Reduzindo o Tempo na Bancada de Testes da Mercedes-Benz

Neste projeto vamos criar um modelo para otimizar a velocidade do sistema de testes da Mercedes-Benz. O objetivo é reduzir o tempo que os carros passam na bancada de testes. Por uma questão de privacidade dos dados a empresa não divulgou os nomes das variáveis, apenas da nossa variável target que será ‘y’. Vamos carregar 2 bases de dados para este projeto e vamos tratá-las. Os códigos foram desenvolvidos na linguagem de programação Python na plataforma Google Colab. Vamos para a implementação:
Vamos começar importando as bibliotecas.
Warnings – para avisos de alertas;
Pandas – para análise e manipulação de dados;
Numpy – para realizar operações em arrays multidimensionais;
Seaborn – para visualizar gráficos;
Matplotlib – para visualizações mais interativas;
Scikit-learn – para aplicar modelos de machine learning;
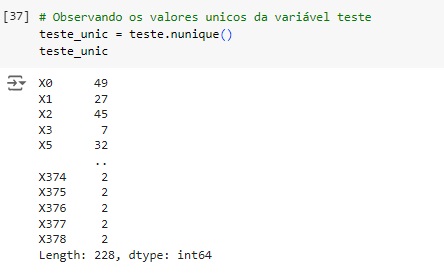
Em seguida vamos carregar os dados da variável de treino e observá-los. Utilizando o comando shape percebemos que a base de dados possui 4209 linhas e 378 colunas. Notamos que a maioria das colunas possui valores 0 e 1.

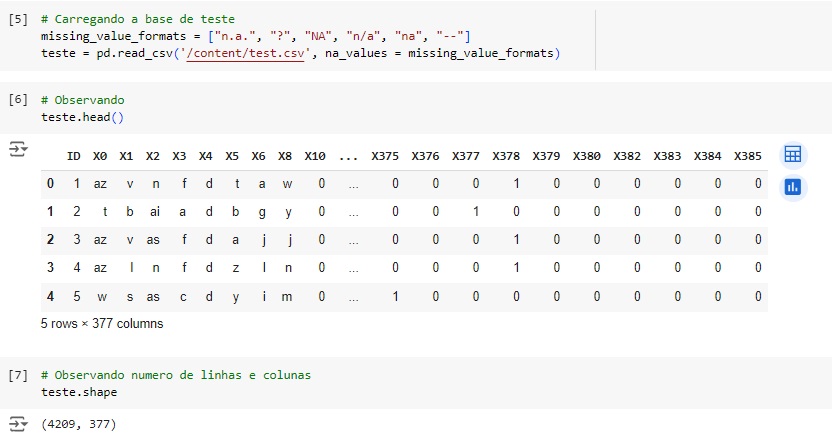
Agora vamos carregar os dados da variável de teste e observá-los. Utilizando o comando shape percebemos que a base de dados possui 4209 linhas e 377 colunas. Notamos que a maioria das colunas possui valores 0 e 1.
Vamos retirar das 2 bases de dados a coluna ‘ID’, pois não será útil para nosso modelo, mas vamos salvá-la na variável idvar.
Com a ajuda do comando info(), obtemos algumas informações informações e percebemos que existem variáveis do tipo object, que mais adiante serão tratadas.
Agora, com a ajuda do describe(), vamos observar informações estatísticas, como média, mediana e desvio padrão.

Verificando o total de valores nulos o comando isnull().sum().sum(). Podemos observar que não existem valores faltantes em nenhuma das duas base de dados.
Como os recursos numéricos são binários, o conceito de outliers não se aplica. Portando vamos apenas analisar a variável de destino para observar se existe valores discrepantes.
Vamos criar a função ‘check_ouliers’ para identificar outliers

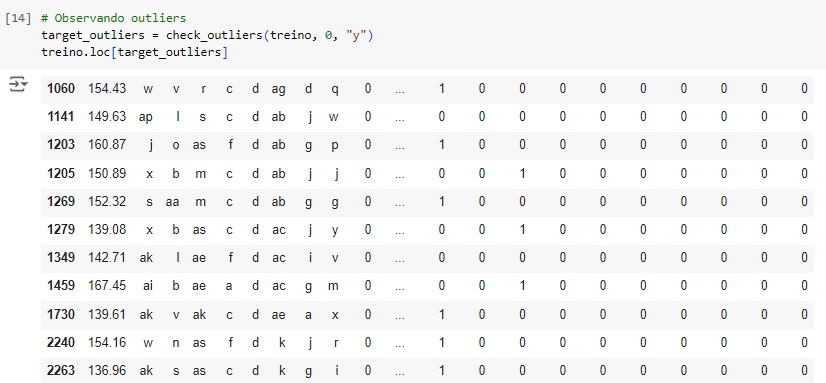

Existem 50 valores discrepantes na variável alvo, o que corresponde a 1% do total de dados, portando vamos excluí-los com o comando drop().

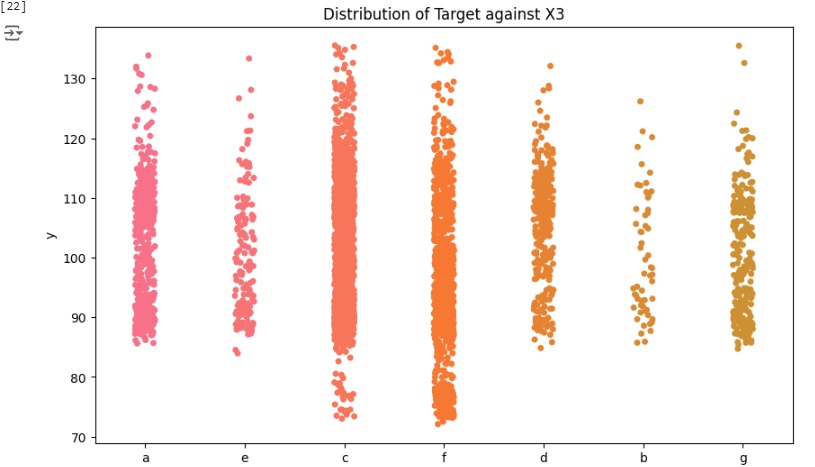
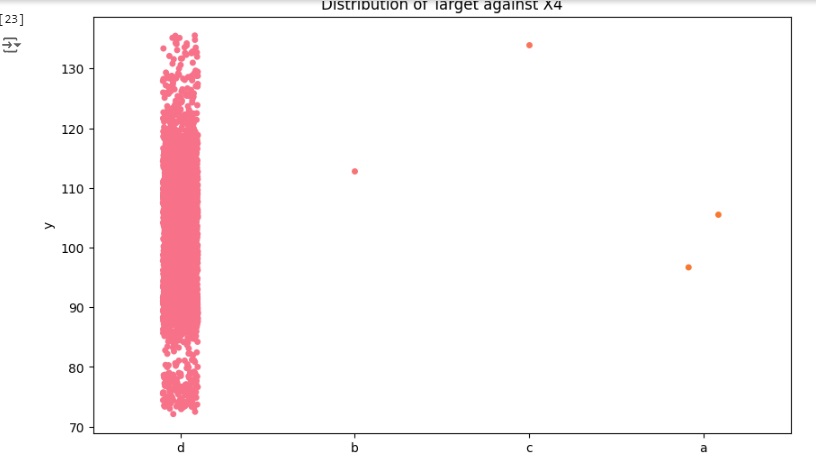
Agora vamos carregar as variáveis categóricas e observar graficamente sua distribuição.



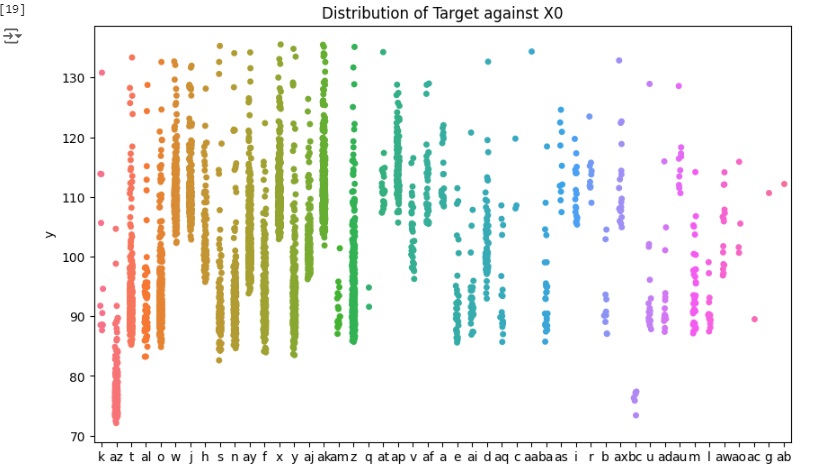

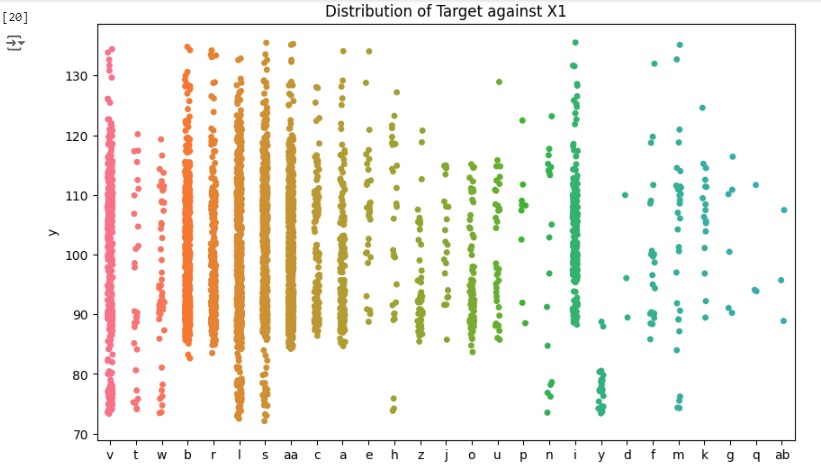



Observamos que a distribuição da variável ‘X4’ está quase toda concentrada na categoria ‘d’, portanto é um recurso que não vai fornecer muitos insights sobre os dados, então vamos excluir a variável logo mais.


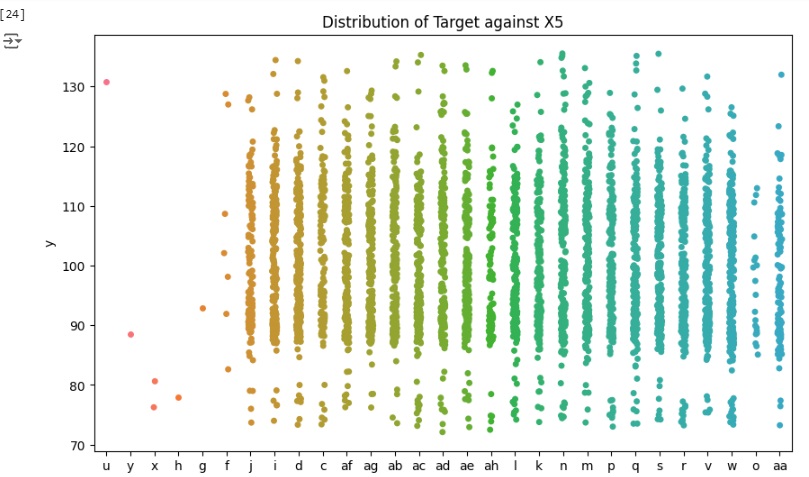

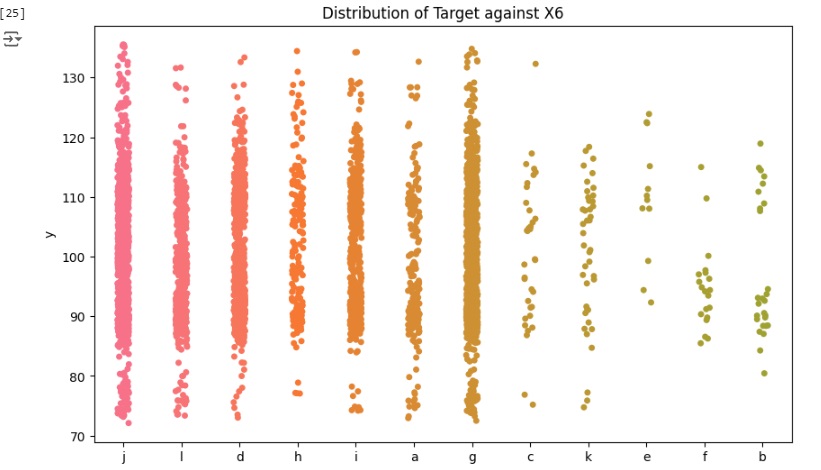

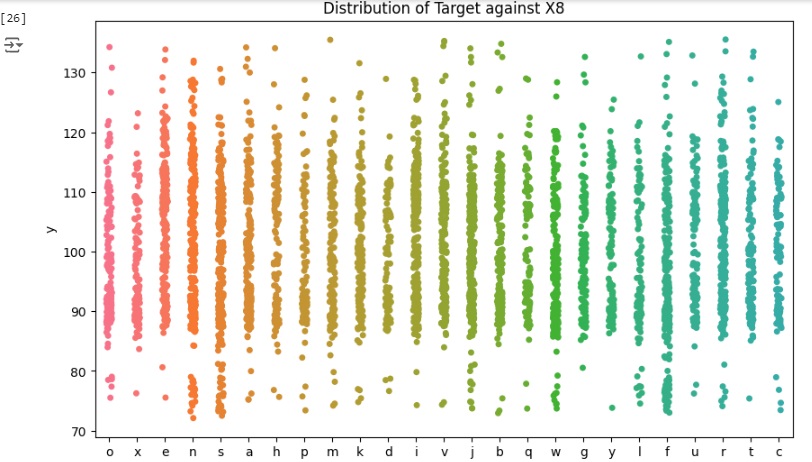

Podemos notar que a maioria das variáveis possuem apenas um valor dominante, devido a isso não oferecem variabilidade e informações ao modelo podendo causar o overfitting que é o ajuste excessivo dos dados. Portanto estas variáveis serão removidas.

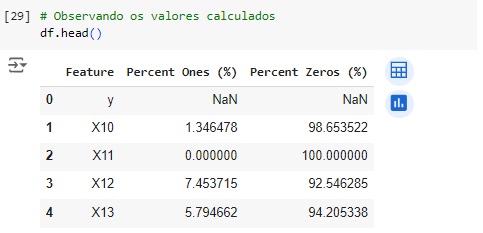
Vamos encontrar as colunas que possuem 99% valores 0 e 1.

Vamos apagá-las e observar o shape.

Vamos carregar novamente as variáveis categóricas para One-Hot-Encoder()
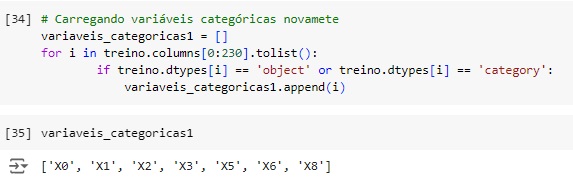

Unindo os 2 bancos de dados em uma nova variável chamada mercedes, para isto vamos usar o comando concat(), em seguida vamos carregar as variáveis categóricas e transformar para numérica. Logo após vamos dividir novamente o novo banco de dados em treino e teste.
Observando a variável de treino.

Observando a variável de teste.
Separando a base de treino e teste da base treino_enc e dropando a variável alvo ‘y’.

Observando a base de treino sem a variável alvo ‘y’.

Observando y_treino com apenas a variável alvo.

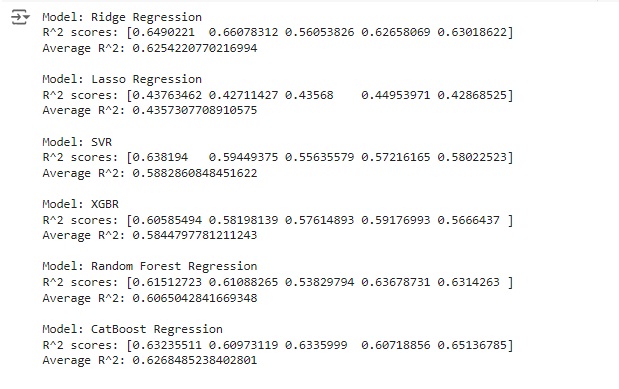
Agora vamos inicializar os modelos de machine learning que vamos testar, Ridge Regression, Lasso Regression, SVM, XGBR, Random Forest Regression e CatBooster Regression. Vamos analisar o score de cada um e treinaremos o nosso modelo com o que apresentar a melhor pontuação.
Também vamos utilizar a validação cruzada ou cross-validation, que é uma técnica fundamental em aprendizado de máquina e estatística usada para avaliar a capacidade de generalização de um modelo. Ela permite avaliar a performance do modelo de maneira mais robusta do que usando uma simples divisão de treino e teste. Para isto vamos usar o KFold().

Fazendo os testes. Percebemos que o algoritmo Ridge Regression nos deu a melhor pontuação com 0.66.

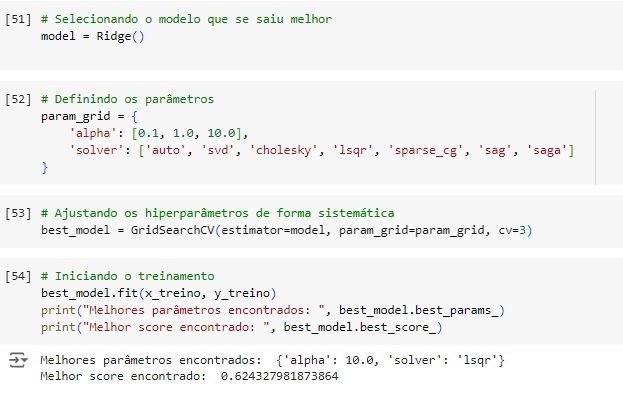
Vamos criar o modelo com o Ridge().
A variável param_grid define uma grade de parâmetros para realizar a busca pelos melhores hiperparâmetros do modelo Ridge usando GridSearchCV. O objetivo é encontrar os melhores valores para alpha e solver que maximizem a performance do modelo.
Alpha é o parâmetro de regularização para o modelo, pois controla a força da regularização. Valores mais altos aumentam a regularização e valores mais baixos a reduzem. Os valores fornecidos serão testados para encontrar qual proporciona a melhor performance.
Solver especifica o algoritmo usado para resolver a equação de regularização Ridge:
- Auto escolhe automaticamente o melhor solver com base nas características dos dados.
- SVD usa a decomposição em valores singulares (SVD) para resolver a equação. É eficiente para problemas com muitas features.
- Choleski usa a decomposição de Cholesky, eficiente para problemas pequenos.
- Isqr é um método iterativo adequado para problemas de grande escala.
- Sparce_cg é um método de gradiente conjugado, adequado para grandes problemas esparsos.
- Sag usa o algoritmo de gradiente estocástico com média (Stochastic Average Gradient), eficiente para problemas de grande escala.
- Saga é Uma variação do Sag que suporta L1 e L2.
Em seguida na variável best_model vamos encontrar os melhores hiperparâmetros usando a técnica de GridSearchCV() que é uma ferramenta do scikit-learn que realiza uma busca exaustiva sobre uma grade de parâmetros especificada para encontrar a melhor combinação de hiperparâmetros para um modelo de machine learning. A busca é feita treinando o modelo com todas as combinações possíveis de parâmetros fornecidos e avaliando a performance usando validação cruzada. Foi passado como parâmetros estimator=model que é o modelo base que estamos ajustando, param_grid=param_grid é um dicionário onde as chaves são os nomes dos hiperparâmetros que desejamos ajustar e os valores são listas de valores que queremos testar para cada hiperparâmetro e CV=3 define o número de folds para a validação cruzada, neste caso significa que a validação cruzada será feita com 3 divisões (folds) dos dados, cada combinação de parâmetros será avaliada em 3 partes diferentes dos dados para garantir que a performance do modelo seja consistente.
Logo após vamos iniciar o treinamento fit() com os melhores parâmetros encontrados. O modelo nos deu um score de 62.43%.
y_pred é o array ou lista contendo as previsões do modelo para os dados de teste.
pd.Series(y_pred, x_teste) converte as previsões y_pred em uma Série do Pandas com o nome da coluna ‘y’.
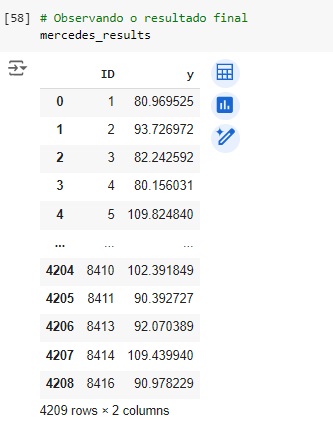
Por último concatenamos a variável idvar que separamos no inicio do projeto com a variável teste_predictions que contém as previsões feitas pelo nosso modelo, assim obtemos os resultados no novo dataset mercedes_results.