Redes Neurais Para Previsão do Tempo

Neste projeto vamos ver a previsão do tempo, o nosso modelo de rede neural vai nos mostrar se “amanhã” vai chover ou não. O banco de dados contém cerca de 10 anos de informações meteorológicas diárias de várias localidades da Austrália. O código foi desenvolvido em linguagem Python na plataforma Google Colab. Vamos para a implementação:
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
Time – para funcionalidades referente ao tempo;
Smote – para o balanceamento dos dados;
TensorFlow – para criar o modelo de rede neural.
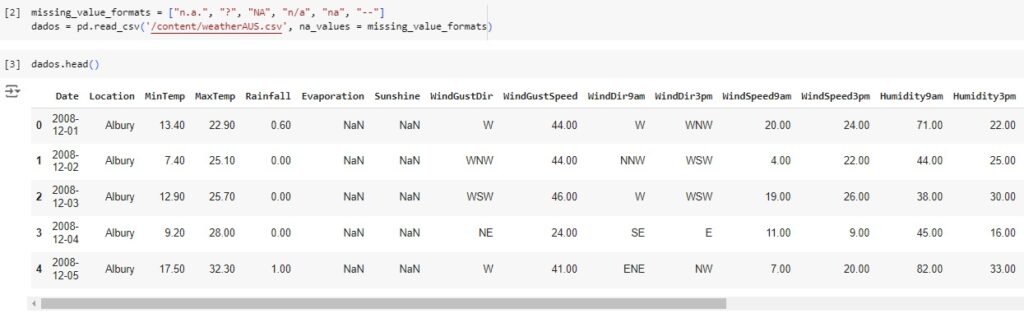
Agora vamos carregar a base de dados e observá-la.

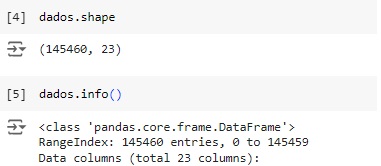
Observando o shape notamos que a base de dados possui 145460 linhas e 23 colunas.
Com a ajuda do comando info(), obtemos algumas informações informações e percebemos que existem variáveis do tipo object, que mais adiante serão tratadas.

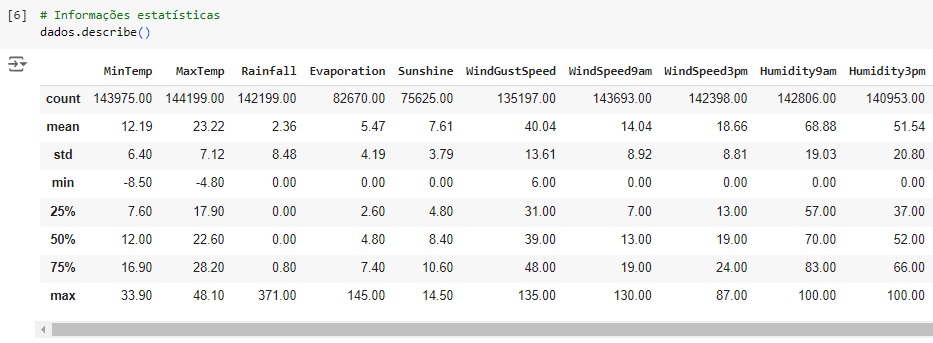
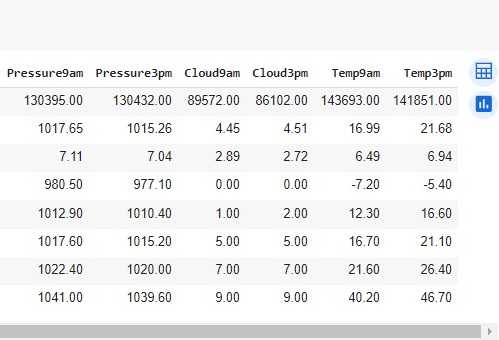
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão. Também podemos notar que os dados estão em diversas escalas, logo mais iremos normalizar estes dados.
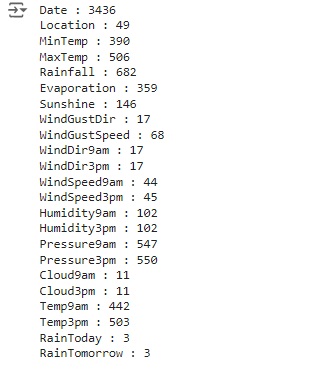
Verificando os valores nulos e contando os mesmos para cada variável utilizando o comando isnull().sum() e para o total de valores nulos o comando isnull().sum().sum(). Podemos observar que existem muitos valores nulos no banco de dados para serem tratados.



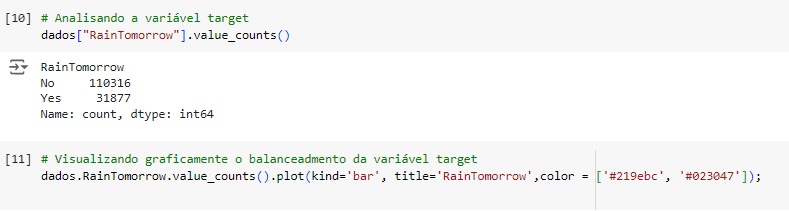
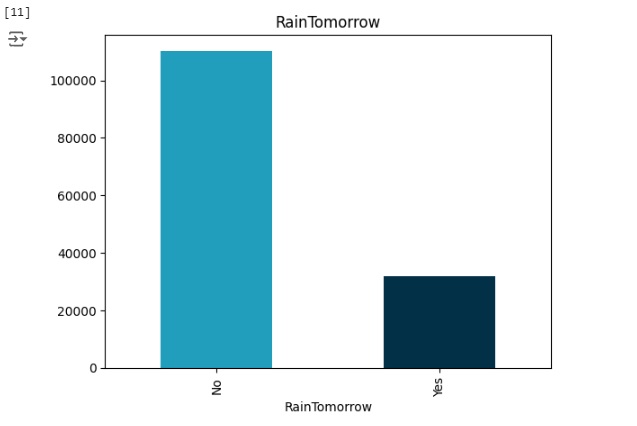
Vamos observar a nossa variável target ‘RainTomorrow’. Percebemos através do gráfico que ela esta bem desbalanceada, logo mais iremos cuidar disso.
Observando os valores nulos na variável target, notamos que existem 3267 valores ausentes. Como existem mais de 100.000 registros, vamos apagar os 3267 pois a quantidade é pequena e não fará diferença quando aplicarmos a rede neural. Em seguida observamos que não temos valores duplicados no dataset.
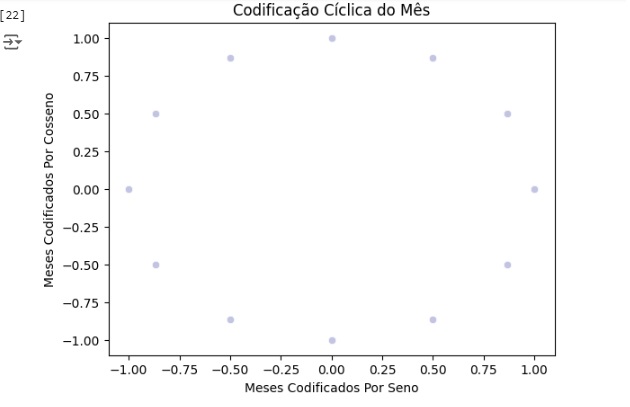
Agora vamos codificar as datas de uma maneira mais adequada para o projeto, ou seja, em dias e meses em um recurso cíclico contínuo. Data e hora são inerentemente cíclicos e para que a rede neural saiba que um recurso é cíclico, vamos dividir em subseções periódicas, ou seja, anos, meses e dias. Para cada subseção vamos criar dois novos recursos, derivando uma transformação de seno e uma de cosseno.
Observando as modificações e as novas variáveis criadas.
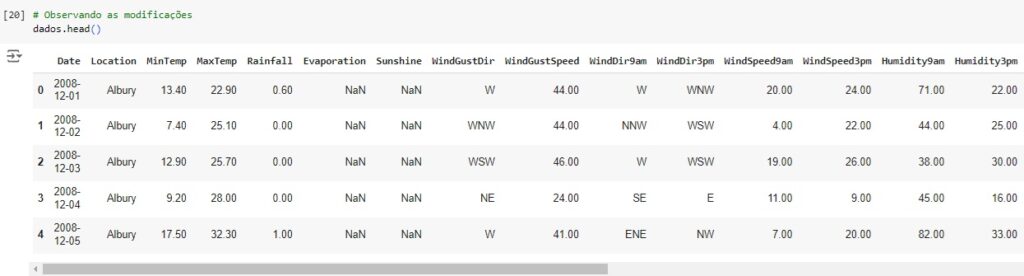
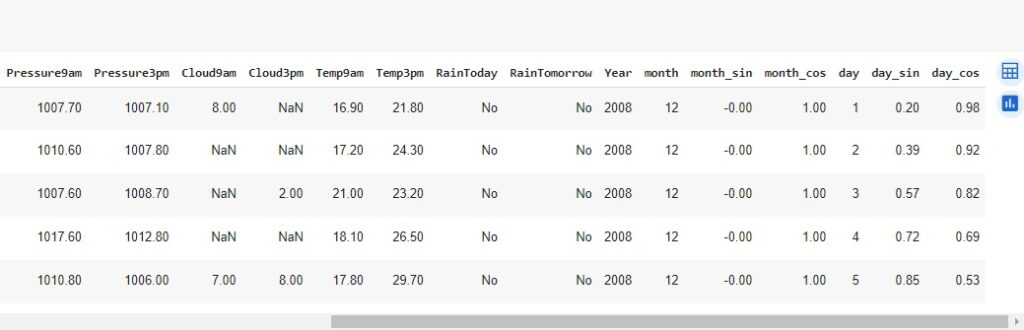



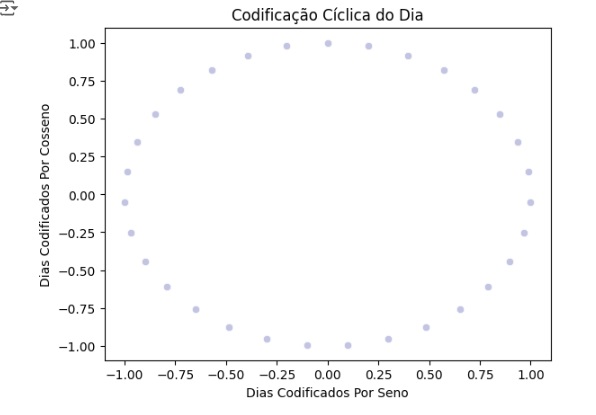
Observamos o shape novamente para ver a mudança no dataset que agora possui 142193 linhas e 30 colunas.
Agora vamos calcular os valores ausente em cada variável, se existir variável com 70% dos valores ausentes iremos dropar(apagar) a coluna, caso contrário faremos o tratamento dos dados.

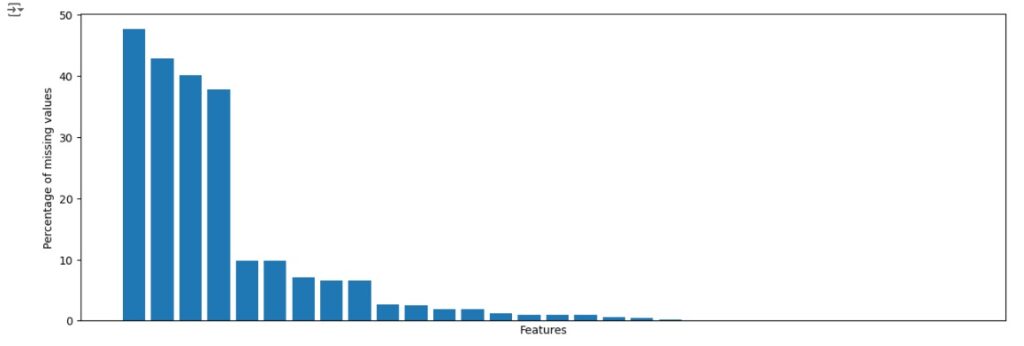
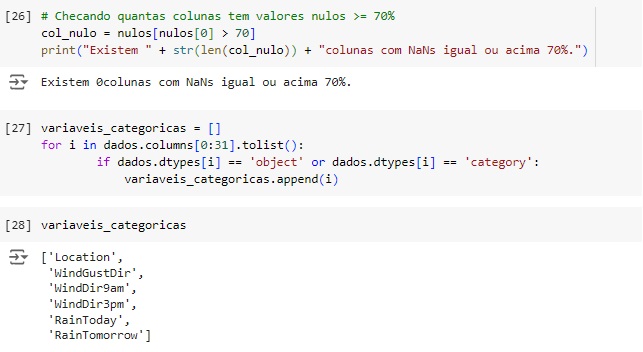
Percebemos que não existem colunas com valores ausentes igual ou acima de 70%, portanto iremos tratar os dados. Vamos começar carregando as variáveis categóricas.
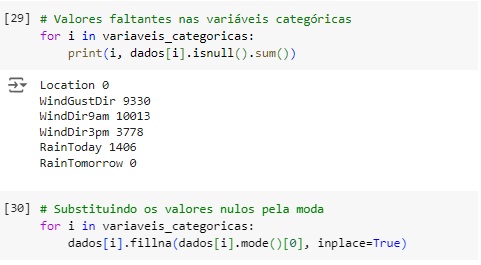
Vamos observar os valores faltantes em cada variável categórica e vamos substituí-los pela moda.
Vamos confirmar se as correções foram feitas e em seguida vamos carregar as variáveis numéricas.

Observando os valores nulos nas variáveis numéricas.

Vamos substituir pela mediana e conferir as mudanças.
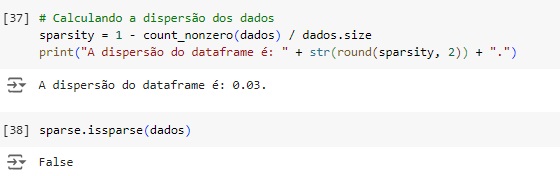
Vamos analisar a dispersão do dataset. Para que um dataset seja esparso aproximadamente metade das observações ou mais da metade delas deve ser zero. Percebemos que temos 30% que é um valor elevado, mas ainda longe dos 50%. Através da função do scipy issparse() temos como resposta que o conjunto de dados não é esparso, consta como False.
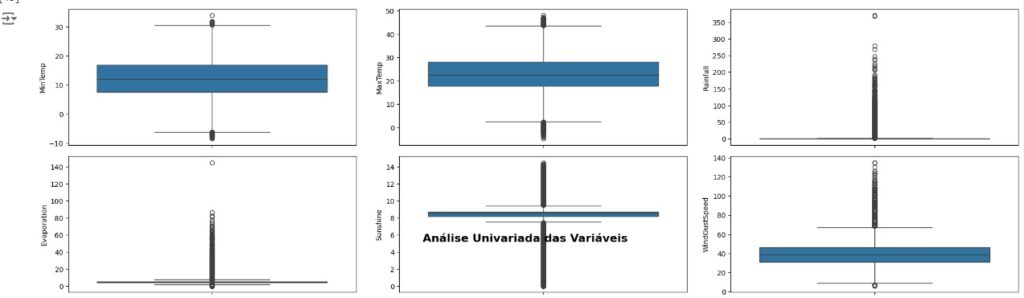
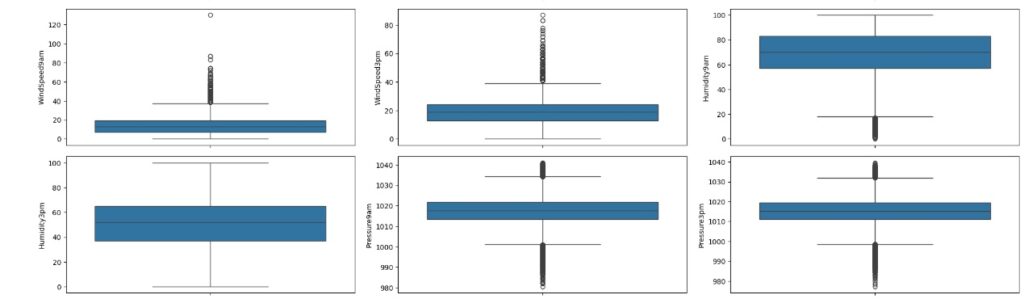
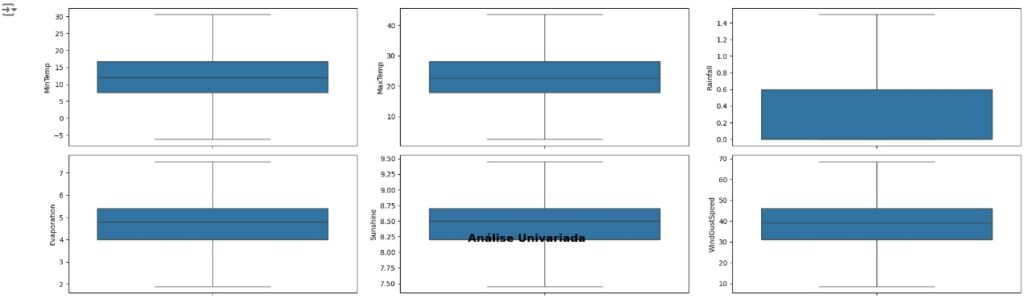
Vamos carregas as variáveis numéricas para o boxplot e analisarmos se existem outliers. Através dos gráfico notamos que existem muitos.



Vamos resolver o problema dos outliers utilizando o método Tukey ou Boxplot onde iremos definir os limites inferior e superior a partir do interquartil (IQR) e dos primeiros (Q1) e terceiros (Q3) quartis.
Quartis são separatrizes que dividem um conjunto de dados em 4 partes iguais. O objetivo das separatrizes é proporcionar uma melhor ideia da dispersão do dataset, principalmente da simetria ou assimetria da distribuição.
O limite inferior é definido pelo primeiro quartil menos o produto entre o valor 1.5 e o interquartil.
Linf = Q1 – (1.5 * IQR)
O limite superior é definido pelo terceiro quartil mais o produto entre o valor 1.5 e o interquartil.
Lsup = Q3 + (1.5 * IQR)
Em seguida vamos observar se os outliers foram removidos através do boxplot.
Esta função serve para substituir os outliers, onde valores acima do limite superior são substituídos pelo próprio limite superior e valores abaixo do limite inferior são substituídos pelo próprio limite inferior.



Agora vamos transformar as variáveis categóricas em numéricas utilizando o LabelEncoder através da biblioteca do scikit-learn LabelEncoder(). Vamos passar o comando lb.fit_transform() nas variáveis que queremos converter. Em seguida verificamos se a conversão foi feita com sucesso, e notamos que sim, todas as variáveis são numéricas agora.

Vamos separar a variável target das variáveis preditoras e também excluir as variáveis que não iremos utilizar no nosso modelo.
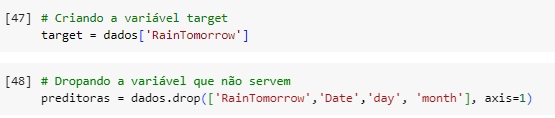
Observando as novas variáveis, target e preditoras.

Observando novamente o desbalanceamento da variável target, vamos corrigir em seguida.


Agora vamos balancear os dados com o SMOTE(), o comando vai avaliar o banco de dados e vai criar novos dados para igualar as variáveis target. Em seguida vamos aplicar o balanceador, vamos criar duas novas variáveis preditoras_res e target_res que serão os resultados do balanceamento, em seguida usaremos o fit_resmple() que é o método balanceador do SMOTE(), e passamos os parâmetros que queremos balancear, no caso preditoras e target.
Visualizando através do gráfico, percebemos que a variável target foi balanceada corretamente.

Usando o train_test_split() vamos dividir a base de dados em treino e teste, sendo 75% dos dados para treinamento e 25% para teste.
Em seguida vamos normalizar os dados das variáveis preditoras para colocá-los na mesma escala, vamos utilizar o MinMaxScaler() e o fit_transform() para isso.

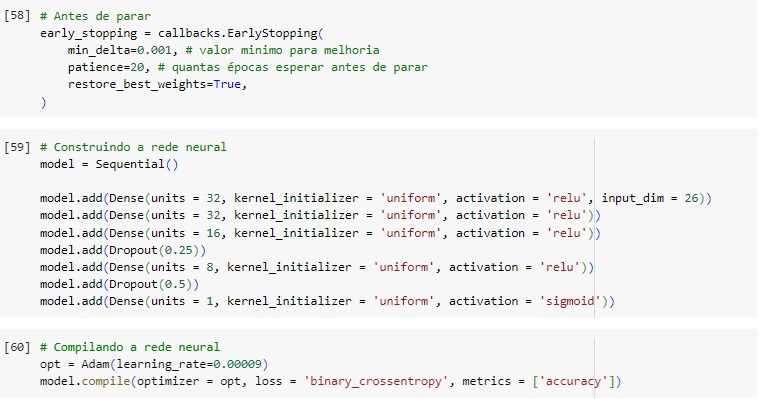
Com a classe do TensorFlow callbacks.EarlyStopping(), vamos monitorar a função de perda durante o treinamento do modelo.
Vamos criar a nossa rede neural com 5 camadas densas, 32 é o número de filtros, relu é a função de ativação, dropout para evitar o overfitting e melhorar a generalização do modelo, input_dim = 26 são as entradas. Na camada de saída usaremos a função sigmoid pois nosso projeto é uma classificação binária.
Em seguida vamos compilar a rede neural com o otimizador Adam e um learning_rate = 0.00009 que é a taxa de aprendizagem.
Agora vamos treinar a rede neural por 200 épocas.
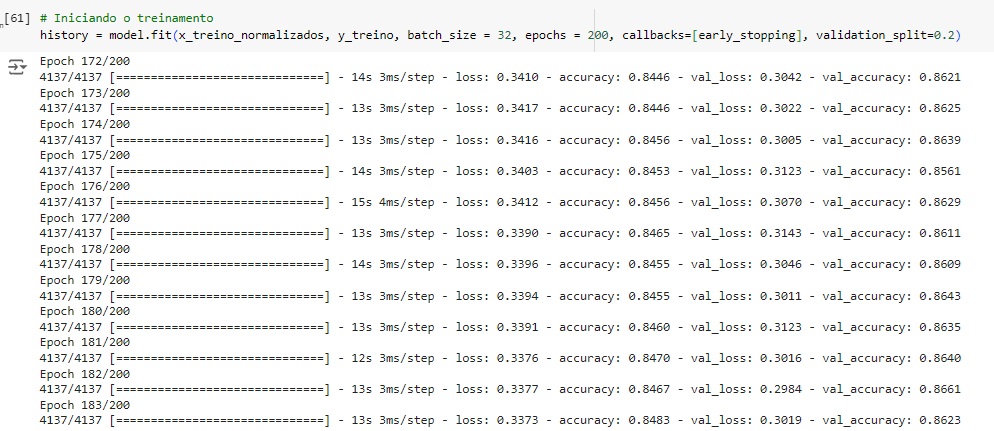
Criando a variável y_pred que são as previsões feitas pela rede neural e vamos testar. Percebemos que os 3 primeiros a rede neural acertou, consta como False e na variável y_teste com os valores originais consta como 0.
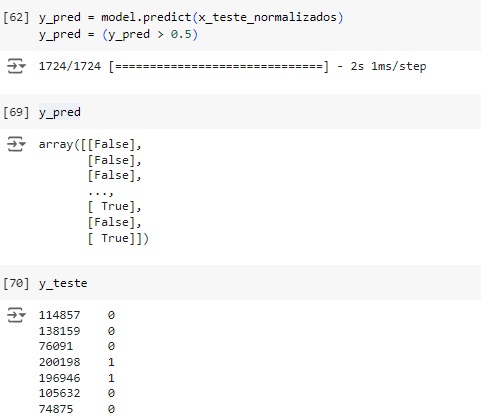
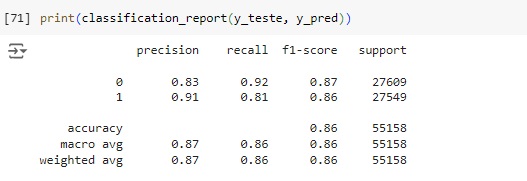
Através do classification report percebemos que o algoritmo consegue identificar corretamente que 92% não vai chover (recall 0.92) e quando identifica esta classe a precisão é de 83% (precision 0.83). Para os dias que vai chover o resultado do algoritmo foi de 81% das identificações corretas (recall 0.81) com 91% de certeza (precision 0.91).
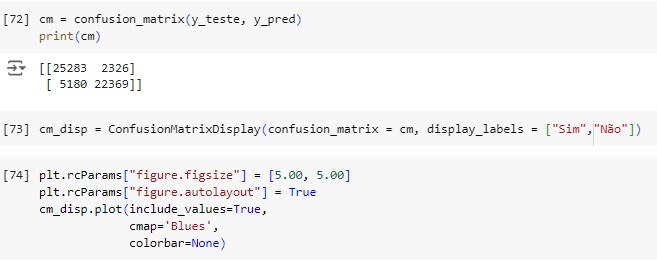
Vamos afazer uma análise a partir da matriz de confusão
Plotando a matriz de confusão podemos perceber que 25283 dias vai chover no banco de dados real e foi também o valor que o modelo previu, ou seja, é um verdadeiro positivo. No outro lado da matriz percebemos que segundo os dados reais 22369 dias não vai chover, o mesmo valor que o modelo previu, ou seja é um verdadeiro negativo. Com isso conseguimos perceber que a diagonal que está azul mais escuro são os acertos do modelo.
Passando para a diagonal azul claro, percebemos que o banco de dados real tem 2326 não vai chover, mas o modelo previu que vai, ou seja, é um falso positivo, no caso o modelo errou a previsão. Na outra diagonal percebemos que tem 5180 dias que vai chover, mas o modelo previu que não vai chover.