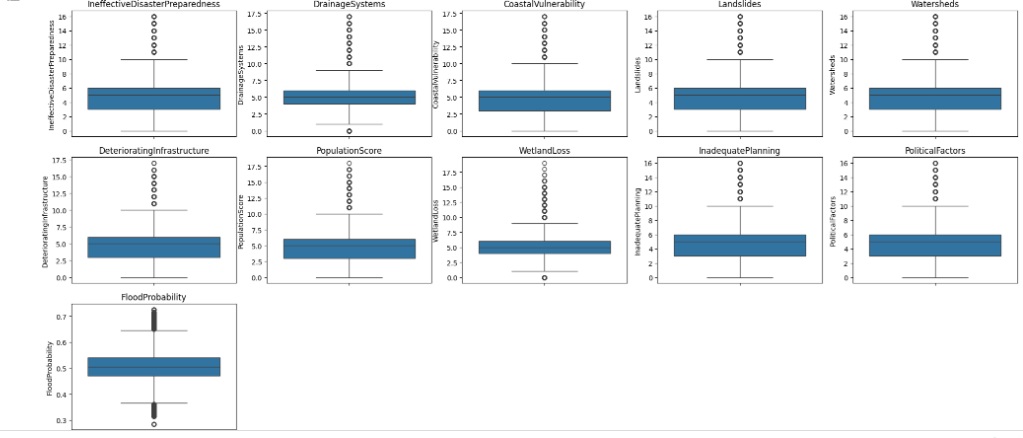
Vamos resolver o problema dos outliers utilizando o método Tukey ou Boxplot onde iremos definir os limites inferior e superior a partir do interquartil (IQR) e dos primeiros (Q1) e terceiros (Q3) quartis.
Quartis são separatrizes que dividem um conjunto de dados em 4 partes iguais. O objetivo das separatrizes é proporcionar uma melhor ideia da dispersão do dataset, principalmente da simetria ou assimetria da distribuição.
O limite inferior é definido pelo primeiro quartil menos o produto entre o valor 1.5 e o interquartil.
Linf = Q1 – (1.5 * IQR)
O limite superior é definido pelo terceiro quartil mais o produto entre o valor 1.5 e o interquartil.
Lsup = Q3 + (1.5 * IQR)
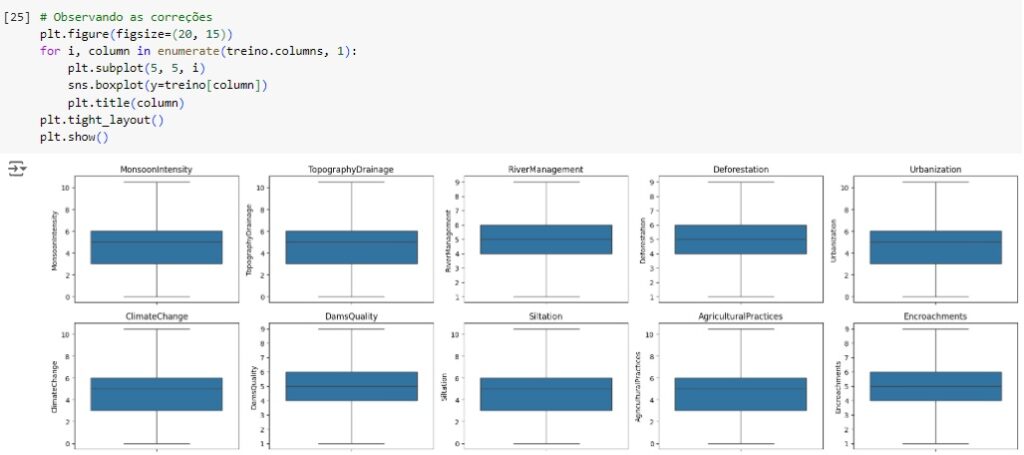
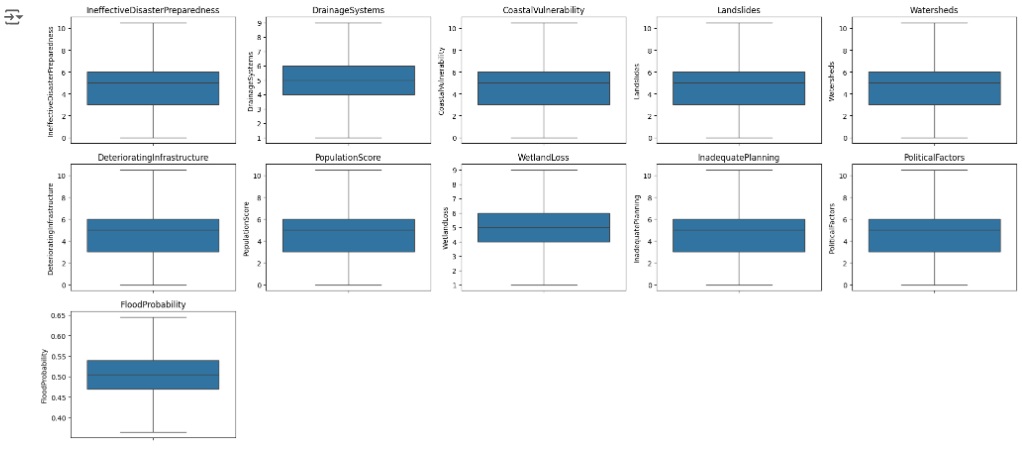
Em seguida vamos observar se os outliers foram removidos através do boxplot.
Esta função serve para substituir os outliers, onde valores acima do limite superior são substituídos pelo próprio limite superior e valores abaixo do limite inferior são substituídos pelo próprio limite inferior.

Observando se as correções foram feitas e percebemos que sim.
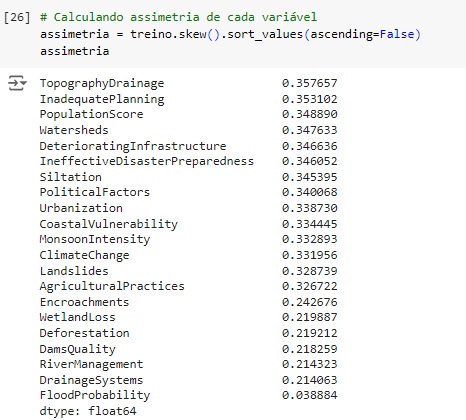
Vamos calcular a assimetria dos dados que é uma medida estatística que descreve a distribuição dos dados em relação à sua média. Em termos simples, a assimetria indica se os dados estão concentrados mais para um lado da média do que para o outro.


Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 75% dos dados para treinamento e 25% para teste.
Em seguida vamos padronizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o StandardScaler() e o fit_transform() para isso.
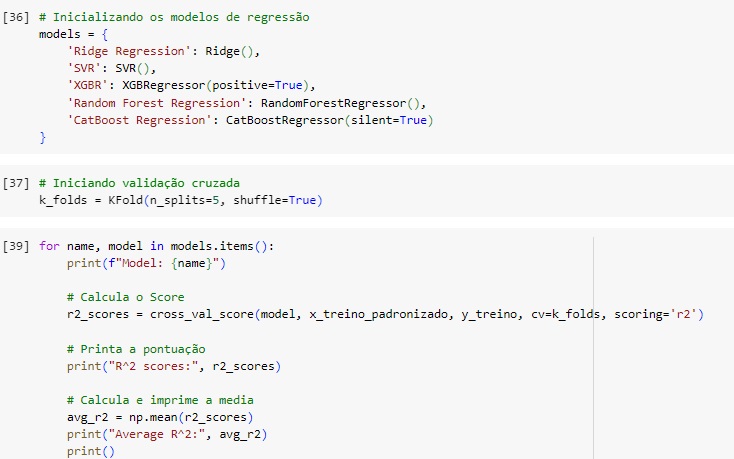
Agora vamos inicializar os modelos de machine learning que vamos testar, Ridge Regression, SVM, XGBR, Random Forest Regression e CatBooster Regression. Vamos analisar o score de cada um e treinaremos o nosso modelo com o que apresentar a melhor pontuação.
Também vamos utilizar a validação cruzada ou cross-validation, que é uma técnica fundamental em aprendizado de máquina e estatística usada para avaliar a capacidade de generalização de um modelo. Ela permite avaliar a performance do modelo de maneira mais robusta do que usando uma simples divisão de treino e teste. Para isto vamos usar o KFold().
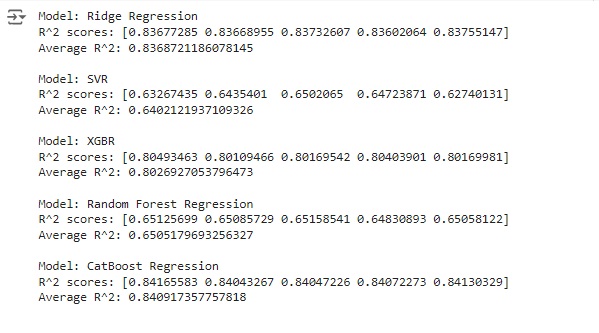
Fazendo os testes. Percebemos que o algoritmo CatBoost Regression nos deu a melhor pontuação com 0.84.
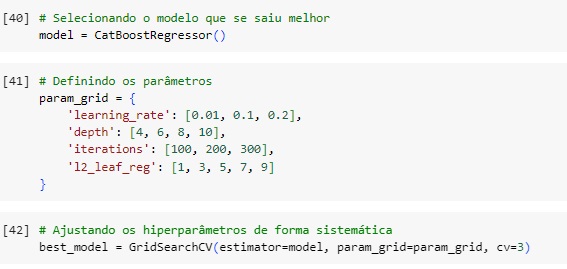
Vamos criar o modelo com o CatBoost Regression().
A variável param_grid define uma grade de parâmetros para realizar a busca pelos melhores hiperparâmetros do modelo CatBoost usando GridSearchCV. O objetivo é encontrar os melhores valores para learning_rate, depth, iterations e l2_leaf_reg que maximizem a performance do modelo.
learning_rate é a taxa de aprendizado, este parâmetro controla o tamanho dos passos que o modelo dá para minimizar a função de perda. Valores menores tornam o treinamento mais estável, mas podem exigir mais iterações. Valores maiores podem acelerar o treinamento, mas podem levar a um overfitting se forem muito grandes.
depth define a profundidade máxima das árvores individuais usadas no modelo. Árvores mais profundas podem capturar mais complexidade dos dados, mas também aumentam o risco de overfitting e aumentam o tempo de treinamento.
interations é o número de iterações de boosting a serem realizadas, ou seja, o número total de árvores a serem treinadas.
l2_leaf_reg é o parâmetro define a regularização L2 para as folhas das árvores. A regularização ajuda a evitar overfitting penalizando grandes pesos.
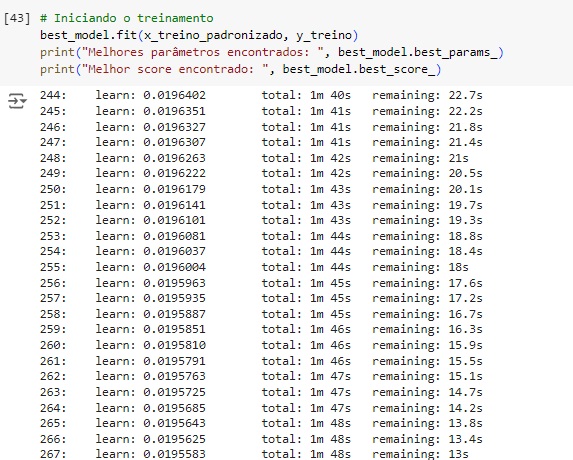
Em seguida na variável best_model vamos encontrar os melhores hiperparâmetros usando a técnica de GridSearchCV() que é uma ferramenta do scikit-learn que realiza uma busca exaustiva sobre uma grade de parâmetros especificada para encontrar a melhor combinação de hiperparâmetros para um modelo de machine learning. A busca é feita treinando o modelo com todas as combinações possíveis de parâmetros fornecidos e avaliando a performance usando validação cruzada. Foi passado como parâmetros estimator=model que é o modelo base que estamos ajustando, param_grid=param_grid é um dicionário onde as chaves são os nomes dos hiperparâmetros que desejamos ajustar e os valores são listas de valores que queremos testar para cada hiperparâmetro e CV=3 define o número de folds para a validação cruzada, neste caso significa que a validação cruzada será feita com 3 divisões (folds) dos dados, cada combinação de parâmetros será avaliada em 3 partes diferentes dos dados para garantir que a performance do modelo seja consistente.
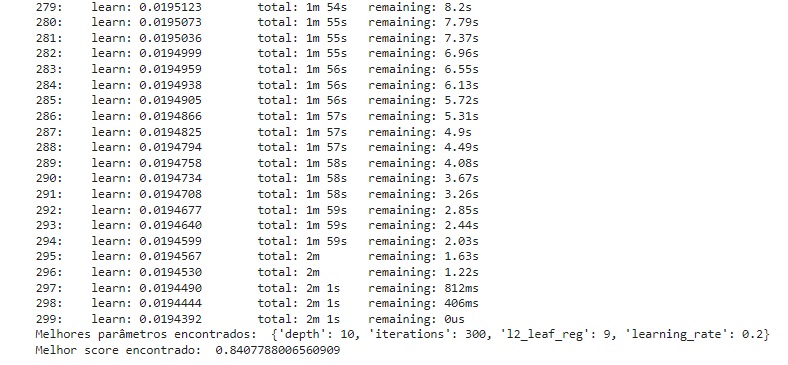
Logo após vamos iniciar o treinamento fit() com os melhores parâmetros encontrados. O modelo nos deu um score de 84.07%.
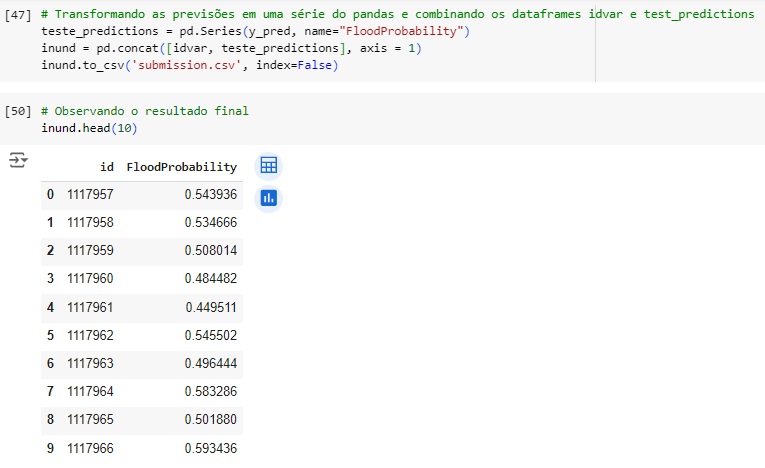
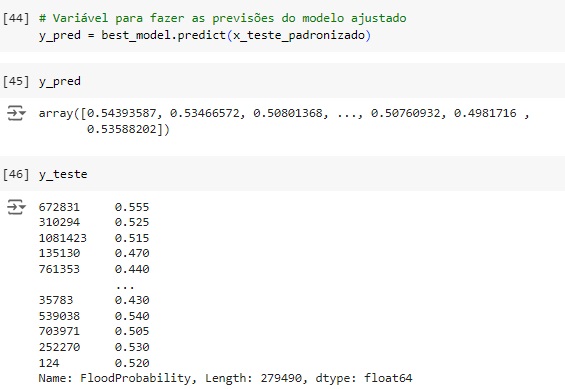
y_pred é o array ou lista contendo as previsões do modelo para os dados de teste. Comparando com os valores do dataset y_teste percebemos que os valores foram aceitáveis.
pd.Series(y_pred, x_teste) converte as previsões y_pred em uma Série do Pandas com o nome da coluna ‘FloodProbability’.
Por último concatenamos a variável idvar que separamos no inicio do projeto com a variável teste_predictions que contém as previsões feitas pelo nosso modelo, assim obtemos os resultados no novo dataset inund.