Previsão Para Adoção de Pets

Neste projeto vamos criar um modelo para prever a probabilidade de um animal de estimação ser adotado de um abrigo. Este conjunto de dados inclui informações detalhadas sobre animais de estimação disponíveis para adoção, cobrindo várias características e atributos. Os códigos foram desenvolvidos em linguagem Python na plataforma Google Colab. Vamos obter algumas informações sobre as variáveis:
- PetID: Identificador único para cada animal de estimação;
- PetType: Tipo de animal de estimação (cachorro, gato, pássaro, coelho);
- Breed: Raça específica do animal de estimação;
- AgeMonths: Idade do animal de estimação em meses;
- Color: Cor do animal de estimação;
- Size: Categoria de tamanho do animal de estimação (Pequeno, Médio, Grande);
- WeightKg: Peso do animal de estimação em quilogramas;
- Vaccinated: Situação vacinal do animal (0 – Não vacinado, 1 – Vacinado);
- HealthCondition: Condição de saúde do animal de estimação (0 – Saudável, 1 – Condição médica).;
- TimeInShelterDays: Duração em que o animal de estimação esteve no abrigo (dias);
- AdoptionFee: Taxa de adoção cobrada pelo animal de estimação (em dólares);
- PreviousOwner: Se o animal de estimação teve um dono anterior (0 – Não, 1 – Sim);
- AdoptionLikelihood: Probabilidade do animal de estimação ser adotado (0 – Improvável, 1 – Provável).
Vamos começar importando as bibliotecas.
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Carregando a base de dados e observando. Nossa variável alvo será ‘AdoptionLikelihood’.

Conferindo o shape, percebemos que o banco de dados possui 2007 linhas e 13 colunas.
Com a ajuda do comando info(), obtemos algumas informações e percebemos que existem variáveis do tipo object que mais adiante serão tratadas.
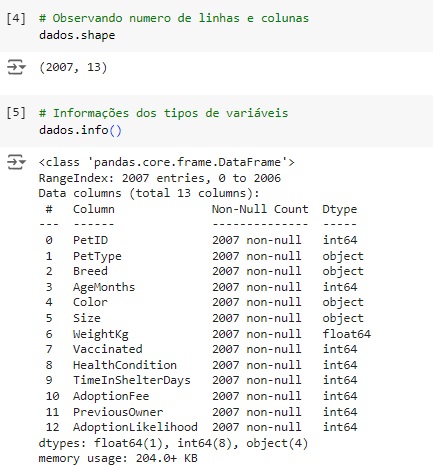
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão.
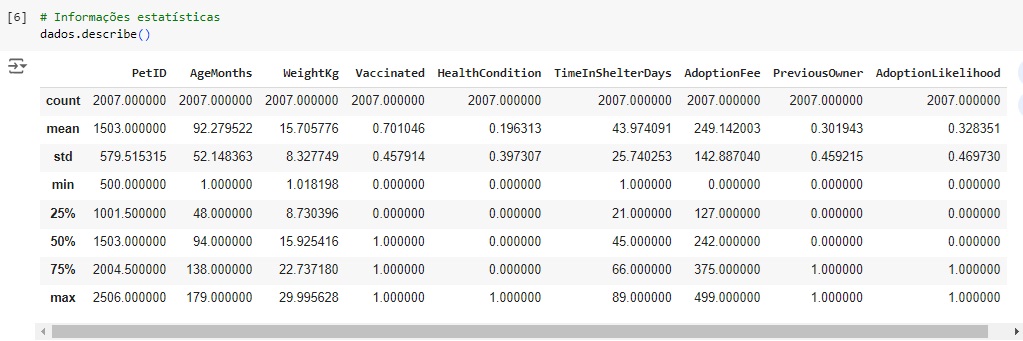
Verificando os valores nulos com o comando isnull().sum(). Podemos observar que não existem valores nulos no dataset e nem valores duplicados como dito pelo comando duplicated().
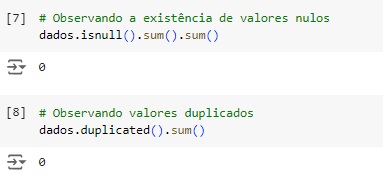
Agora vamos analisar a dispersão do dataset. Para que um dataset seja esparso aproximadamente metade das observações ou mais da metade delas deve ser zero. Percebemos que temos 0.19%, o que é um valor baixo para ser esparso. Através da função do scipy issparse() temos como resposta que o conjunto de dados não é esparso, consta como False.
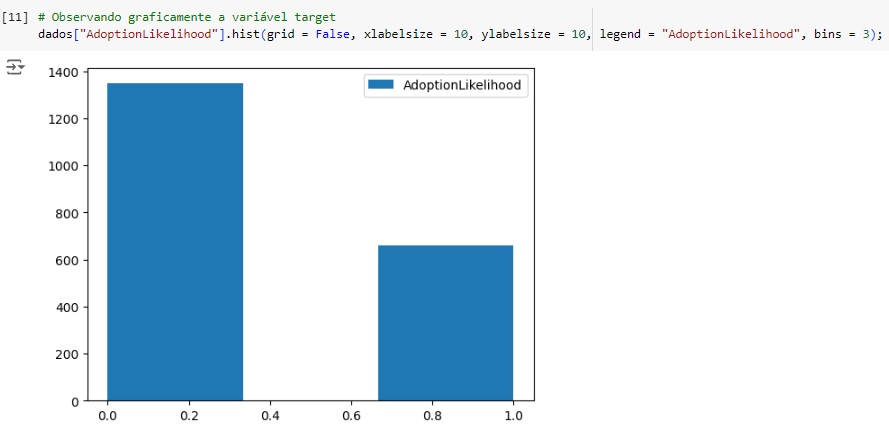
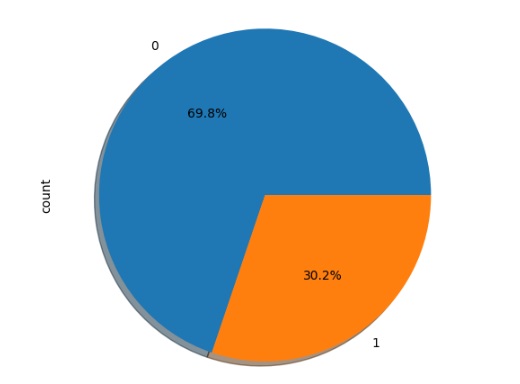
Analisando a variável target, podemos perceber que ela está muito desbalanceada, mais adiante iremos balancear.
Vamos apagar a variável ‘PetID’, pois não será necessária para nosso modelo de machine learning.

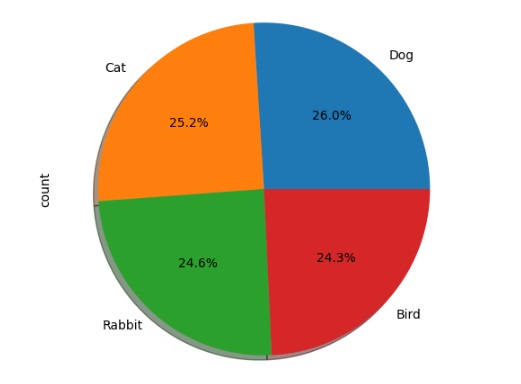





No gráfico abaixo podemos notar que os cachorros são os animais preferidos para adoção, seguido dos pássaros e dos gatos.

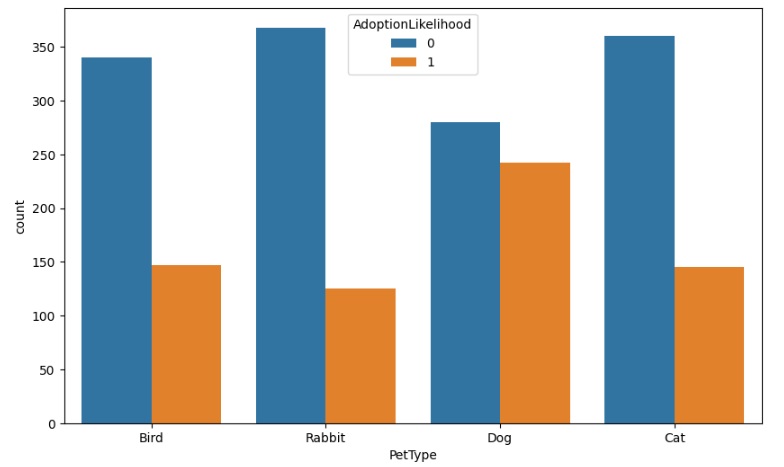
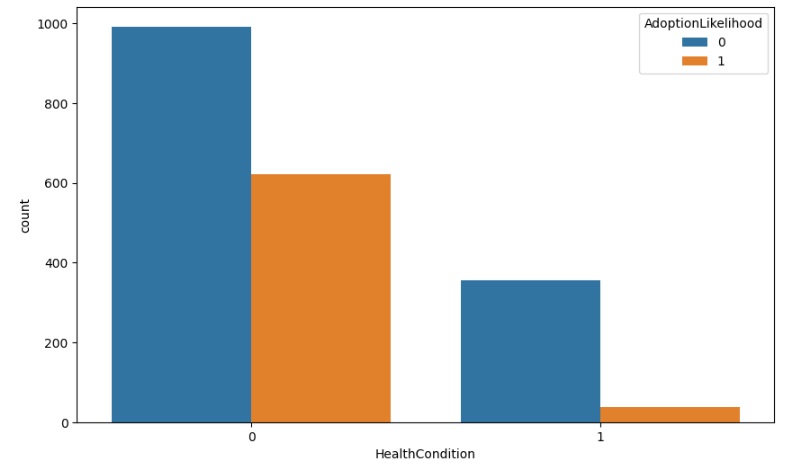
Agora percebemos que os pets sem doença são os preferidos para serem adotados.

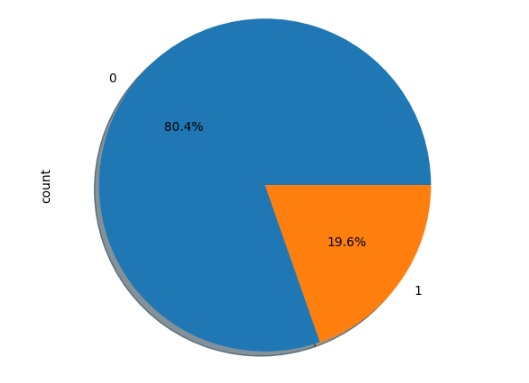
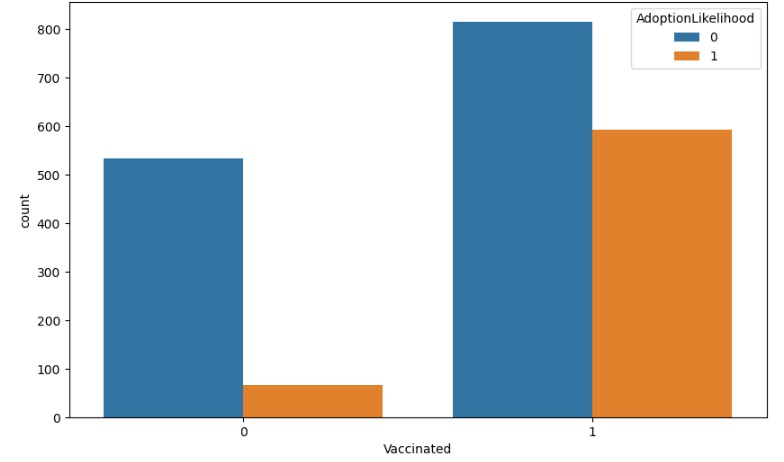
Os vacinados também estão na preferência para adoção.
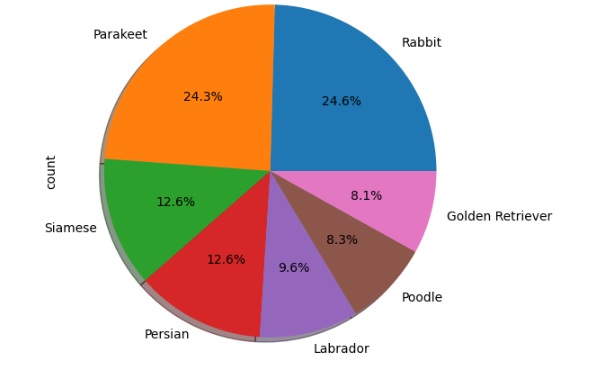
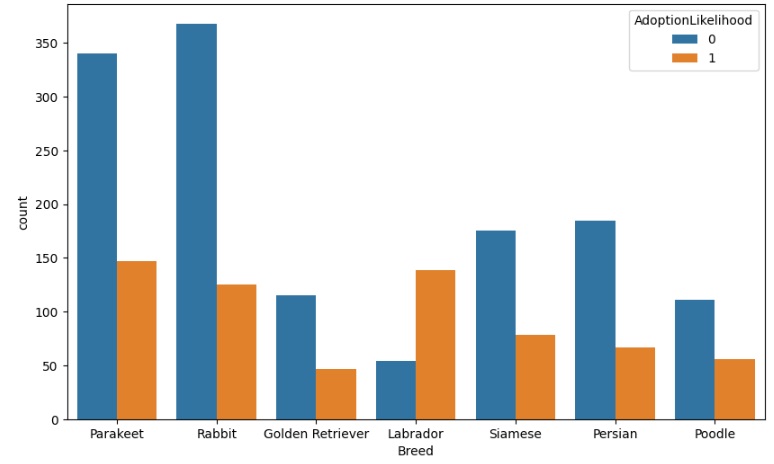
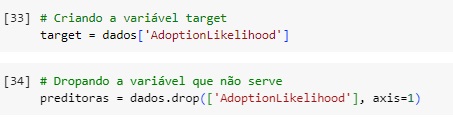
Percebemos que a raça de passarinho parakeet juntamente com a raça de cachorro labrador e os coelhos são os pets mais adotados.
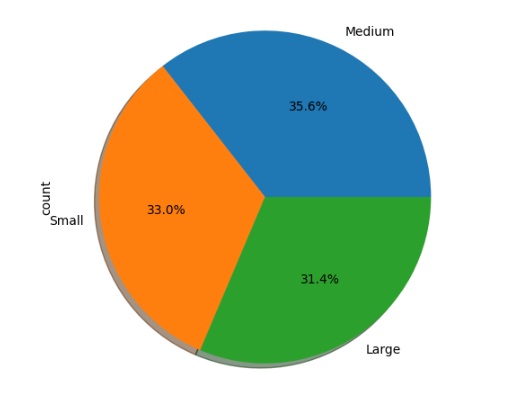
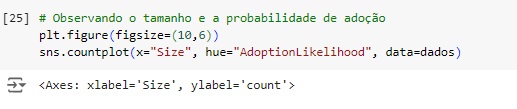
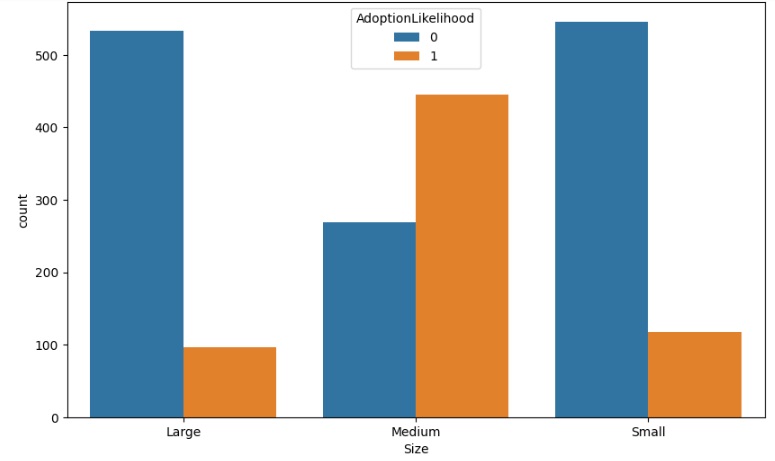
Também notamos que os pets com tamanho média são os mais adotados com muita diferença para os pequenos e grandes.
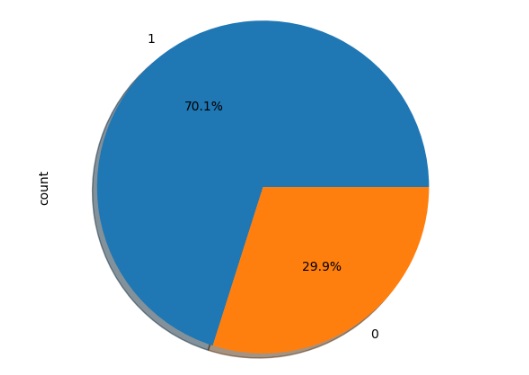
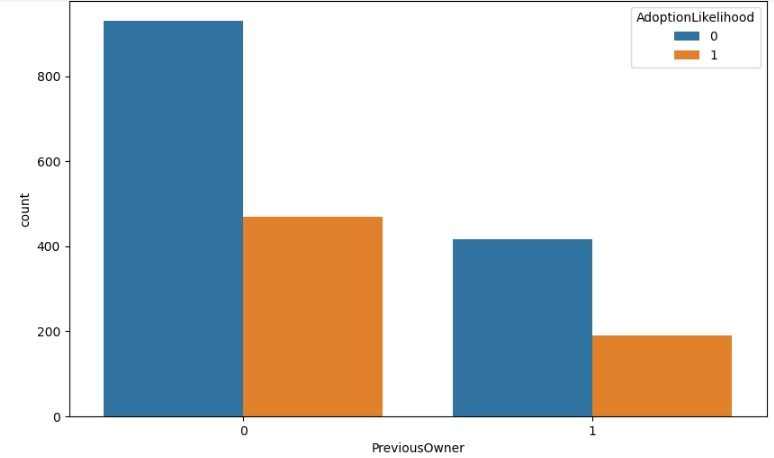
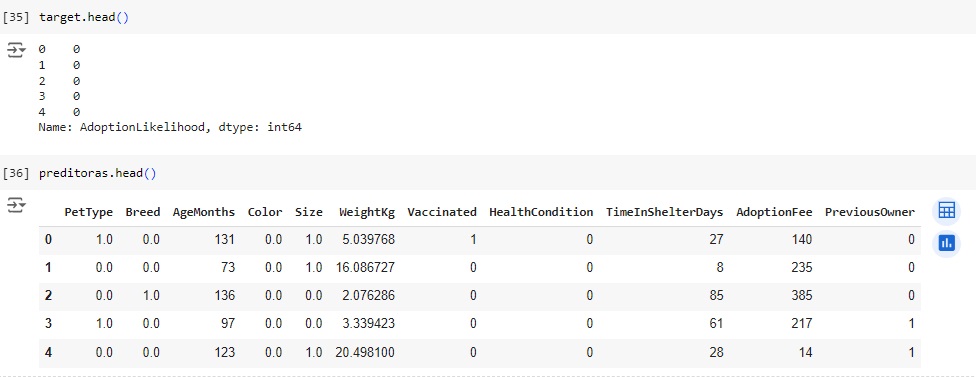
Os pets que não tiveram outro dono também têm a preferência das pessoas que adotam.

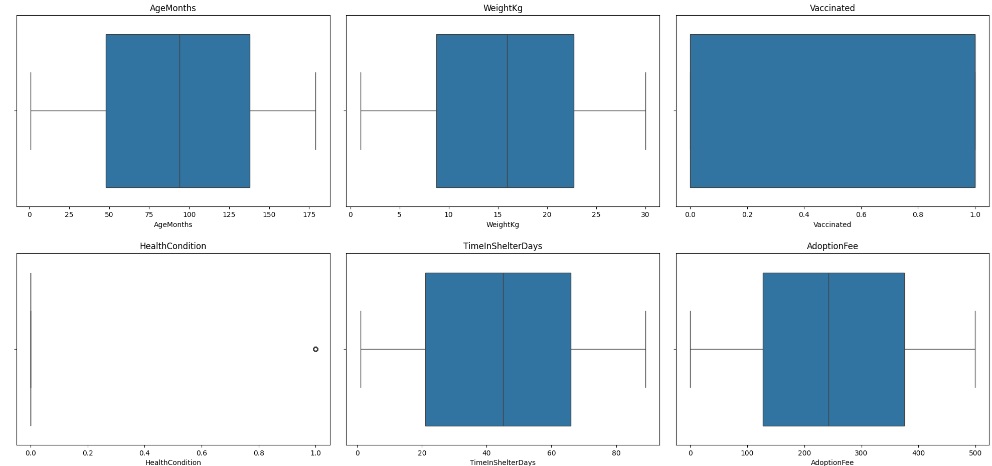
Vamos separar as variáveis numéricas para criar um boxplot para observar a existência de outliers. percebemos que não existe outliers no dataset.

Agora vamos transformar as variáveis categóricas em numéricas utilizando o OneHotEncoder através da biblioteca do scikit-learn OneHotEncoder(). Vamos passar o comando encoder.fit_transform() nas variáveis que queremos converter, menos na variável target. Em seguida verificamos se surgiu algum valor nulo e percebemos que não.

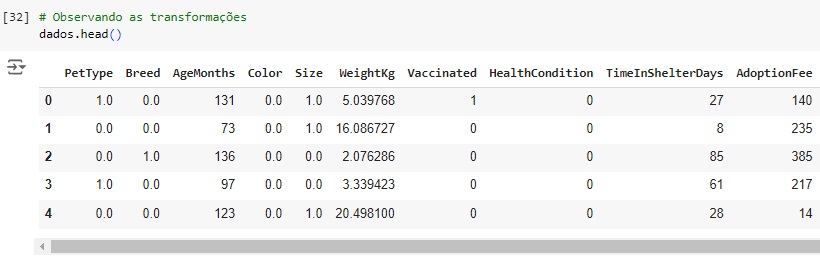
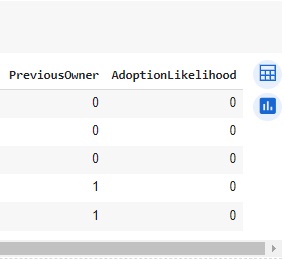
Observando as variáveis depois de separadas.

Agora vamos balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento em seguida usaremos o fit_resmple() que é o método balanceardor do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target
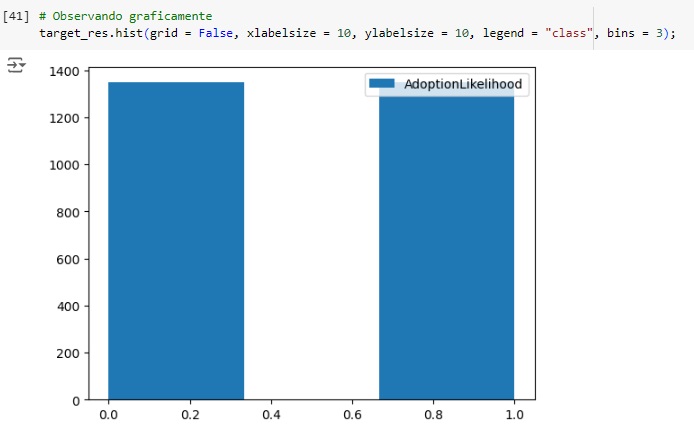
Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.
Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 75% dos dados para treinamento e 25% para teste.
Em seguida vamos padronizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o StandardScaler() e o fit_transform() para isso.

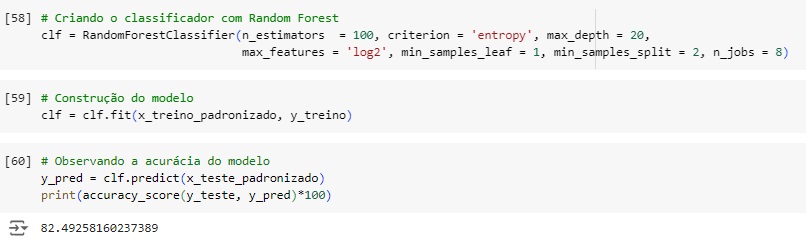
Criando o classificador com o algoritmo de machine learning RandomForestClassifier() com alguns hiperparâmetros para melhorar a acurácia do modelo, n_estimators = 100 é o número de árvores de decisão que terá o modelo. Em seguida criamos o modelo, passamos o classificador com o comando fit() e passamos como parâmetro as variáveis de treino normalizadas.
Olhando a acurácia do modelo, percebemos que tivemos 82,49% de acurácia.
Avaliando graficamente o peso de cada variável no modelo. Vamos cria a variável importances onde vamos passar os dados, o classificador o feature_importances_ que é um comando do próprio Random Forest, pois ele pega as variáveis com um peso maior ao longo do treinamento, no caso seriam as variáveis que tiveram um impacto maior para o resultado do modelo.
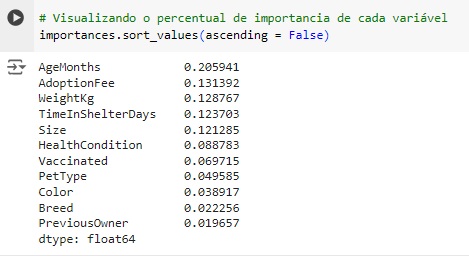
Notamos que a variável ‘AgeMonths’ que é a idade do pet tem disparada a maior relevância.

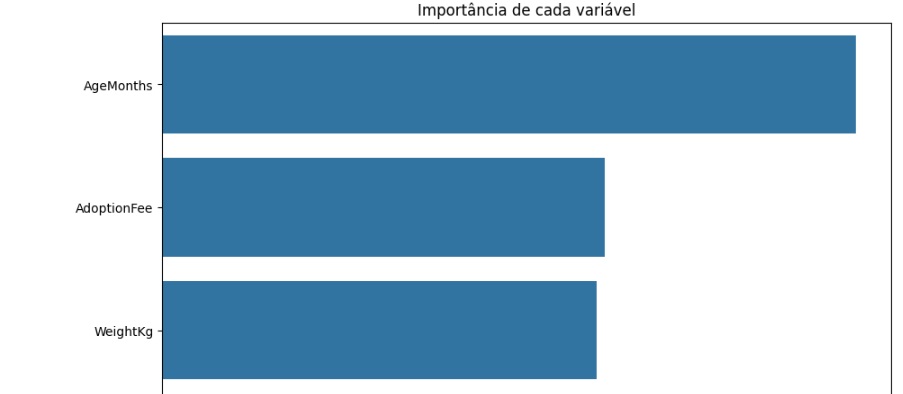


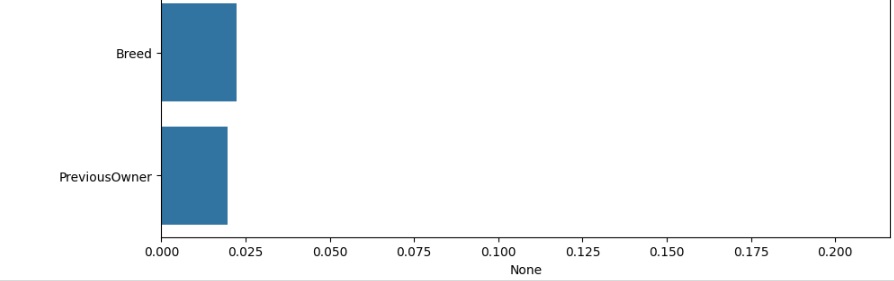
Aqui podemos visualizar em números.
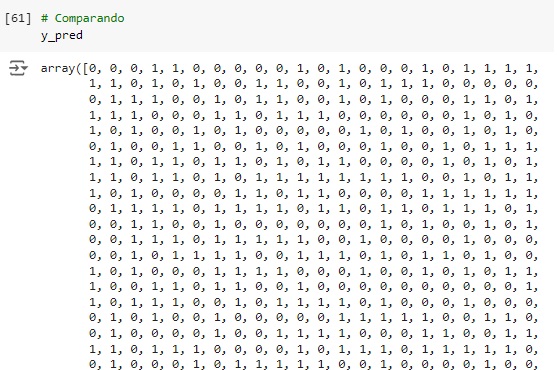
Comparando as previsões com os dados reais percebemos que o algoritmo errou os 2 primeiros, acertou o terceiro e o quarto…
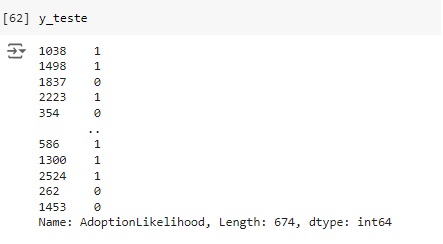
Através do classification report percebemos que o algoritmo consegue identificar corretamente 81% dos pets que não foram adotados (recall 0.81) e quando identifica um item desta classe a precisão é de 83% (precision 0.83). Para os pets que foram adotados o resultado do algoritmo foi de 84% das identificações corretas (recall 0.84) com 82% de certeza (precision 0.82).
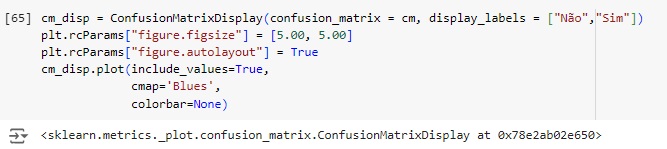
Vamos afazer uma análise a partir da matriz de confusão. Vamos importar a biblioteca sklearn.metrics import confusion_matrix.
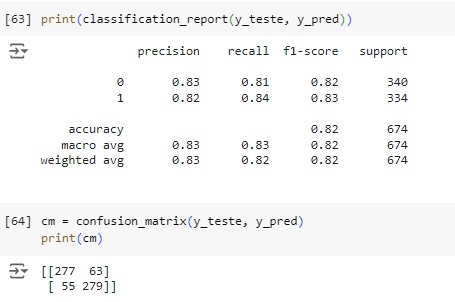
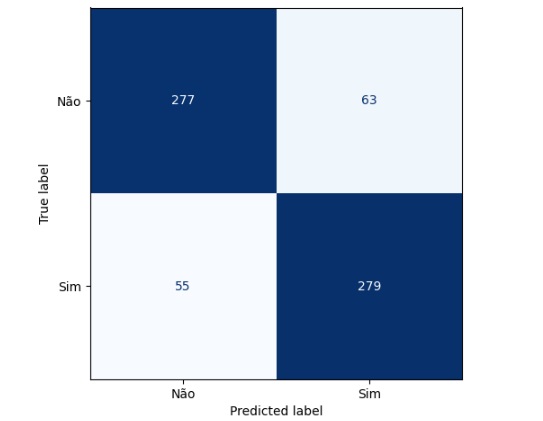
Plotando a matriz de confusão podemos perceber que 277 pets não foram adotados no banco de dados real e foi também o valor que o modelo previu, ou seja, é um verdadeiro positivo. No outro lado da matriz percebemos que segundo os dados reais 279 dos pets foram adotados, o mesmo valor que o modelo previu. Com isso conseguimos perceber que a diagonal que está azul mais escuro são os acertos do modelo.
Passando para a diagonal azul claro, percebemos que o banco de dados real tem 63 não foram adotados, mas o modelo previu que foram, no caso o modelo errou a previsão. Na outra diagonal percebemos que tem 55 pets foram adotados segundo o banco de dados real, mas o modelo previu que não foram.